

Ein Leitfaden zur Universalvorlage und zur Optimierung Ihrer Funktionen.
Die Universal Template ist eine einheitliche Vorlage zur nahtlosen Erstellung von Analysen. Sie ermöglicht es Ihnen, zwischen den Visualisierungstypen zu wechseln, indem Abfrage und Visualisierung der Daten entkoppelt werden. Die Universalvorlage unterstützt alle Analysetypen und Tulip-Datenquellen (Abschlüsse, Tabellendaten und Maschinendaten).

Verwendung von Abfragen und Visualisierungen
Die Abfrage ist wie eine Anweisung, die Sie dem System geben, was es mit Ihren "rohen" Daten aus einer App, einer Maschine oder in einer Tulip-Tabelle machen soll. Das Abfrageergebnis ist eine tabellarische Darstellung der Daten, die von Tulip Analytics auf der Grundlage der von Ihnen konfigurierten Abfrage erstellt wird. Sie konfigurieren die Abfrage im linken Seitenpanel des Analytics Editors.
Sie können die Daten aus dieser Abfrage mit verschiedenen Visualisierungen visualisieren, die alle oder nur ausgewählte Teile der Daten zeigen. Die Visualisierung wird oben im Analyse-Editor ausgewählt und im rechten Bereich des Analyse-Editors weiter konfiguriert.
Sie können das Abfrageergebnis immer unterhalb der Visualisierung sehen, wenn Sie auf Abfrageergebnis anzeigen klicken, es sei denn, Sie haben die Visualisierung "Tabelle" ausgewählt.
Abfrage erstellen
Datenquelle
Eine Datenquelle ist das, worauf die Analyse aufgebaut ist. Sie können aus den Abschlussdaten einer App, Tabellendaten oder Maschinendaten wählen.
Wenn Sie eine Analyse für App-Abschlussdaten erstellen, können Sie mehrere Apps auswählen. In diesem Fall werden bei der Analyse Abschlussdatensätze aus allen ausgewählten Apps berücksichtigt.
Beachten Sie, dass bei Auswahl mehrerer Apps die Daten nicht zusammengeführt werden, sondern jeder Abschluss als separate Zeile behandelt wird. Das bedeutet, dass Sie die "Felder" der Abschlüsse (z. B. Benutzer, Startzeit und Station) gemeinsam analysieren können. Andere Daten, wie z. B. App-Variablen, werden für jede App separat behandelt und haben "null" als Wert für die Abschlussdatensätze aller anderen Apps.
Wenn Sie eine Analyse für Maschinen erstellen, können Sie einen oder mehrere Maschinentypen auswählen. Wenn Sie eine Analyse für eine bestimmte Maschine erstellen möchten, fügen Sie einen zusätzlichen Filter hinzu.
Gruppierungen und Operationen
Gruppierungen und Operationen sind die Kernbereiche bei der Erstellung Ihrer Abfrage. Hier legen Sie fest, welche Ihrer Datenoptionen Sie in welcher Form anzeigen möchten.
Gruppierungen
Gruppierungen geben eine Anweisung, um die Gruppen so weit wie möglich zu kombinieren. Wenn Sie mit der GROUP BY-Funktion in gängigen QL- und BI-Tools vertraut sind, verhält sich der Gruppierungsprozess nahezu identisch. Gruppierungen bestimmen die Felder und Datentypen, um ähnliche Werte zu finden. Sie ermöglichen es Ihnen, eine immer detailliertere Sicht auf die Daten zu erhalten, die Sie sehen möchten.
Gruppierungen geben mehr Kontrolle darüber, welche Zeilen kombiniert werden sollen. Eine Gruppierung kann ein beliebiges Feld eines beliebigen Typs sein. Je nachdem, welche Operationen Sie konfiguriert haben, wird das Hinzufügen einer oder mehrerer Gruppierungen zu unterschiedlichen Ergebnissen führen.
