
Simplifique a obtenção de dados do Tulip para o Snowflake para oportunidades mais amplas de análise e integração
Objetivo
Este guia explica passo a passo como buscar dados das tabelas do Tulip para o Snowflake por meio do Microsoft Fabric (Azure Data Factory).
Uma arquitetura de alto nível está listada abaixo: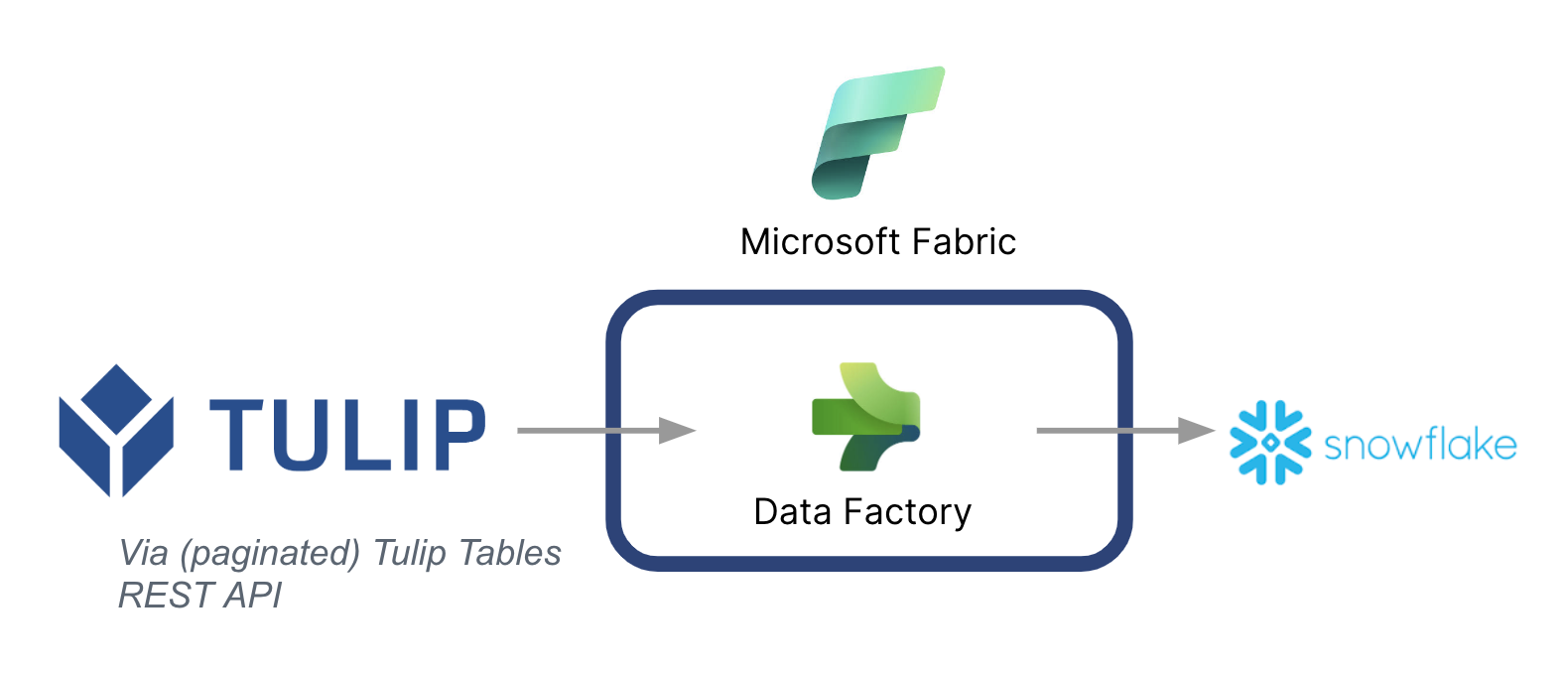
É importante observar que a Microsoft pode ser usada como um pipeline de dados para sincronizar dados do Tulip com outras fontes de dados, inclusive fontes de dados que não sejam da Microsoft.
