
Usprawnienie pobierania danych z Tulip do Snowflake w celu uzyskania szerszych możliwości analitycznych i integracyjnych
Cel
W tym przewodniku opisano krok po kroku, jak pobierać dane z tabel Tulip do Snowflake za pośrednictwem Microsoft Fabric (Azure Data Factory).
Poniżej przedstawiono architekturę wysokiego poziomu: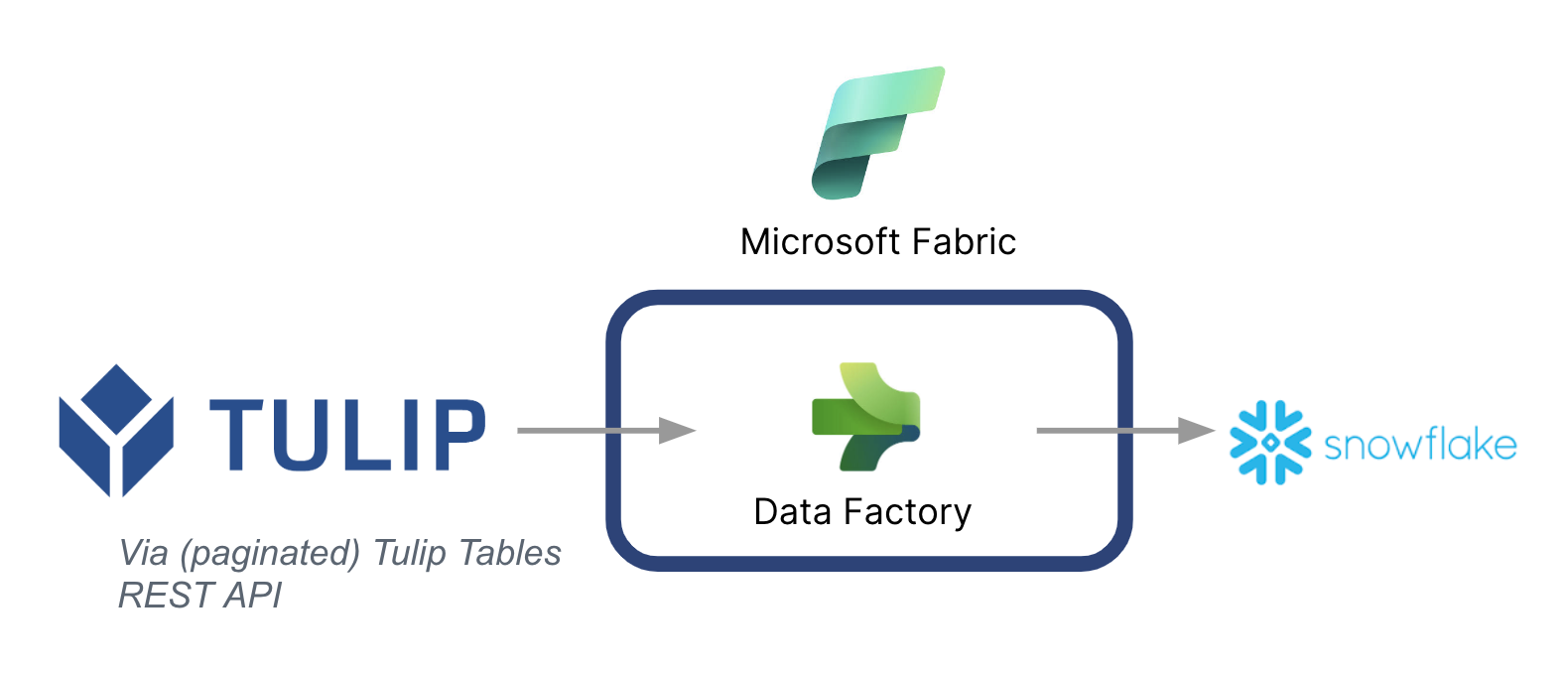
Ważne jest, aby pamiętać, że Microsoft może być używany jako potok danych do synchronizacji danych z Tulip do innych źródeł danych - nawet źródeł danych innych niż Microsoft.
