

Anleitung zur Einhaltung eines Gemeinsamen Datenmodells und Beispiele für die Erstellung eines solchen.
Was ist ein gemeinsames Datenmodell?
Anwendungen können kombiniert werden, um Anwendungsfälle zu lösen, indem sie mit Hilfe von Tabellen im Tulip Common Data Model for Discrete{target=_blank} oder Common Data Model for Pharma über Herstellungsprozesse hinweg verbunden werden. Im Gegensatz zu traditionellen Datenmodellen, die auf Abhängigkeiten beruhen, ermöglicht das komponierbare Common Data Model von Tulip das Hinzufügen von Tabellen im Laufe der Zeit auf einer Fall-zu-Fall-Basis.
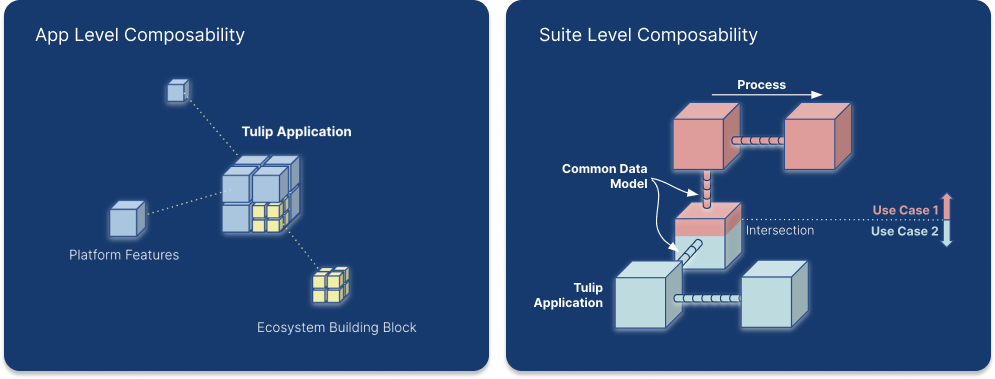
Ein Common Data Model bietet eine Sammlung von standardisierten und erweiterbaren Datenschemata. Diese vordefinierten Schemata decken verschiedene Datentypen ab, darunter operative Artefakte, physische Artefakte, Referenzmaterialien und Ereignisprotokolle. Durch die Darstellung weit verbreiteter Konzepte und Aktivitäten wie Arbeitsaufträge und Einheiten erleichtern diese Schemata das Erstellen, Zusammenstellen und Analysieren von Daten. Diese Standardisierung trägt zur Rationalisierung der Datenverarbeitung in verschiedenen Systemen bei.
Gemeinsames Datenmodell in Composability
Tulip-Tabellen spielen eine entscheidende Rolle bei der Handhabung von Datenflüssen und der Aufrechterhaltung der Verbindung zwischen Anwendungen. Sie enthalten Informationen, die in den Anwendungen angezeigt werden, und die Anwendungen erstellen, aktualisieren und löschen Tabellensätze. Wenn mehrere Anwendungen die gleichen Tabellen verwenden, können sie über Tabellen miteinander kommunizieren.
Zum Beispiel erstellt ein Manager einen Arbeitsauftrag in einer Anwendung und ein Operator führt diesen Arbeitsauftrag in einer anderen Anwendung oder einem Satz von Anwendungen aus.
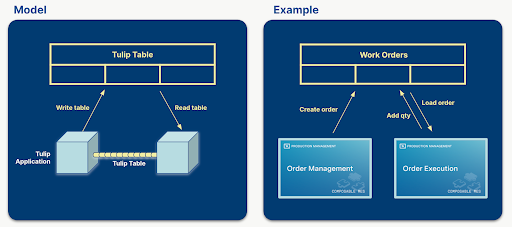
Beim Entwurf einer Lösung für ein bestimmtes Problem ist die Definition der zu verwendenden Tabellen einer der wichtigsten Schritte. Die logische Auswahl von Tabellen kann zu einer einfacheren, wiederverwendbaren und kompatiblen Anwendung führen. Wenn die richtige Menge an Daten in Tabellen gespeichert wird, kann der App-Builder die Anzahl der verwendeten App-Variablen reduzieren, wodurch die Anwendung weniger komplex wird und leicht angepasst werden kann. Wenn die Anwendungen innerhalb einer Lösung denselben Satz von Tabellen verwenden, werden die Anwendungen austauschbar oder zusammensetzbar, ohne dass die eine oder andere Anwendung neu gestaltet werden muss.
Bewährte Praktiken
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Tulip-Tabellen sollten in erster Linie dem Modell des Digitalen Zwillings folgen, d.h. die Tabellen sollten die physische Anlage oder die Produktionsstätte so genau wie möglich widerspiegeln. Historische Anwendungsdaten sollten sich auf Abschlusssätze beschränken, um sicherzustellen, dass Tabellen nicht zur Speicherung von Stammdaten oder doppelten Daten aus Abschlusssätzen oder externen Datensätzen verwendet werden.
Primäre Tabellentypen
Idealerweise sollten die Tabellen physische und betriebliche Artefakte darstellen.
Diese Tabellen werden immer ein Statusfeld enthalten, das regelmäßig von Anwendungen aktualisiert wird.
