
Rationalisierung der Datenübertragung von Tulip zu Microsoft Fabric für breitere Analysemöglichkeiten
Zweck
Diese Anleitung zeigt Schritt für Schritt, wie man Daten aus Tulip-Tabellen über eine paginierte REST-API-Abfrage an Fabric sendet. Dies ist nützlich für die Analyse von Tulip-Tabellen-Daten in einem Azure Data Lakehouse, Synapse Data Warehouse oder einem anderen Azure Data-Speicherort
Die breitere Architektur für Fabric -- Microsoft Cloud for Manufacturing ist unten dargestellt
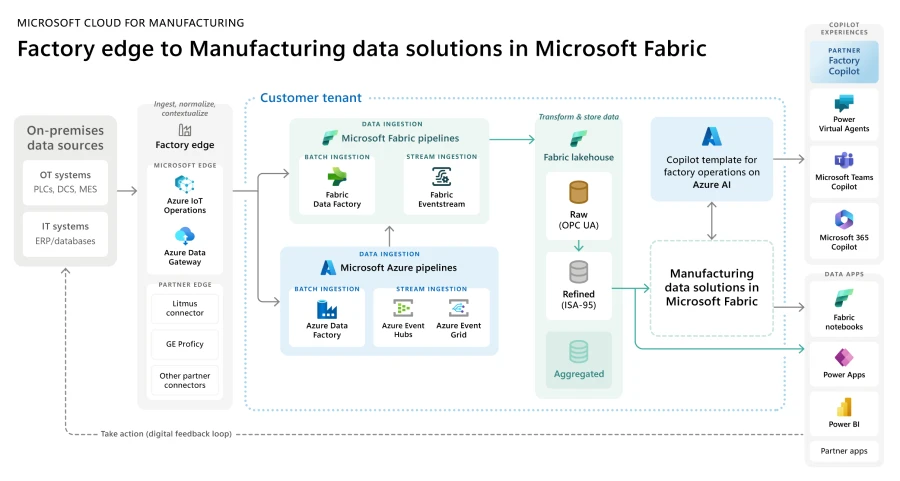
Einrichtung
Ein detailliertes Einrichtungsvideo ist unten eingebettet:
Allgemeine Anforderungen: * Verwendung der Tulip Tables API (API-Schlüssel und -Geheimnis in den Kontoeinstellungen erhalten) * Tulip Table (die eindeutige ID der Tabelle erhalten)
Prozess: 1. Gehen Sie auf der Fabric Homepage zu Data Factory 2. Erstellen Sie eine neue Data Pipeline auf Data Factory 3. Beginnen Sie mit dem "Copy Data Assistant", um den