Gehen wir ein paar Gruppierungskombinationen durch.
| | Eine Gruppierung | Mehrere Gruppierungen | --- | --- | --- --- --- | | Nur eindeutige Werte | Eine Zeile für jede Zeile in den Quelldaten mit den Werten für das Gruppierungsfeld und den eindeutigen Werten für diese Zeile | Eine Zeile für jede Zeile in den Quelldaten mit den Werten für die Gruppierungsfelder und den eindeutigen Werten für diese Zeile | | Nur Aggregationen | Eine Zeile für jeden eindeutigen Eintrag im Gruppierungsfeld mit diesem Wert für die Gruppierung und die aggregierten Werte aller Zeilen aus den Quelldaten mit diesem Gruppierungswert | Eine Zeile für jede Kombination der Gruppierungsfelder eindeutige Einträge mit den jeweiligen Werten für die Gruppierungen und die aggregierten Werte aller Zeilen aus den Quelldaten mit den jeweiligen Gruppierungswerten | | Eindeutige Werte und Aggregationen | Eine Zeile für jede Zeile in den Quelldaten mit den Werten der Gruppierungen und den eindeutigen Werten und den aggregierten Werten aller Zeilen aus den Quelldaten mit diesem Gruppierungswert (d. h. die aggregierten Werte sind died. h. die aggregierten Werte sind für alle Zeilen mit demselben Gruppierungswert gleich) | Eine Zeile für jede Zeile in den Quelldaten, die die Werte der Gruppierungen und die aggregierten Werte aller Zeilen aus den Quelldaten mit den jeweiligen Gruppierungswerten zeigt (d. h. die aggregierten Werte sind in allen Zeilen mit denselben Gruppierungswerten gleich).
Es ist wichtig zu beachten, dass die Daten nur angezeigt werden, wenn eine Zeile mit relevanten Informationen vorhanden ist. Wenn in den Quelldaten für einen bestimmten Tag keine Daten vorhanden sind, wird die Analyse leer angezeigt.
Schauen wir uns ein Beispiel an, wie Gruppierungen funktionieren: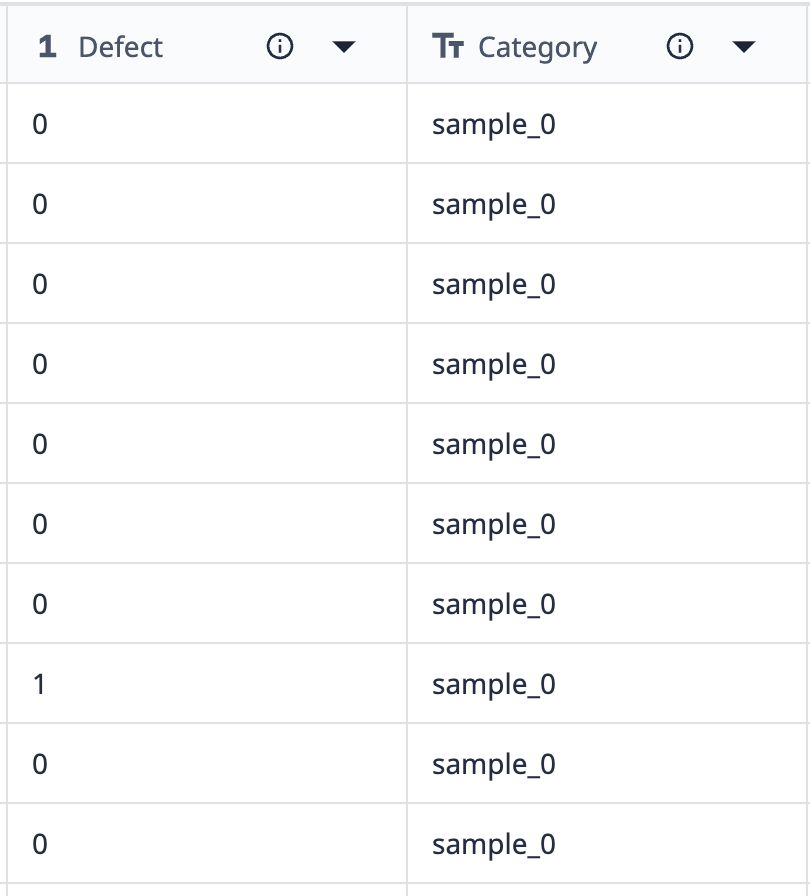
Die Daten aus dieser Tabelle zeigen, dass es 10 Datensätze mit der Bezeichnung "sample_0" gibt. Wenn wir diese Daten in einer Visualisierung gruppieren möchten, die nur die verschiedenen sample_0-Punkte anzeigt, bei denen sich die Fehleranzahl unterscheidet, können wir Gruppierungen verwenden, um ähnliche Datensätze zu kombinieren.