Das nachstehende Diagramm zeigt die vollständigen Tabellen im Gemeinsamen Datenmodell und welche Tabellen für diskrete Fertigungs- und Pharmazieanwendungen zu verwenden sind.
Hier finden Sie eine Aufschlüsselung aller Tabellentypen im Common Data Model:
Physische Artefakte
Physische Artefakte sind greifbare Objekte in Ihrer Anlage oder Komponenten, die während des Betriebs verwendet oder produziert werden. Wenn sich der Zustand eines physischen Artefakts ändert oder aktualisiert wird, spiegelt sich diese Änderung im Datensatz wider (z. B. Statusänderung).
Es gibt zwei Kategorien von physischen Artefakten:
1. AssetsAssetsumfassen Komponenten, die einen Prozess ausstatten, beinhalten oder durchführen, wie z. B.: * Ausrüstungsgegenstände * Waagen * Standorte
2. MaterialienMaterialiensind Gegenstände, die in einem Prozess verwendet oder erzeugt werden, wie z. B.: * Inventargegenstände * Einheiten * Chargen
Operative Artefakte
Operative Artefakte sind materielle oder immaterielle Elemente oder Komponenten, die Operationen ermöglichen oder unterstützen.
Es gibt drei Kategorien von betrieblichen Artefakten:
1. AufgabenAufgabenbeinhalten einen umsetzbaren Prozess, wie z. B.: * Inspektionsergebnisse * Kanban-Karten
2. EreignisseEreignissebeinhalten etwas, das passiert ist, wie z.B.: * Defekte * Korrekturen
3. AufträgeAufträgeenthalten Informationen über Waren oder Aufträge, wie z. B.: * Arbeitsaufträge * Prozessaufträge
Sekundäre (erweiterte) Tabellentypen
Es gibt Situationen, in denen Sie von bewährten Verfahren abweichen müssen. Unter fortgeschrittenen Umständen - und so sparsam wie möglich - müssen Sie vielleicht die folgenden zwei sekundären Tabellentypen verwenden:
- Protokoll
- Referenz
Die Daten in diesen Tabellen werden wahrscheinlich statisch sein und nicht aktualisiert werden (weshalb es vorzuziehen ist, diese Arten von Daten entweder in Abschlussdatensätzen oder im ursprünglichen, externen System zu speichern).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Protokolle
Ereignisprotokolle sind Informationen, die nachgeschlagen werden können und etwas in der Produktion definieren. Sie befinden sich oft in externen Systemen wie einem ERP-System. Da historische Daten traditionell über App Completion verfolgt und in Completion Records gespeichert werden, brauchen Sie eine Log-Tabelle NUR dann zu verwenden, wenn:* Sie bestimmte Daten zu Visualisierungszwecken von den Completion Records trennen müssen* Sie diese Daten in Berechnungen verwenden müssen, insbesondere in Abfragen und Aggregationen
Beispiele:
- Notizen und Kommentare
- Genealogie-Datensätze
- Historie der Stationsaktivitäten
- Inspektionsergebnisse
Sie sollten NICHT auf Protokolltabellen zurückgreifen für:* Historische Aufzeichnungen* Rückverfolgbarkeit
Referenzen
Referenzen sind gemeinsam genutzte Hauptbücher zwischen Anwendungen. Sie ähneln dem Konzept eines Abschlussdatensatzes, mit dem Unterschied, dass sie anwendungsübergreifend genutzt werden und den Zugriff auf Tabellenabfragen, Aggregations und die Veränderbarkeit von Tulip-Tabellen ermöglichen.
Wo immer es möglich ist, sollten Daten in Echtzeit direkt von der ursprünglichen Quelle - z.B. einem ERP - über einen HTTP-Connector abgerufen werden. Es kann sein, dass Sie eine Referenztabelle in Randfällen verwenden müssen, wie z.B.:* Vorübergehend, während Sie eine Verbindung zu einem ERP aufbauen.* Wenn Ihr externes System begrenzte Referenzdaten enthält, die mit Tulip ergänzt werden müssen.
Ihre Herangehensweise wird sich im Laufe der Zeit weiterentwickeln, wenn die Lösungen ausgereift sind und die Systeme stärker integriert und eng gekoppelt werden.
Beispiele:
- Material-Definitionen
- Stückliste
Erstellen Sie Ihr eigenes Common Data Model
Das Beispiel des Gemeinsamen Datenmodells von Tulip ist als Ausgangspunkt für den Aufbau Ihres Datenmodells gedacht. Alle Prozesse und Lösungen sind jedoch unterschiedlich, und wie die Anwendungen kann auch das Datenmodell nach Bedarf angepasst werden.
Kleinere Änderungen umfassen das Hinzufügen und Entfernen von Feldern in den Tabellen. In einigen Fällen (spezielle Prozesse, mehrere Tabellen für denselben Anwendungsfall) sind größere Änderungen erforderlich. Dies kann durch Ersetzen einer oder mehrerer Tabellen aus dem heruntergeladenen Datenmodell oder durch Einfügen zusätzlicher Tabellen geschehen.
Planung eines gemeinsamen Datenmodells
- Definieren Sie die physischen und operativen Artefakte Ihres Prozesses
- Finden Sie die entsprechenden Tabellen für jedes Artefakt
- Untersuchen Sie die Datentypen, die von den Anwendungen erfasst werden sollen, und die Referenzen, die verwendet werden müssen.