Kontekst Microsoft Fabric
Microsoft Fabric obejmuje wszystkie odpowiednie narzędzia do kompleksowego pozyskiwania, przechowywania, analizy i wizualizacji danych.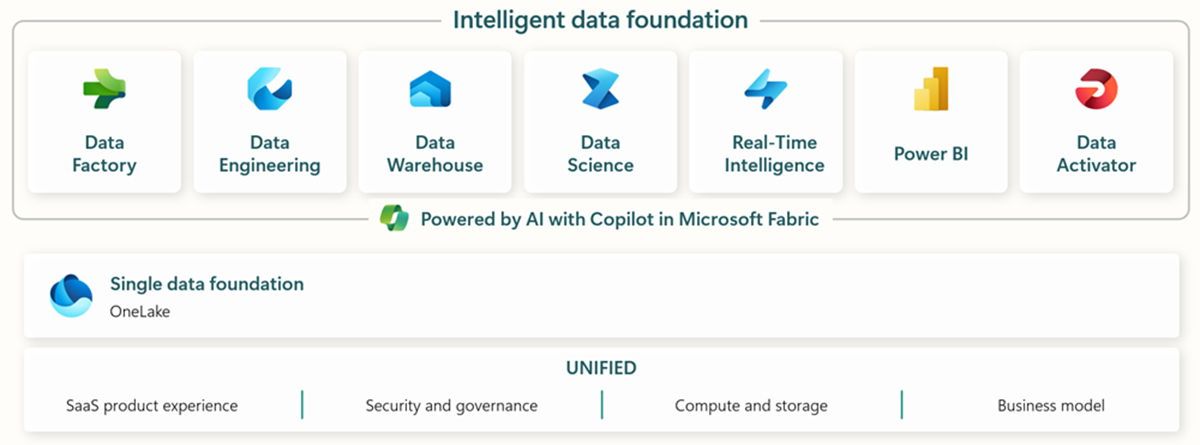
Konkretne usługi podsumowano poniżej:* Data Factory - pozyskiwanie, kopiowanie lub wyodrębnianie danych z innych systemów * Data Engineering - przekształcanie i manipulowanie danymi * Data Warehouse - przechowywanie danych w hurtowni danych SQL * Data Science - analizowanie danych za pomocą hostowanych notebooków * Real Time Analytics - korzystanie z narzędzi do analizy strumieniowej i wizualizacji w ramach jednej struktury Fabric * PowerBI - udostępnianie wglądu w dane przedsiębiorstwa za pomocą PowerBI do analizy biznesowej.
Więcej informacji na temat Microsoft Fabric można znaleźć pod tym linkiem.
Jednak określone funkcje mogą być również używane w połączeniu z innymi chmurami danych. Na przykład Microsoft Data Factory może współpracować z następującymi magazynami danych firm innych niż Microsoft: * Google BigQuery * Snowflake * MongoDB * AWS S3
Sprawdź ten link, aby uzyskać więcej informacji
Tworzenie wartości
Ten przewodnik przedstawia prosty sposób wsadowego pobierania danych z Tulip do Snowflake w celu szerszej analizy w całym przedsiębiorstwie. Jeśli używasz Snowflake do przechowywania innych danych przedsiębiorstwa, może to być świetny sposób na kontekstualizację ich z danymi z hali produkcyjnej w celu podejmowania lepszych decyzji opartych na danych.
Instrukcje konfiguracji
Utwórz potok danych w Data Factory (In Fabric) i ustaw źródło jako REST, a zlew jako Snowflake.
Konfiguracja źródła:
- Na stronie głównej Fabric przejdź do Data Factory
- Utwórz nowy potok danych w Data Factory
- Zacznij od "Copy Data Assistant", aby usprawnić proces tworzenia.
- Szczegóły asystenta kopiowania danych:
- Źródło danych: REST
- Bazowy adres URL: https://[instance].tulip.co/api/v3
- Typ uwierzytelniania: Podstawowe
- Nazwa użytkownika: Klucz API od Tulip
- Hasło: API Secret od Tulip
- Względny adres URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Żądanie: GET
- Nazwa opcji paginacji: QueryParameters.{offset}
- Wartość opcji paginacji: RANGE:0:10000:100
- Uwaga: W razie potrzeby limit może być niższy niż 100, ale przyrost w paginacji musi być zgodny.
- Uwaga: wartość paginacji dla zakresu musi być większa niż liczba rekordów w tabeli.
