
简化从 Tulip 到 Snowflake 的数据获取,以获得更广泛的分析和集成机会
目的
本指南逐步介绍如何通过 Microsoft Fabric(Azure 数据工厂)将数据从 Tulip 表提取到 Snowflake。
下面列出了一个高级架构: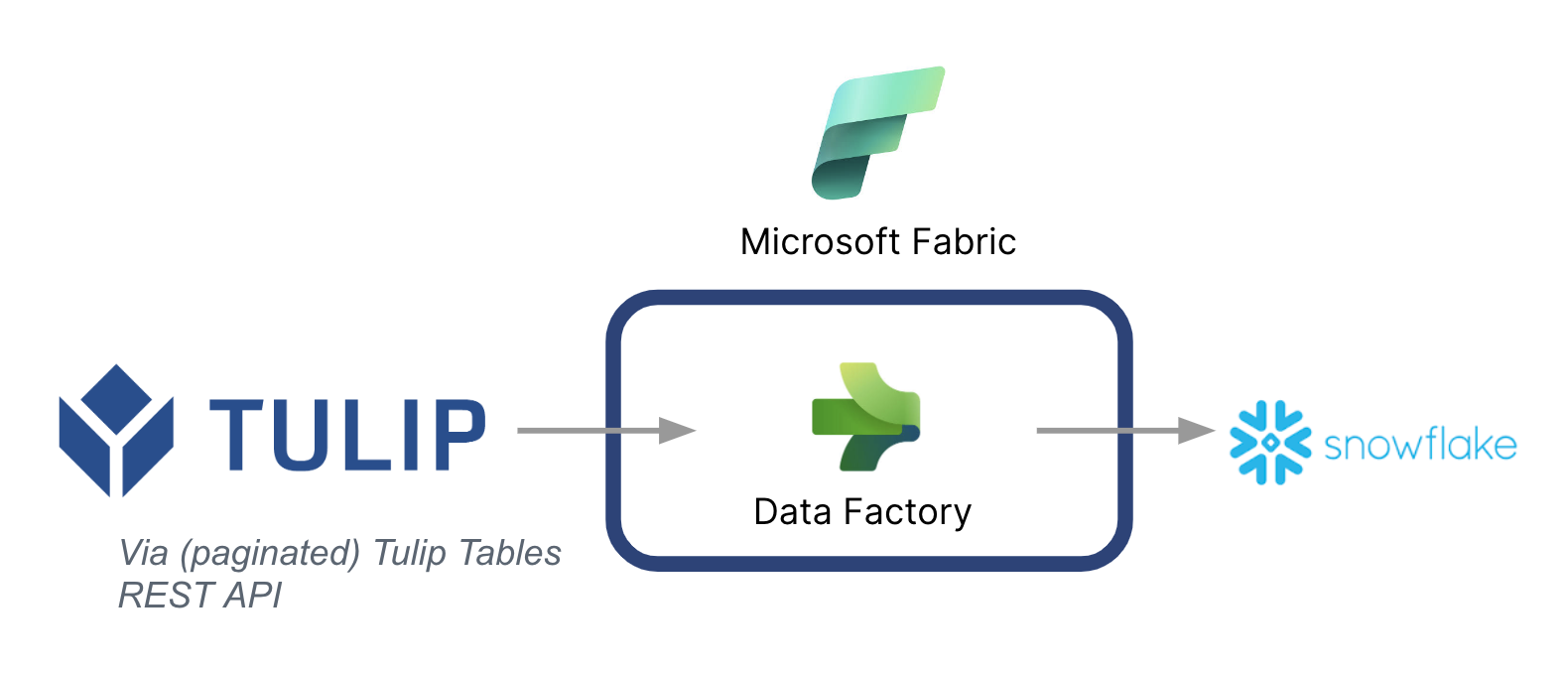
需要注意的是,Microsoft 可用作数据管道,将数据从 Tulip 同步到其他数据源(甚至非 Microsoft 数据源)。
Microsoft Fabric 上下文
Microsoft Fabric 包括用于端到端数据摄取、存储、分析和可视化的所有相关工具。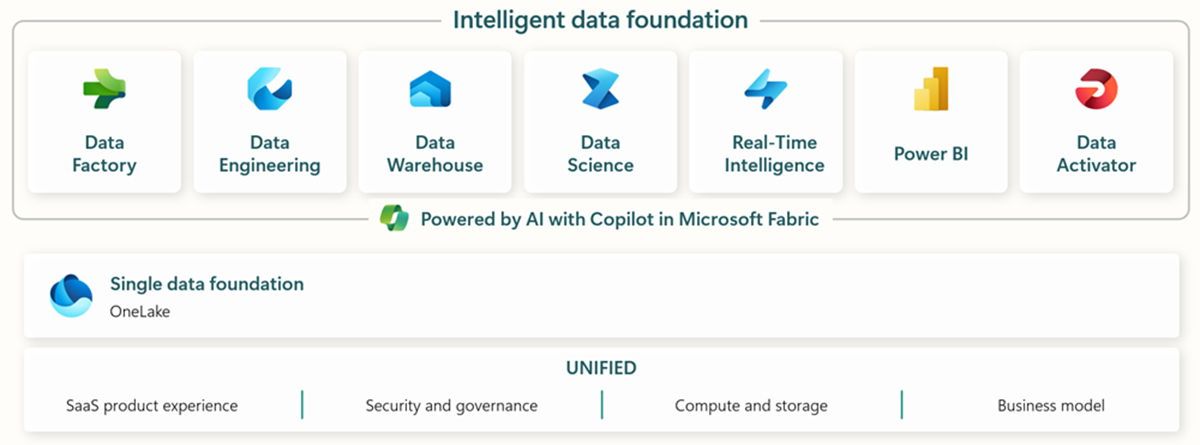
具体服务概述如下:* 数据工厂--从其他系统中摄取、复制或提取数据 * 数据工程--转换和处理数据 * 数据仓库--在 SQL 数据仓库中存储数据 * 数据科学--使用托管笔记本分析数据 * 实时分析--在 Fabric 的单一框架下使用流分析和可视化工具 * PowerBI--使用用于商业智能的 PowerBI 实现企业洞察力
