
Rationalisierung des Datenabrufs von Tulip zu Snowflake für umfassendere Analysen und Integrationsmöglichkeiten
Zweck
Dieser Leitfaden zeigt Schritt für Schritt, wie man Daten aus Tulip-Tabellen über Microsoft Fabric (Azure Data Factory) in Snowflake abruft.
Eine Übersicht über die Architektur ist unten aufgeführt: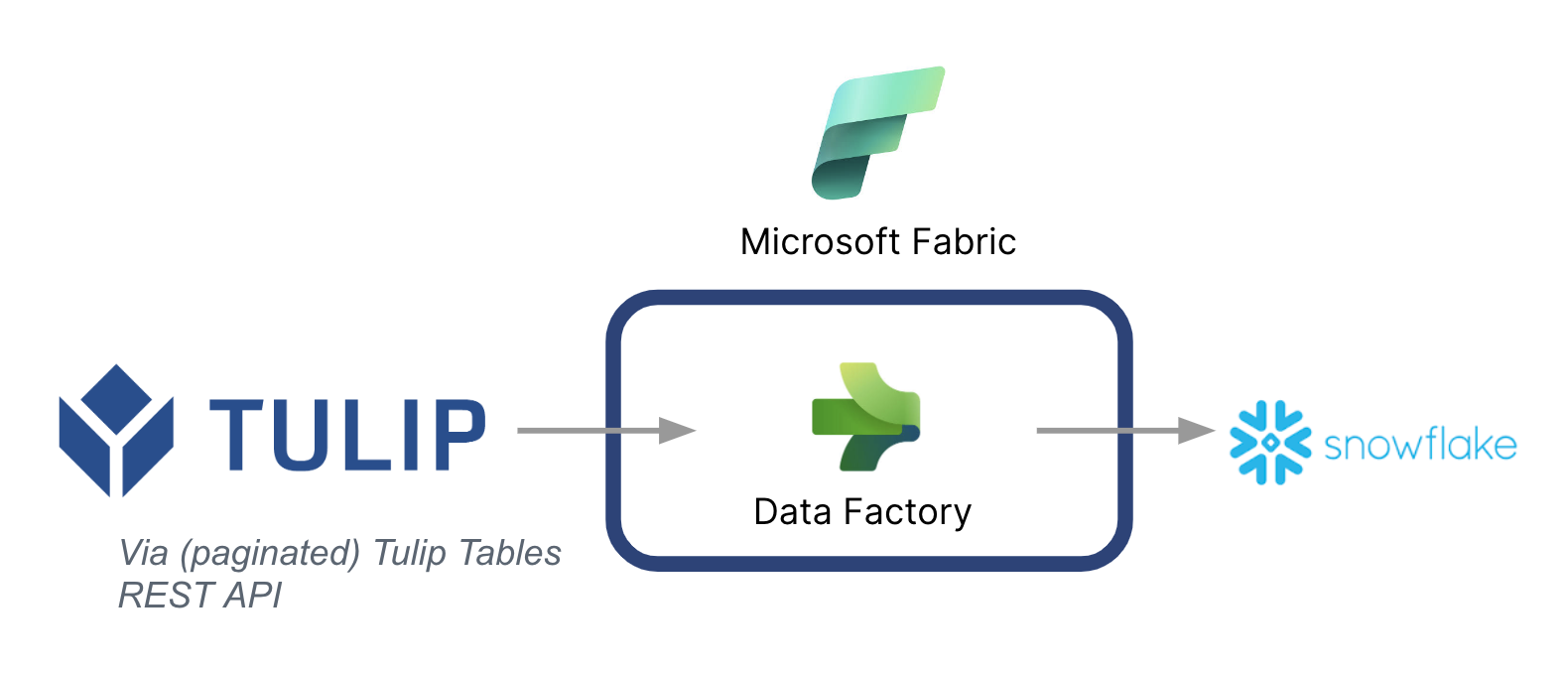
Es ist wichtig zu beachten, dass Microsoft als Datenpipeline verwendet werden kann, um Daten aus Tulip mit anderen Datenquellen zu synchronisieren - auch mit Nicht-Microsoft-Datenquellen.