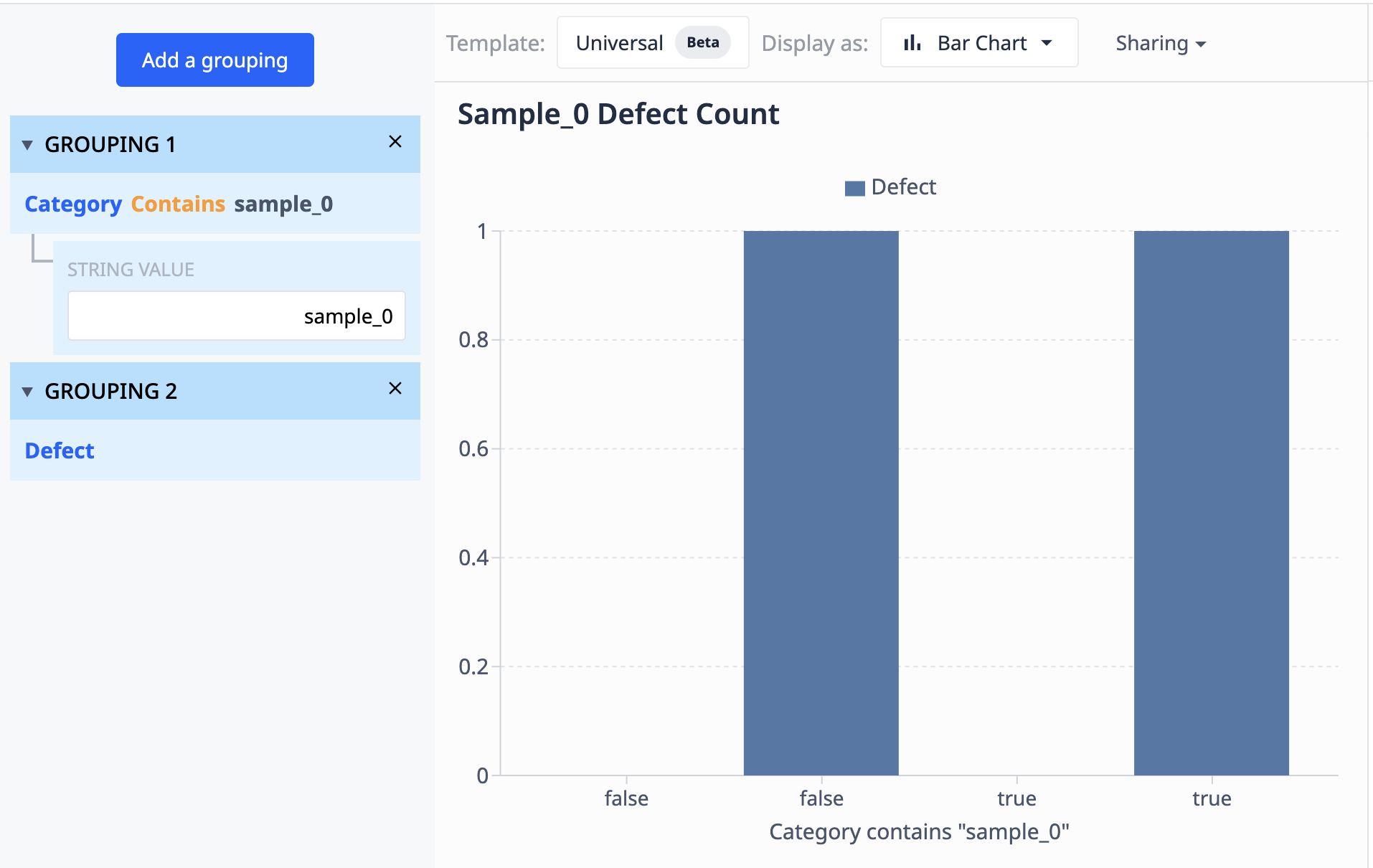
Operationen
Operationen können entweder eine Aggregation sein, die mehrere Datensätze zusammenfasst, oder ein Feld, das dies nicht tut.