Contexto do Microsoft Fabric
O Microsoft Fabric inclui todas as ferramentas relevantes para ingestão, armazenamento, análise e visualização de dados de ponta a ponta.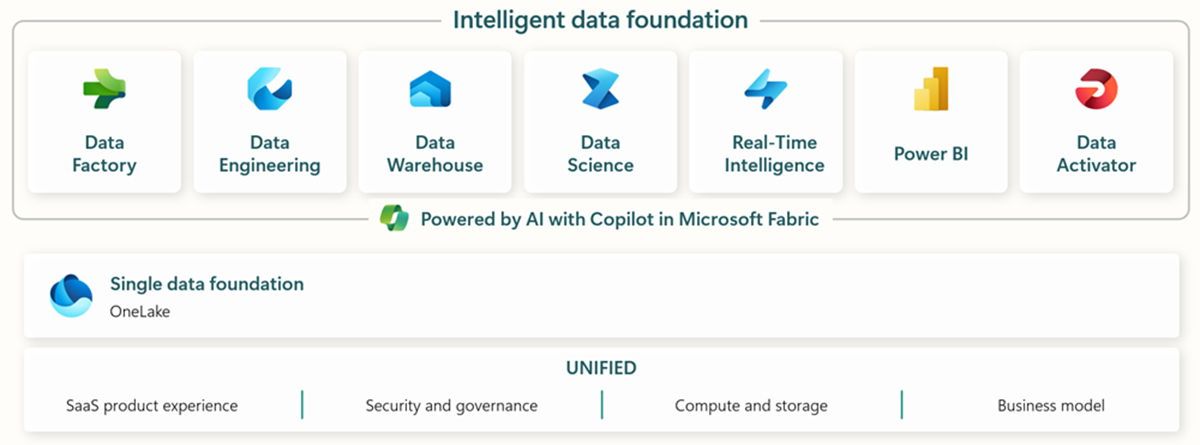
Os serviços específicos estão resumidos a seguir:* Data Factory - ingestão, cópia ou extração de dados de outros sistemas * Data Engineering - transformação e manipulação de dados * Data Warehouse - armazenamento de dados em um SQL Data Warehouse * Data Science - análise de dados com notebooks hospedados * Real Time Analytics - uso de ferramentas de visualização e análise de streaming em uma única estrutura do Fabric * PowerBI - viabilização de insights empresariais com o PowerBI para business intelligence
Confira este link para obter mais informações sobre o Microsoft Fabric
No entanto, recursos específicos também podem ser usados em conjunto com outras nuvens de dados. Por exemplo, o Microsoft Data Factory pode trabalhar com os seguintes armazenamentos de dados que não são da Microsoft: * Google BigQuery * Snowflake * MongoDB * AWS S3
Confira este link para obter mais contexto
Criação de valor
Este guia apresenta uma maneira simples de buscar dados em lote do Tulip para o Snowflake para uma análise mais ampla em toda a empresa. Se você estiver usando o Snowflake para armazenar outros dados corporativos, essa pode ser uma ótima maneira de contextualizá-los com dados do chão de fábrica para tomar melhores decisões baseadas em dados.
Instruções de configuração
Crie um pipeline de dados no Data Factory (In Fabric) e torne a fonte REST e o coletor Snowflake
Configuração da fonte:
- Na página inicial do Fabric, vá para Data Factory
- Crie um novo pipeline de dados no Data Factory
- Comece com o "Copy Data Assistant" para agilizar o processo de criação
- Detalhes do Assistente de cópia de dados:
- Fonte de dados: REST
- URL de base: https://[instance].tulip.co/api/v3
- Tipo de autenticação: Básico
- Nome de usuário: Chave de API da Tulip
- Senha: segredo da API da Tulip
- URL relativo: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Solicitação: GET
- Nome da opção de paginação: QueryParameters.{offset}
- Valor da opção de paginação: RANGE:0:10000:100
- Observação: o limite pode ser menor que 100, se necessário, mas o incremento na paginação precisa corresponder
- Observação: o valor de paginação para o intervalo precisa ser maior do que o número de registros na tabela.