Erstellungsprozess zu rationalisieren 4. Details zum Assistenten zum Kopieren von Daten: 1. Datenquelle: REST 2. Basis-URL: https://[instance].tulip.co/api/v3 3. Authentifizierungstyp: Einfach 4. Benutzername: API-Schlüssel von Tulip 5. Passwort: API-Geheimnis von Tulip 6. Relative URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset} 7. Anfrage: GET 8. Name der Paginierungsoption: QueryParameters.{offset} 9. Pagination Option Value: RANGE:0:10000:100
Hinweis: Die Grenze kann bei Bedarf niedriger als 100 sein, aber die Schrittweite in der Paginierung muss übereinstimmen**Hinweis: Der Paginierungswert für den Bereich muss größer sein als die Anzahl der Datensätze in der Tabelle
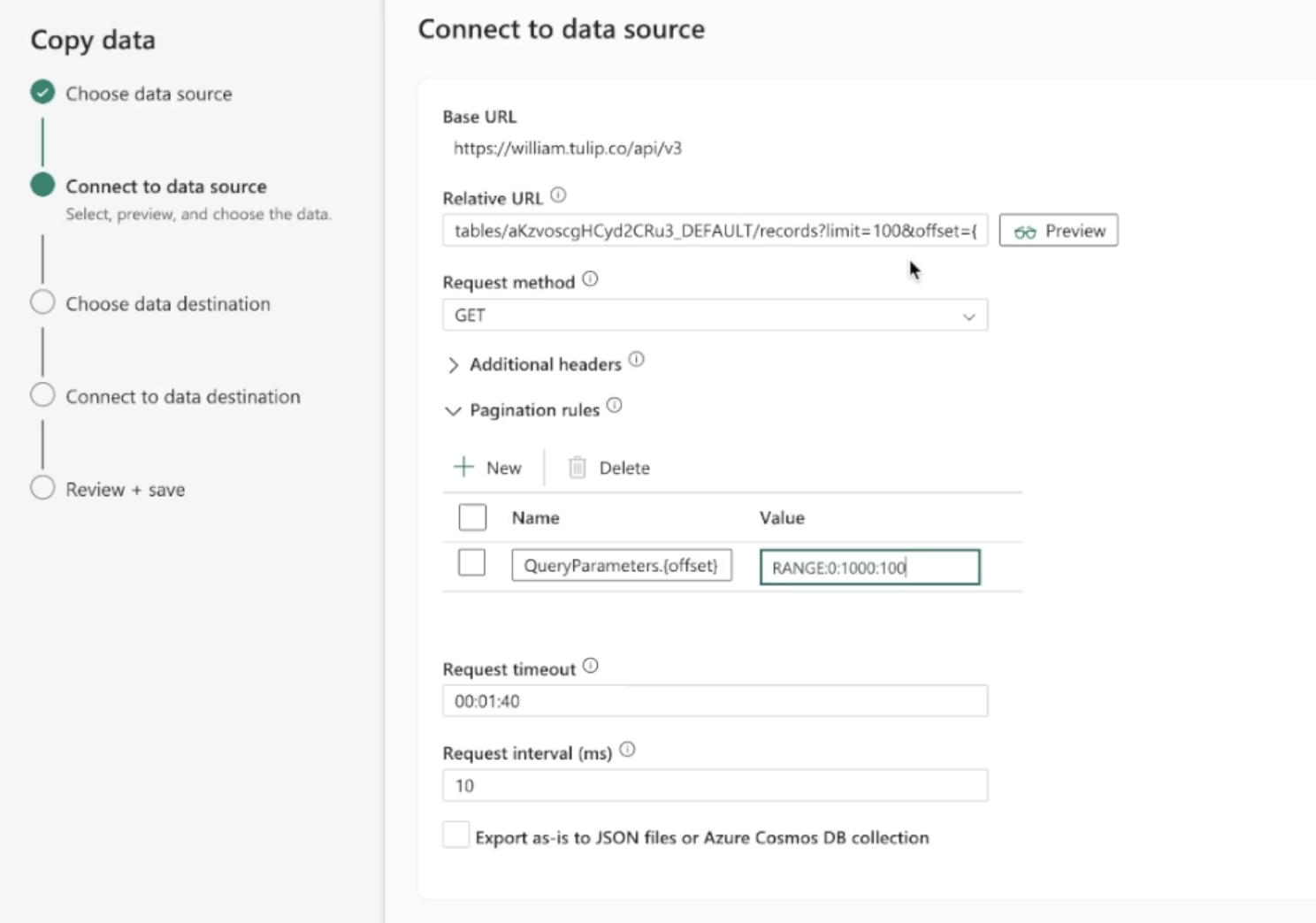
- Anschließend können Sie diese Daten an eine Vielzahl von Datenzielen wie Azure Lakehouse senden
- Verbinden Sie sich mit dem Datenziel, überprüfen Sie die Felder / benennen Sie sie nach Bedarf um, und schon sind Sie fertig!