Operationen lassen sich in zwei allgemeine Kategorien einteilen: 1. Eindeutige Werte Eindeutige Werte stellen einzelne Datenpunkte aus Ihren Quelldaten dar. Im einfachsten Fall handelt es sich um den Wert einer Variablen aus einem Abschlussdatensatz, ein Feld aus einer Tabelle oder ein Maschinenattribut.
Es kann sich aber auch um einen komplexeren Datenpunkt handeln, z. B. die Summe von zwei Feldern aus demselben Datensatz, eine Kombination aus mehreren Zeichenfolgen oder ein Ausdruck, der keine Aggregationsfunktion enthält.
Mit einer Tabelle, die ein Feld mit Werten (numerisch) und ein Feld mit Zeitstempeln (datetime) enthält, können wir die Werte nach Zeitstempel visualisieren, damit sie als solche erscheinen:
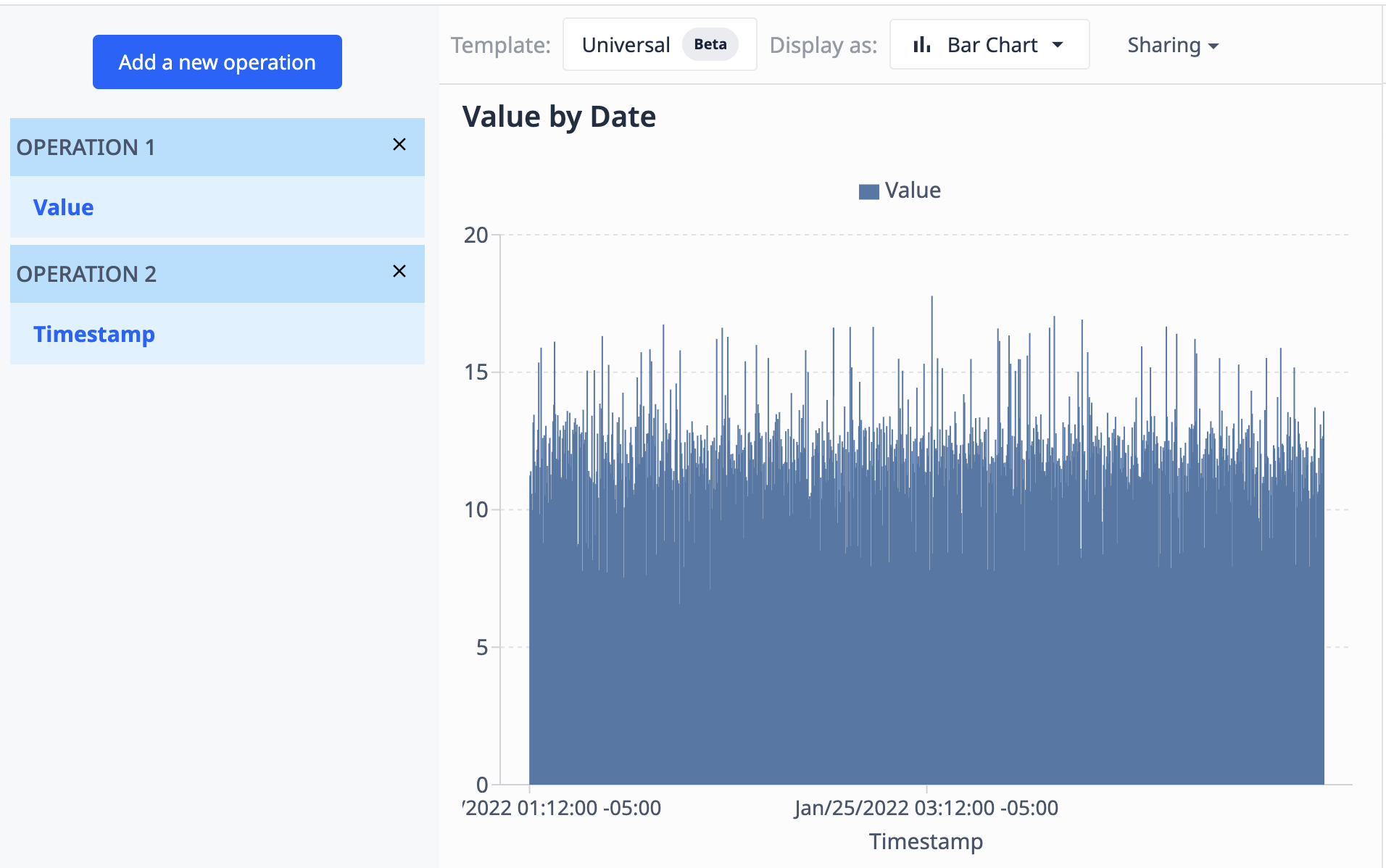
- Aggregationen
Aggregationen sind Funktionen, die Daten aus mehreren Zeilen nehmen und sie auf der Grundlage einer bestimmten Logik kombinieren. Es gibt eine Reihe von Aggregationsfunktionen, die als vorkonfigurierte Auswahl zur Verfügung stehen, oder Sie können auch Aggregationsfunktionen im Ausdruckseditor verwenden, um Ihre eigenen erweiterten Aggregationen zu erstellen. Verschiedene Aggregationsfunktionen funktionieren für verschiedene Datentypen. Im Folgenden sehen Sie, welche Funktionen verfügbar sind und welche Datentypen sie unterstützen.
Direkt zugängliche AggregationsfunktionenDiese ermöglichen die Kombination von Zeilen:
- Durchschnitt
- Median
- Summe
- Minimum
- Maximum
- Modus
- Standardabweichung
-
- Perzentil
-
- Perzentil
- Verhältnis
- Verhältniskomplement
Im Ausdruckseditor verfügbare Aggregationsfunktionen
