
Semplificare il reperimento dei dati da Tulip a Snowflake per maggiori opportunità di analisi e integrazione.
Scopo
Questa guida spiega passo per passo come recuperare i dati dalle tabelle Tulip a Snowflake tramite Microsoft Fabric (Azure Data Factory).
Di seguito è riportata un'architettura di alto livello: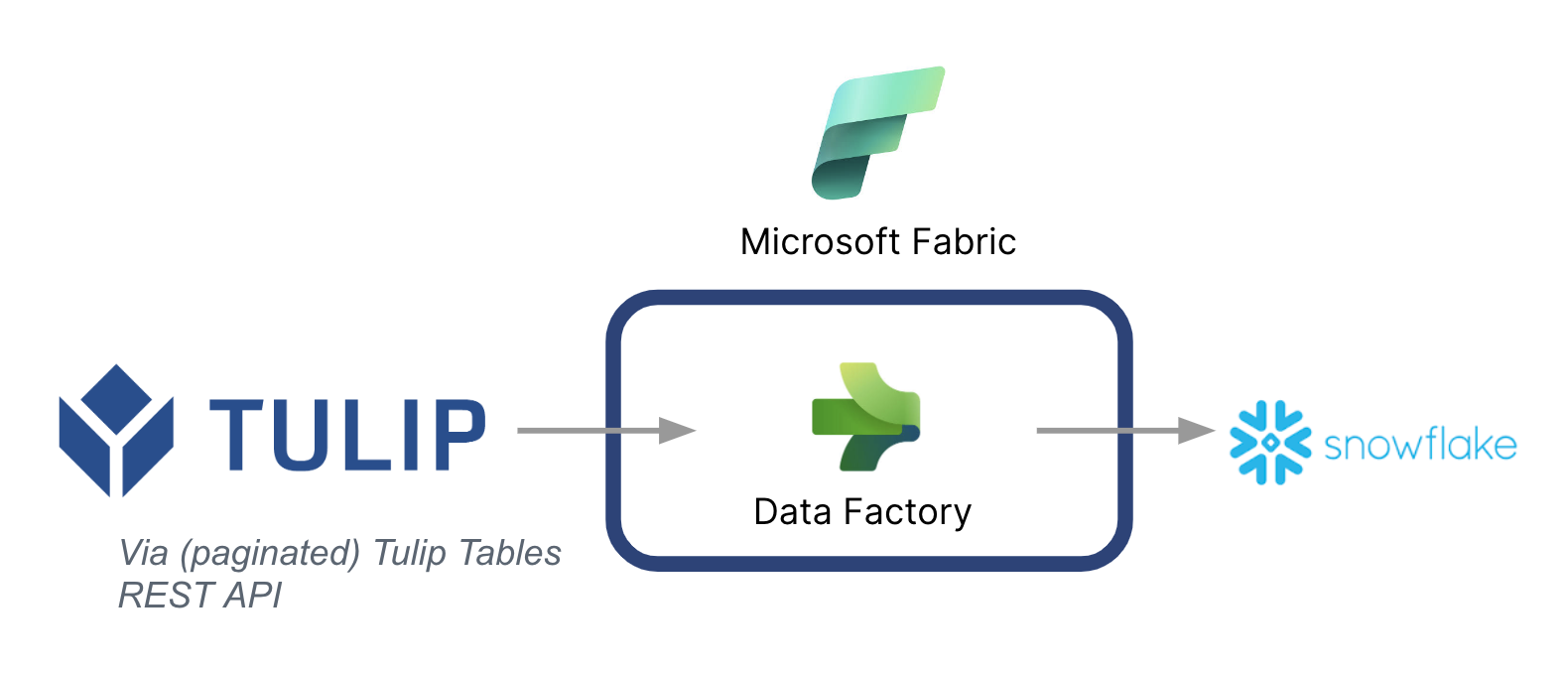
È fondamentale notare che Microsoft può essere utilizzata come pipeline di dati per sincronizzare i dati da Tulip ad altre fonti di dati, anche non Microsoft.