Configuração do Sink (destino):
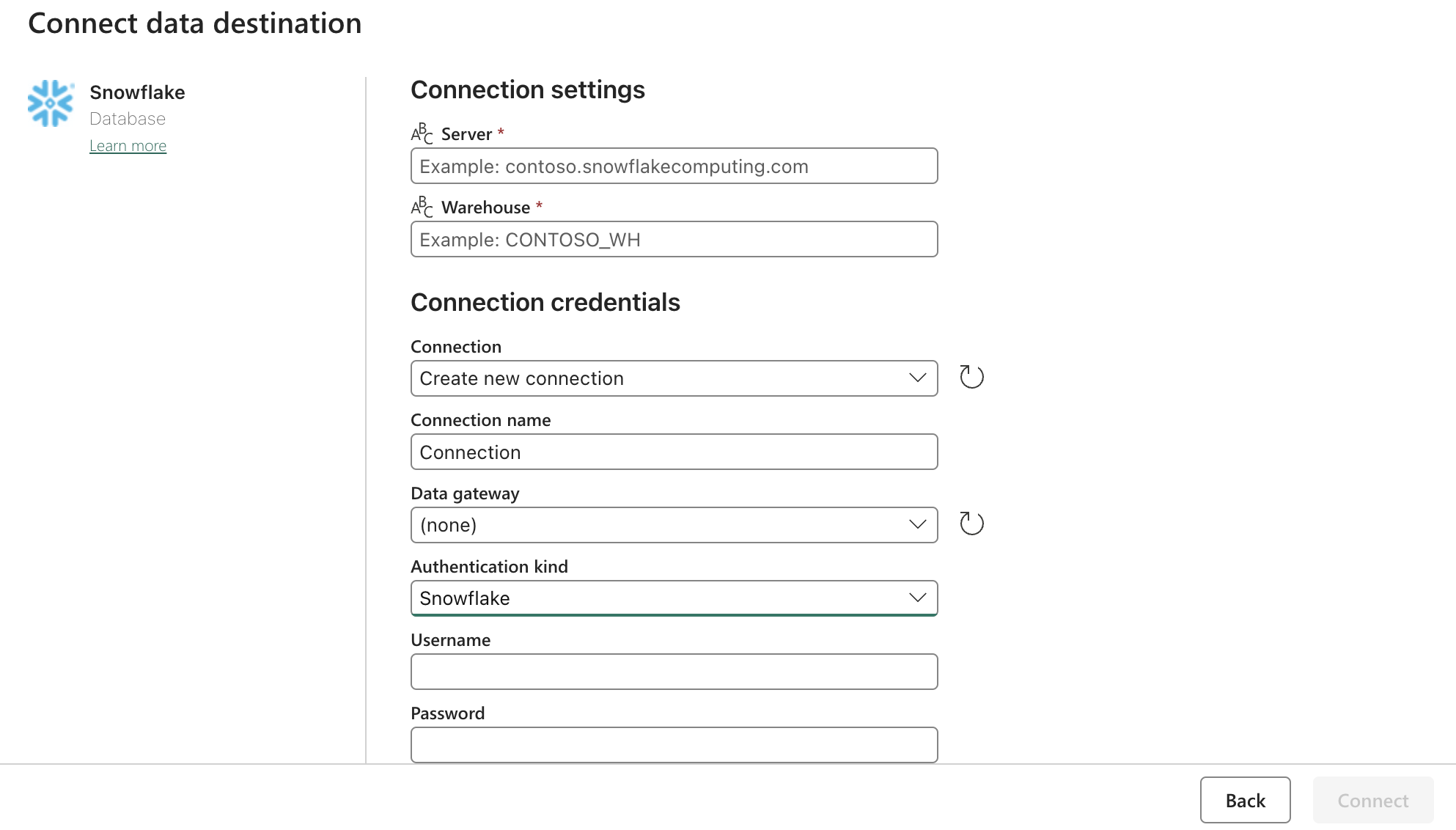
Atualize as configurações do Snowflake OAuth2.0 com o formulário acima. Em seguida, configure os acionadores para que estejam em uma ação relevante, manual ou temporizador.
Próximas etapas
Depois de fazer isso, explore recursos adicionais, como a limpeza de dados dentro da malha usando fluxos de dados. Isso pode reduzir os erros de dados antes de carregá-los em outros locais, como o Snowflake