Mit den Aggregationsfunktionen im Ausdruckseditor können Sie auf der Grundlage Ihrer spezifischen Anforderungen granularere Daten bereitstellen. Eine vollständige Anleitung zu allen verfügbaren Ausdrücken, die Sie in Ihren Analysen verwenden können, finden Sie unter Vollständige Liste der Ausdrücke im Analyse-Editor.
Begrenzung und Sortierung
Sie können die maximale Anzahl von Zeilen definieren, die das Abfrageergebnis enthält, indem Sie einen Grenzwert hinzufügen. Mit Grenzwerten können Sie sich auf bestimmte Daten konzentrieren oder die Menge der in einem Diagramm angezeigten Daten begrenzen. Sie können zum Beispiel ein Limit hinzufügen, um die drei Produktionslinien anzuzeigen, die im letzten Monat die meisten Fehler hatten.
Die Sortierdaten legen fest, welche Zeilen bei der Auswertung des Limits berücksichtigt werden. Sie können für jedes Feld, das Teil des Abfrageergebnisses ist, eine aufsteigende oder absteigende Sortierung hinzufügen. Wenn Sie mehrere Felder zur Sortierung hinzufügen, werden die Daten zuerst nach dem ersten Feld sortiert. Die resultierenden Gruppen für jeden Wert des ersten Feldes werden dann nach dem zweiten sortiert usw.
Beachten Sie, dass, wenn Sie die Sortierung nicht explizit festlegen, die Sortierung Ihres Abfrageergebnisses je nach den verfügbaren Daten variieren kann. Bei der Verwendung von Begrenzungen oder Diagrammen mit ordinalen Achsen kann dies zu unterschiedlichen Darstellungen führen. Wir empfehlen, in diesen Fällen eine geeignete Sortierung hinzuzufügen.
Das folgende Beispiel verwendet das Diagramm, das wir mit Operationen gesehen haben. Hier beschränken wir die Ergebnisse auf 100 Datenpunkte und sortieren sie in absteigender Reihenfolge nach ihrem Datum.