Beispiel-Architektur
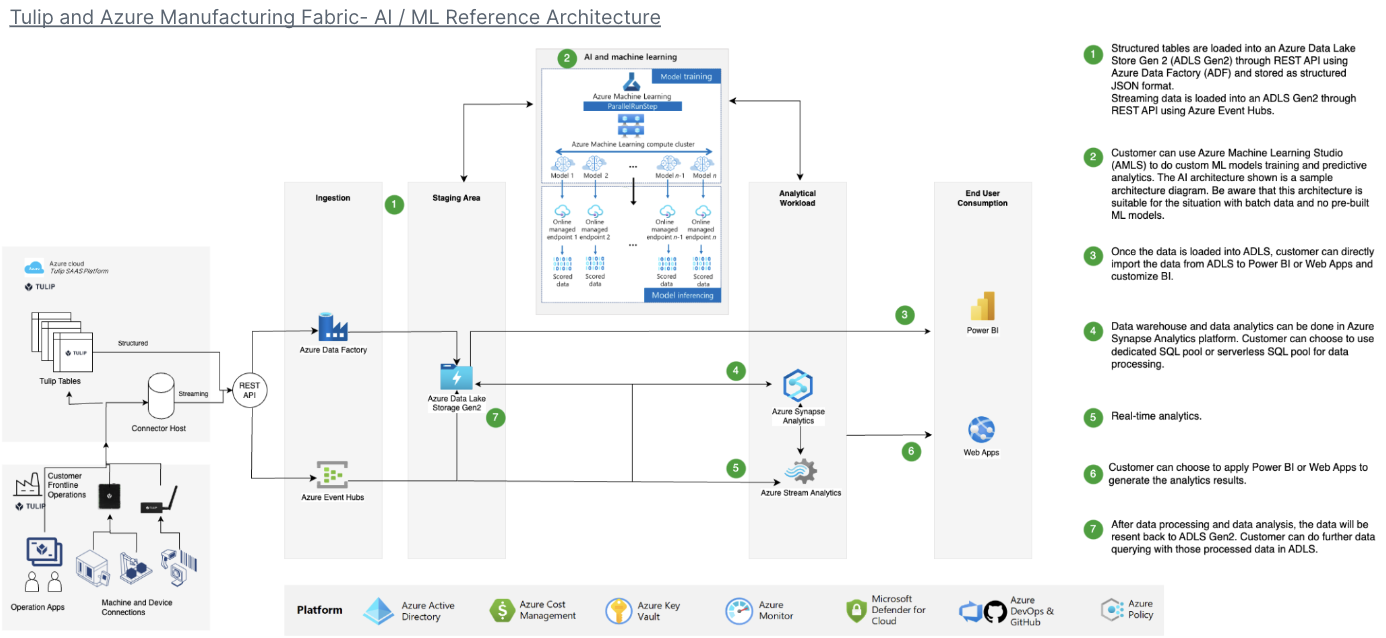
Anwendungsfälle und nächste Schritte
Sobald Sie die Verbindung hergestellt haben, können Sie die Daten mit einem Spark-Notebook, PowerBI oder einer Vielzahl anderer Tools leicht analysieren.
1. Fehlervorhersage- Identifizieren Sie Produktionsfehler, bevor sie auftreten, und erhöhen Sie die Fehlerquote beim ersten Mal - Identifizieren Sie die wichtigsten Qualitätsfaktoren in der Produktion, um Verbesserungen zu implementieren.
2. Optimierung der Qualitätskosten- Identifizierung von Möglichkeiten zur Optimierung des Produktdesigns ohne Beeinträchtigung der Kundenzufriedenheit
3. Energieoptimierung in der Produktion- Identifizierung von Produktionshebeln zur Optimierung des Energieverbrauchs
4. Liefer- und Planungsvorhersage und -optimierung- Optimierung des Produktionsplans auf der Grundlage der Kundennachfrage und des Echtzeit-Auftragsplans
5. Globales Maschinen-/Linien-Benchmarking- Benchmarking ähnlicher Maschinen oder Anlagen mit Normalisierung
6. Globales / regionales digitales Leistungsmanagement- Konsolidierte Daten zur Erstellung von Dashboards in Echtzeit