Sink (Destination) Config:
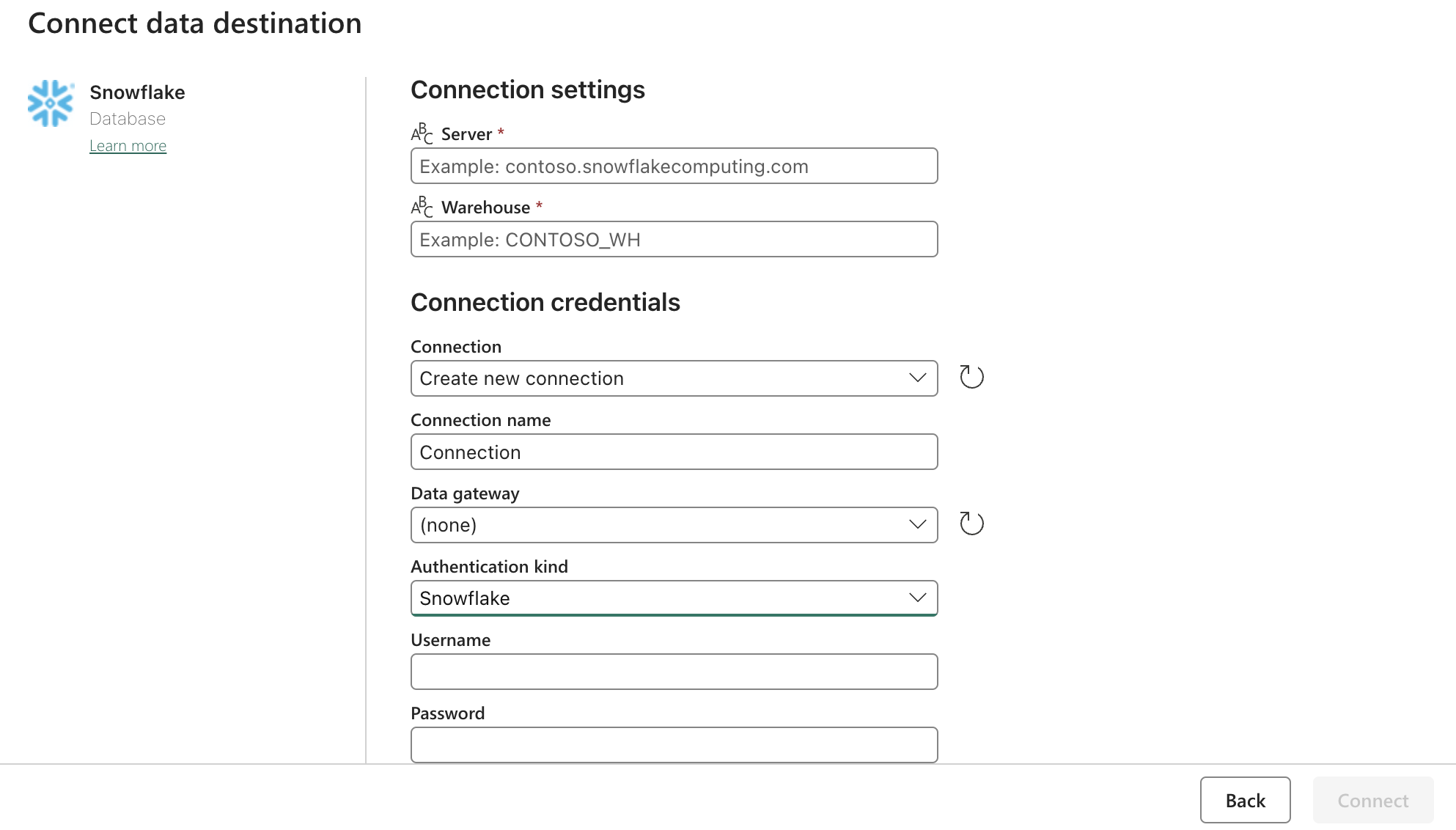
Zaktualizuj ustawienia Snowflake OAuth2.0 za pomocą powyższego formularza. Następnie skonfiguruj wyzwalacze tak, aby dotyczyły odpowiedniej akcji, instrukcji lub timera.
Następne kroki
Gdy to zrobisz, zbadaj dodatkowe funkcje, takie jak czyszczenie danych wewnątrz struktury przy użyciu przepływów danych. Może to zmniejszyć liczbę błędów danych przed załadowaniem ich do innych lokalizacji, takich jak Snowflake