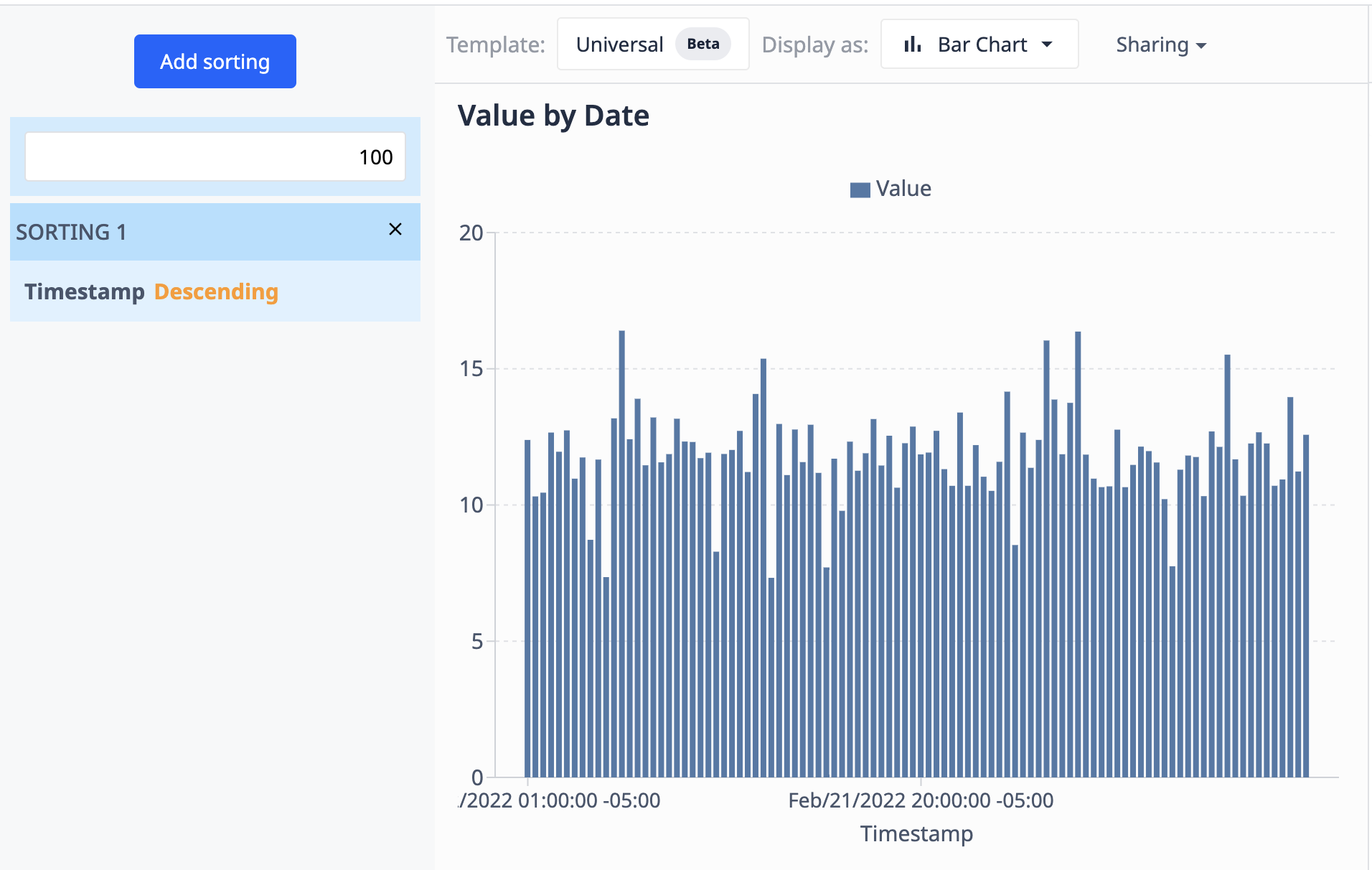
Da die Datenquelle (die Tabelle) mit neuen Datensätzen aktualisiert wird, werden in der Visualisierung nur die 100 neuesten Datensätze angezeigt.
Datumsbereich
Der Datumsbereich definiert, welche Daten in die Auswertung der Analyse einbezogen werden. Stellen Sie sich dies wie einen Filter für einen Datumswert im Datensatz vor. Der Datumsbereich schränkt die Analyse auf die Daten ein, die für einen bestimmten Zeitraum relevant sind. Aus Leistungsgründen empfehlen wir, den kürzest möglichen Datumsbereich für Ihren Anwendungsfall zu verwenden, anstatt später zusätzliche Filter hinzuzufügen, um den Zeitraum einzugrenzen.