Contesto di Microsoft Fabric
Microsoft Fabric include tutti gli strumenti rilevanti per l'ingestione, l'archiviazione, l'analisi e la visualizzazione dei dati end-to-end.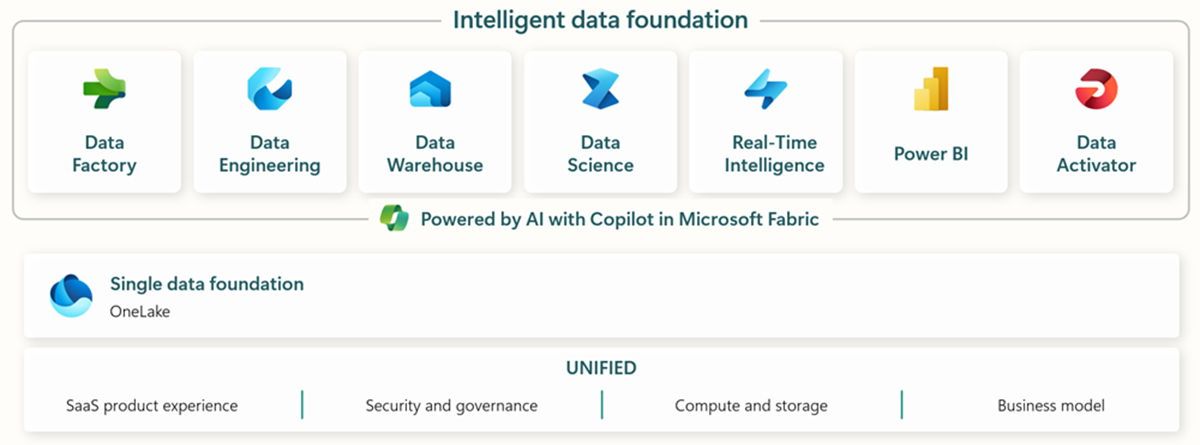
Iservizi specifici sono riassunti di seguito:* Data Factory - ingerire, copiare o estrarre dati da altri sistemi * Data Engineering - trasformare e manipolare i dati * Data Warehouse - archiviare i dati in un Data Warehouse SQL * Data Science - analizzare i dati con notebook ospitati * Real Time Analytics - utilizzare strumenti di analisi e visualizzazione in streaming in un unico framework di Fabric * PowerBI - abilitare gli approfondimenti aziendali con PowerBI per la business intelligence
Per ulteriori informazioni su Microsoft Fabric, consultate questo link.
Tuttavia, alcune funzionalità specifiche possono essere utilizzate anche in combinazione con altri cloud di dati. Ad esempio, Microsoft Data Factory può funzionare con i seguenti data store non Microsoft: * Google BigQuery * Snowflake * MongoDB * AWS S3
Per ulteriori informazioni, consultate questo link
Creazione di valore
Questa guida presenta un modo semplice per recuperare in batch i dati da Tulip a Snowflake per un'analisi più ampia a livello aziendale. Se si utilizza Snowflake per archiviare altri dati aziendali, questo può essere un ottimo modo per contestualizzarli con i dati provenienti dall'officina e prendere decisioni migliori basate sui dati.
Istruzioni per la configurazione
Creare una pipeline di dati su Data Factory (In Fabric) e rendere l'origine REST e la destinazione Snowflake
Configurazione della sorgente:
- Nella homepage di Fabric, andare a Data Factory
- Creare una nuova pipeline di dati su Data Factory
- Iniziare con il "Copy Data Assistant" per semplificare il processo di creazione.
- Dettagli dell'assistente alla copia dei dati:
- Origine dei dati: REST
- URL di base: https://[instance].tulip.co/api/v3
- Tipo di autenticazione: Base
- Nome utente: Chiave API di Tulip
- Password: Segreto API di Tulip
- URL relativo: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Richiesta: GET
- Nome opzione di paginazione: QueryParameters.{offset}
- Valore opzione di paginazione: RANGE:0:10000:100
- Nota: se necessario, il limite può essere inferiore a 100, ma l'incremento nella paginazione deve corrispondere.
- Nota: il valore di paginazione per l'intervallo deve essere maggiore del numero di record della tabella.