Microsoft Fabric-Kontext
Microsoft Fabric umfasst alle relevanten Tools für die End-to-End-Datenaufnahme, Speicherung, Analyse und Visualisierung.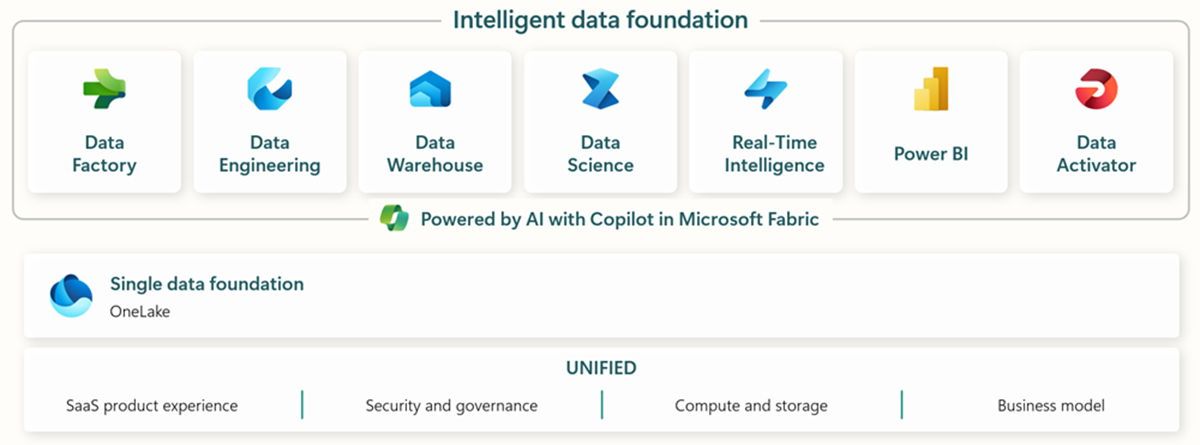
Spezifische Dienste sind im Folgenden zusammengefasst:* Data Factory - Daten aus anderen Systemen aufnehmen, kopieren oder extrahieren * Data Engineering - Daten transformieren und manipulieren * Data Warehouse - Daten in einem SQL Data Warehouse speichern * Data Science - Daten mit gehosteten Notebooks analysieren * Real Time Analytics - Streaming-Analysen und Visualisierungstools unter einem einzigen Rahmen von Fabric nutzen * PowerBI - Unternehmenseinblicke mit PowerBI für Business Intelligence ermöglichen
Unter diesem Link finden Sie weitere Informationen zu Microsoft Fabric
Bestimmte Funktionen können jedoch auch in Verbindung mit anderen Data Clouds genutzt werden. So kann Microsoft Data Factory beispielsweise mit den folgenden Nicht-Microsoft-Datenspeichern arbeiten: * Google BigQuery * Snowflake * MongoDB * AWS S3
Unter diesem Link finden Sie weitere Informationen
Wertschöpfung
Dieser Leitfaden stellt eine einfache Möglichkeit vor, Daten von Tulip in Snowflake für unternehmensweite Analysen im Stapelverfahren abzurufen. Wenn Sie Snowflake verwenden, um andere Unternehmensdaten zu speichern, kann dies eine großartige Möglichkeit sein, diese mit Daten aus dem Betrieb zu kontextualisieren, um bessere datengesteuerte Entscheidungen zu treffen.
Anweisungen zur Einrichtung
Erstellen Sie eine Datenpipeline auf Data Factory (In Fabric) und machen Sie die Quelle zu REST und die Senke zu Snowflake
Quellkonfiguration:
- Gehen Sie auf der Fabric-Startseite zu Data Factory
- Erstellen Sie eine neue Datenpipeline in Data Factory
- Beginnen Sie mit dem "Copy Data Assistant", um den Erstellungsprozess zu rationalisieren
- Details zum Assistenten zum Kopieren von Daten:
- Datenquelle: REST
- Basis-URL: https://[instance].tulip.co/api/v3
- Authentifizierungstyp: Grundlegend
- Benutzername: API-Schlüssel von Tulip
- Passwort: API-Geheimnis von Tulip
- Relative URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Anfrage: GET
- Name der Paginierungsoption: AbfrageParameter.{Offset}
- Paginierung Option Wert: BEREICH:0:10000:100
- Hinweis: Die Grenze kann bei Bedarf niedriger als 100 sein, aber die Schrittweite in der Paginierung muss übereinstimmen.
- Hinweis: Der Paginierungswert für den Bereich muss größer sein als die Anzahl der Datensätze in der Tabelle.