Die folgenden Datumswerte werden für den Datumsbereich für die verschiedenen Datenquellen verwendet: * App-Abschlussdaten * "Startzeit" des App-Abschlusses * Tabellendatum, vom Benutzer wählbar * Erstellungsdatum * Aktualisierungsdatum * Maschinendaten * Startzeit des Maschinenaktivitätseintrags
Filter
Filter legen fest, welche Daten in das Abfrageergebnis aufgenommen werden sollen. Typische Anwendungsfälle sind: * Anzeige von Daten nur für eine bestimmte Produktionslinie * Ausschluss einer bestimmten Maschine von einer Analyse * Anzeige nur von Datenpunkten mit einem Wert über einem bestimmten Schwellenwert
Filter werden wie eine Bedingung konfiguriert. Alle Daten, die die Bedingung erfüllen, werden in die Analyse einbezogen. Sehen wir uns einige Beispiele an:
- Produktionslinie ist gleich A
- Schließt alle Datensätze ein, die "A" im Feld "Produktionslinie" haben
- Maschinen-ID ist nicht gleich "Maschine 1".
- Schließt alle Maschinen ein, die nicht gleich "Maschine 1" sind.
- Testdauer > 55
- Schließt alle Datensätze ein, bei denen die Prüfung länger als 55 Sekunden gedauert hat.
Filter können auf zwei verschiedene Arten definiert werden: 1. Verwendung der vorkonfigurierten Filterfunktionen in Kombination mit einem Feld aus Ihren Quelldaten 2. Konfigurieren eines Ausdrucks, der als Boolescher Wert ausgewertet wird.
Visualisierungen
Wenn eine neue Analyse mit der Universalvorlage erstellt wird, ist standardmäßig die Tabellenvisualisierung ausgewählt. Sie können jederzeit zu einem anderen Visualisierungstyp wechseln, indem Sie die Einstellung Anzeigen als am oberen Rand des Bildschirms verwenden. Neben "Tabelle" stehen die folgenden Optionen zur Verfügung:
- Balken
- Linie
- Streuung
- Histogramm
- Donut
- Messgerät
- Kasten
- Einzelner Wert
- Diashow
- Pareto
Konfigurieren einer Visualisierung
Für die meisten Visualisierungstypen können Sie frei wählen, welche Felder Ihres Abfrageergebnisses Sie auf welche Weise visualisieren möchten. Dies geschieht im Datenbereich auf der rechten Seite des Analyse-Editors. Wenn Sie zum ersten Mal zu einer anderen Visualisierung wechseln, ist die Konfiguration leer. Sie können Ihre Visualisierung entweder manuell im Datenbereich einrichten oder mit einem Vorschlag beginnen, indem Sie auf die Schaltfläche Mit Vorschlag beginnen in der Mitte des Bildschirms klicken.
Die Voraussetzungen, um eine Visualisierung konfigurieren zu können, sind
- Es sind Daten in Ihrem Abfrageergebnis vorhanden
- Sie haben die richtigen Felder für die Visualisierung zur Verfügung. Für ein Balkendiagramm ist z.B. mindestens ein numerisches Feld erforderlich.
Wenn diese beiden Voraussetzungen nicht erfüllt sind, zeigt der Analytics Editor eine Warnmeldung an.
Optionen im Datenbereich
Die folgende Liste gibt einen Überblick über die Konfigurationsoptionen für die verschiedenen Visualisierungstypen:
Balken, Linie, Streuung
- X-Achse
- Das Feld, dessen Werte auf der X-Achse angezeigt werden sollen
- Y-Achse
- Ein oder mehrere numerische Felder, deren Werte auf der Y-Achse angezeigt werden sollen.
- Vergleichen nach
- Das Feld, das verwendet wird, um Werte als dieselbe Serie im Diagramm anzuzeigen.
Wenn Sie mehrere Serien anzeigen möchten, können Sie entweder mehrere Felder für die Y-Achse oder ein Feld für die Y-Achse und ein Feld für Vergleichen nach auswählen. Die Kombination von mehreren Feldern für die Y-Achse und Vergleichen nach ist nicht möglich.