Configurazione del lavandino (destinazione):
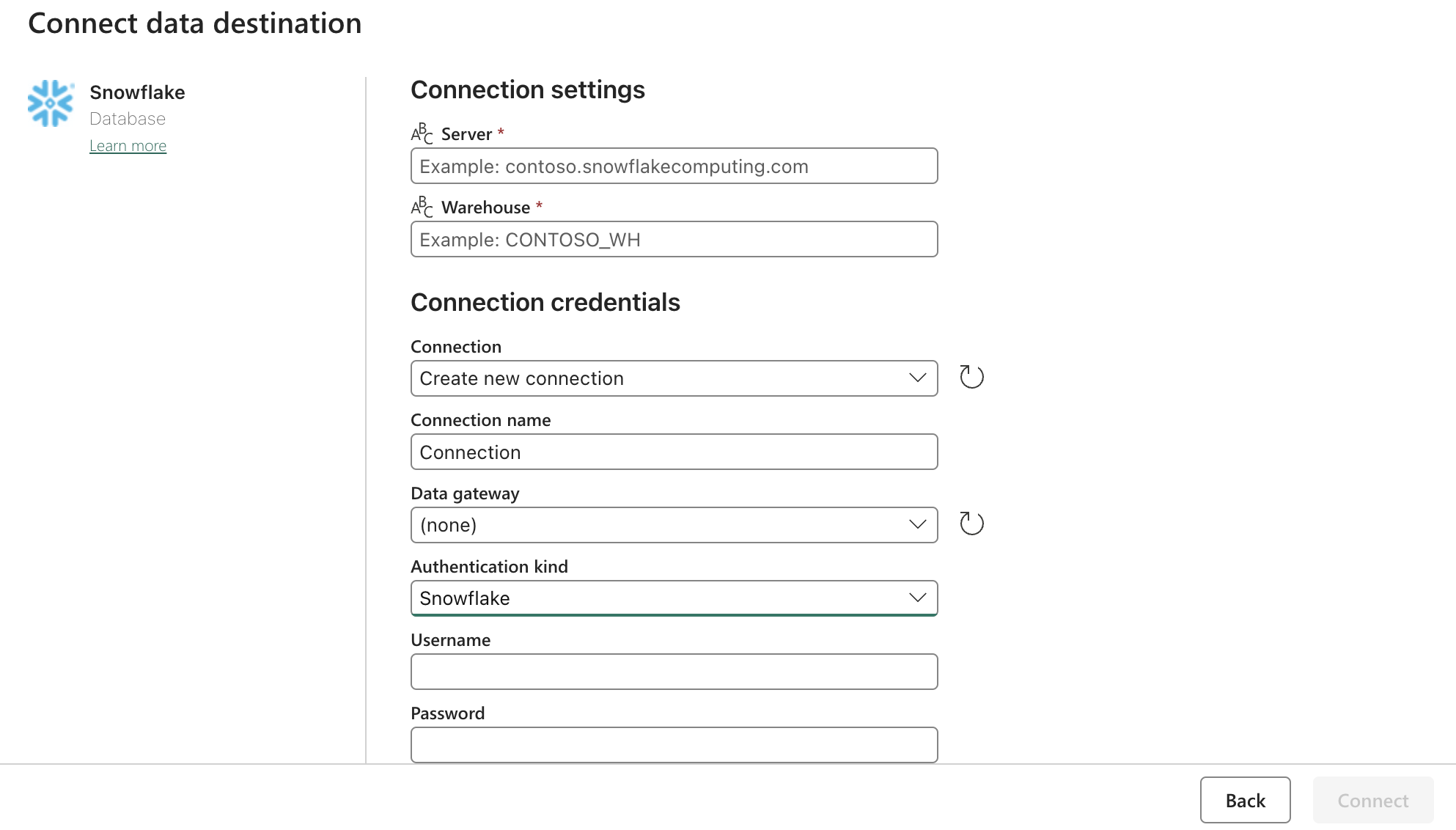
Aggiornare le impostazioni di Snowflake OAuth2.0 con il modulo precedente. Quindi configurare i trigger in base a un'azione pertinente, manuale o a un timer.
Passi successivi
Una volta fatto questo, esplorare ulteriori funzionalità come la pulizia dei dati all'interno del fabric utilizzando i flussi di dati. In questo modo è possibile ridurre gli errori dei dati prima di caricarli in altri luoghi, come Snowflake.