Sink (Ziel)-Konfiguration:
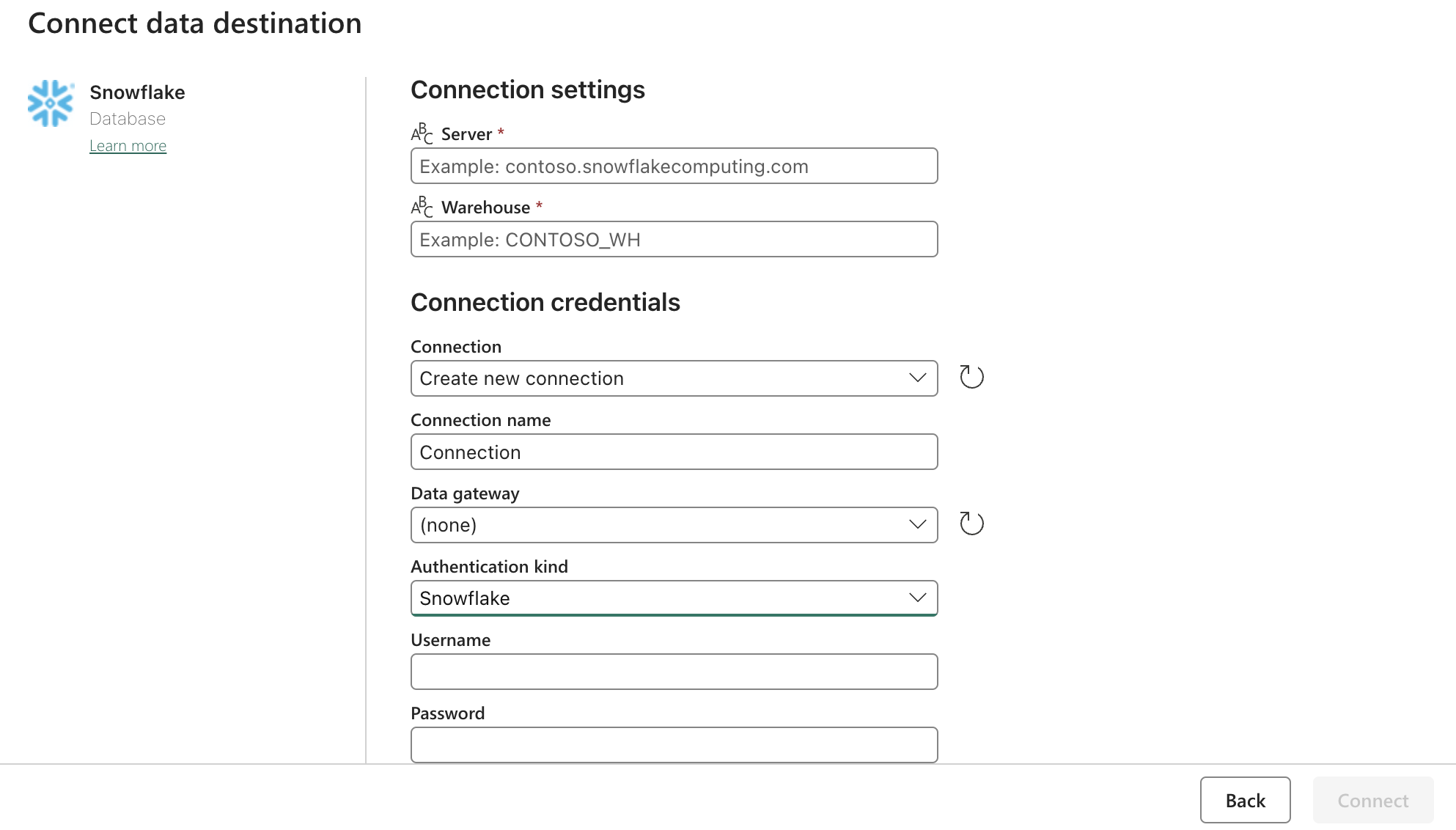
Aktualisieren Sie die Snowflake OAuth2.0-Einstellungen mit dem obigen Formular. Konfigurieren Sie dann die Auslöser so, dass sie auf eine relevante Aktion, manuell oder zeitgesteuert reagieren.
Nächste Schritte
Sobald dies erledigt ist, sollten Sie weitere Funktionen wie die Datenbereinigung innerhalb von Fabric mithilfe von Datenflüssen untersuchen. Dadurch können Datenfehler reduziert werden, bevor sie an anderer Stelle, z. B. in Snowflake, geladen werden.