有关 Microsoft Fabric 的更多信息,请查看此链接。
不过,特定功能也可以与其他数据云结合使用。例如,Microsoft Data Factory 可以与以下非微软数据存储协同工作: * Google BigQuery * Snowflake * MongoDB * AWS S3
创造价值
本指南介绍了将数据从 Tulip 批量提取到 Snowflake 以进行更广泛的企业范围分析的简单方法。如果您正在使用 Snowflake 存储其他企业数据,这将是将其与车间数据进行关联以做出更好的数据驱动决策的好方法。
设置说明
在 Data Factory(在 Fabric 中)上创建一个数据管道,并使源为 REST,汇为 Snowflake
源配置:
- 在 Fabric 主页,转到数据工厂
- 在数据工厂上创建新的数据管道
- 从 "复制数据助手 "开始,简化创建流程
- 复制数据助手详细信息:
- 数据源:REST
- 基础 URL: https://[instance].tulip.co/api/v3
- 验证类型: Basic基本
- 用户名: 来自郁金香的 API 密钥
- 密码:来自 Tulip 的 API 密钥
- 相关 URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- 请求:GET
- 分页选项名称:QueryParameters.{offset} 查询参数。
- 分页选项值:range:0:10000:100
- 注意:如果需要,限制可以小于 100,但分页的增量需要匹配
- 注意:范围的分页值必须大于表中的记录数
汇(目的地)配置:
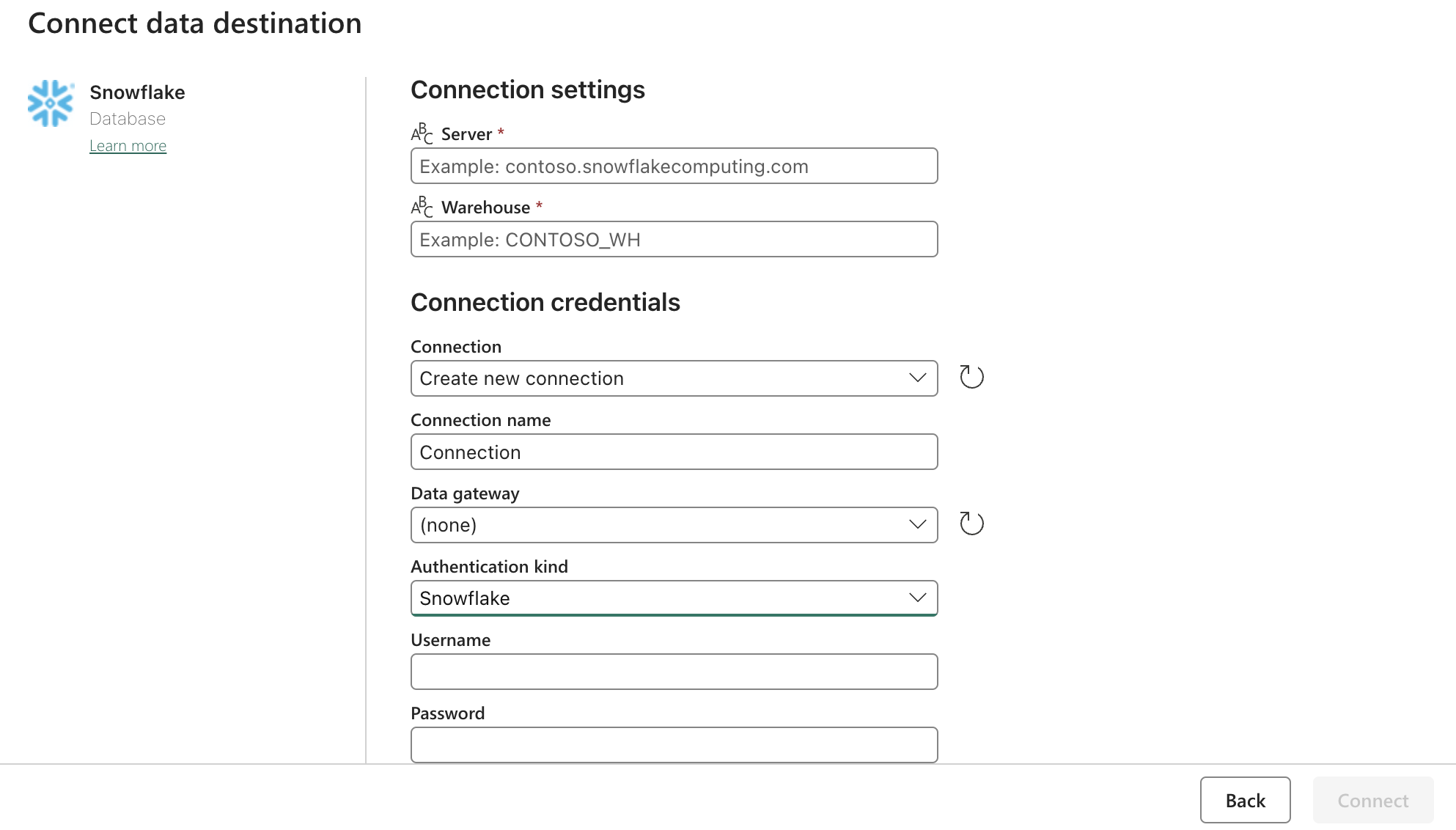
使用上述表格更新 Snowflake OAuth2.0 设置。然后将触发器配置为相关操作、手动或定时器。
下一步
完成上述步骤后,探索其他功能,例如使用数据流在结构内部进行数据清理。这可以在将数据加载到 Snowflake 等其他位置之前减少数据错误。