Für diese Visualisierungsarten steht im Menü "..." der Einstellung X-Achse ein Modus "Feldwerte vergleichen" zur Verfügung. Dieser ermöglicht es, numerische Werte mehrerer Felder nebeneinander zu visualisieren. Wenn die Option aktiviert ist, sind die folgenden Optionen verfügbar:
- X-Achse
- Die zu vergleichenden numerischen Felder
- Vergleichen nach
- Das Feld, das verwendet wird, um die Werte im Diagramm als dieselbe Serie anzuzeigen
- Standardmäßig wird der Zeilenindex der Daten verwendet.
Histogramm
- Werte
- Das numerische Feld mit den Werten, für die das Histogramm angezeigt wird.
- Dieses Feld sollte alle Werte in einer unaggregierten Form enthalten. Die Visualisierung kümmert sich um die Berechnung der Histogrammwerte.
- Vergleichen nach
- Das Feld, das verwendet wird, um die "Werte" in mehrere Reihen aufzuteilen, die jeweils als separates Histogramm in der Visualisierung angezeigt werden.
Donut
- Werte
- Die numerischen Felder, die die zu visualisierenden Werte enthalten
- Beschriftungen
- Das Feld, das für die Beschriftung der verschiedenen Donut-Segmente verwendet wird. Diese werden im Tooltip und in der Legende angezeigt.
- Standardmäßig wird der Zeilenindex der visualisierten Daten verwendet
Einzelwert, Gauge
- Wert
- Die numerischen Felder, die den zu visualisierenden Wert enthalten
Hinweis: Es wird der Wert der ersten Zeile im Abfrageergebnis visualisiert. Wenn Ihre Abfrage mehrere Zeilen zurückliefert, können Sie eine Sortierung hinzufügen, um zu ändern, welcher Wert dies ist. Wir empfehlen Ihnen, die Schaltfläche "Abfrageergebnis anzeigen" am unteren Rand zu verwenden, um die Daten zu überprüfen, wenn Sie nicht den erwarteten Wert in der Visualisierung sehen.
Kasten
- X-Achse
- Das Feld, dessen Werte auf der X-Achse angezeigt werden sollen
- Für jeden Wert in diesem Feld wird eine eigene "Box" visualisiert
- Y-Achse
- Das numerische Feld, das die Werte enthält, die im Box-Diagramm dargestellt werden sollen, wird angezeigt
- Dieses Feld sollte alle Werte in einer unaggregierten Form enthalten. Die Visualisierung kümmert sich um die Berechnung der Box-Werte.
Pareto
- X-Achse
- Das Feld, dessen Werte auf der X-Achse angezeigt werden sollen
- Y-Achse
- Das numerische Feld, dessen Werte auf der Y-Achse angezeigt werden sollen.
Die kumulative Prozentlinie wird in der Visualisierung automatisch berechnet.
Umschalten zwischen Visualisierungsarten
Beim Umschalten zwischen den im Datenpanel konfigurierten Visualisierungstypen werden alle kompatiblen Konfigurationen übernommen. Dies minimiert den Aufwand für den Wechsel und ermöglicht es Ihnen, auf einfache Weise verschiedene Visualisierungsoptionen für Ihre Daten auszuprobieren.
Tabelle und Diashow
Die Visualisierungen "Tabelle" und "Diashow" haben kein Datenpanel und werden automatisch konfiguriert.
Diese Tabelle zeigt alle in der Abfrage konfigurierten Gruppierungen und Operationen an. Sie sind in der Reihenfolge angeordnet, in der sie im Query Builder auf der linken Seite erscheinen.
Die Diashow zeigt alle Bilder, die in einem beliebigen Bildfeld im Abfrageergebnis enthalten sind, als einzelne Dias an. Alle zusätzlichen Felder, die in der Abfrage konfiguriert wurden, werden in einer Tabelle unterhalb des Bildes angezeigt.
Haben Sie gefunden, wonach Sie gesucht haben?
Sie können auch auf community.tulip.co Ihre Frage stellen oder sehen, ob andere mit einer ähnlichen Frage konfrontiert wurden!
