
Rationalisierung des Abrufs von Daten von Tulip zu AWS S3 für umfassendere Analysen und Integrationsmöglichkeiten
Zweck
Diese Anleitung zeigt Schritt für Schritt, wie man alle Tulip-Tabellen-Daten über eine Lambda-Funktion abruft und in einen S3-Bucket schreibt.
Dies geht über die grundlegende Abfrage hinaus und iteriert durch alle Tabellen in einer bestimmten Instanz; dies kann für einen wöchentlichen ETL-Job (Extract, Transform, Load) sehr nützlich sein.
Die Lambda-Funktion kann über eine Vielzahl von Ressourcen wie Event Bridge-Timer oder ein API-Gateway ausgelöst werden.
Eine Beispielarchitektur ist unten aufgeführt: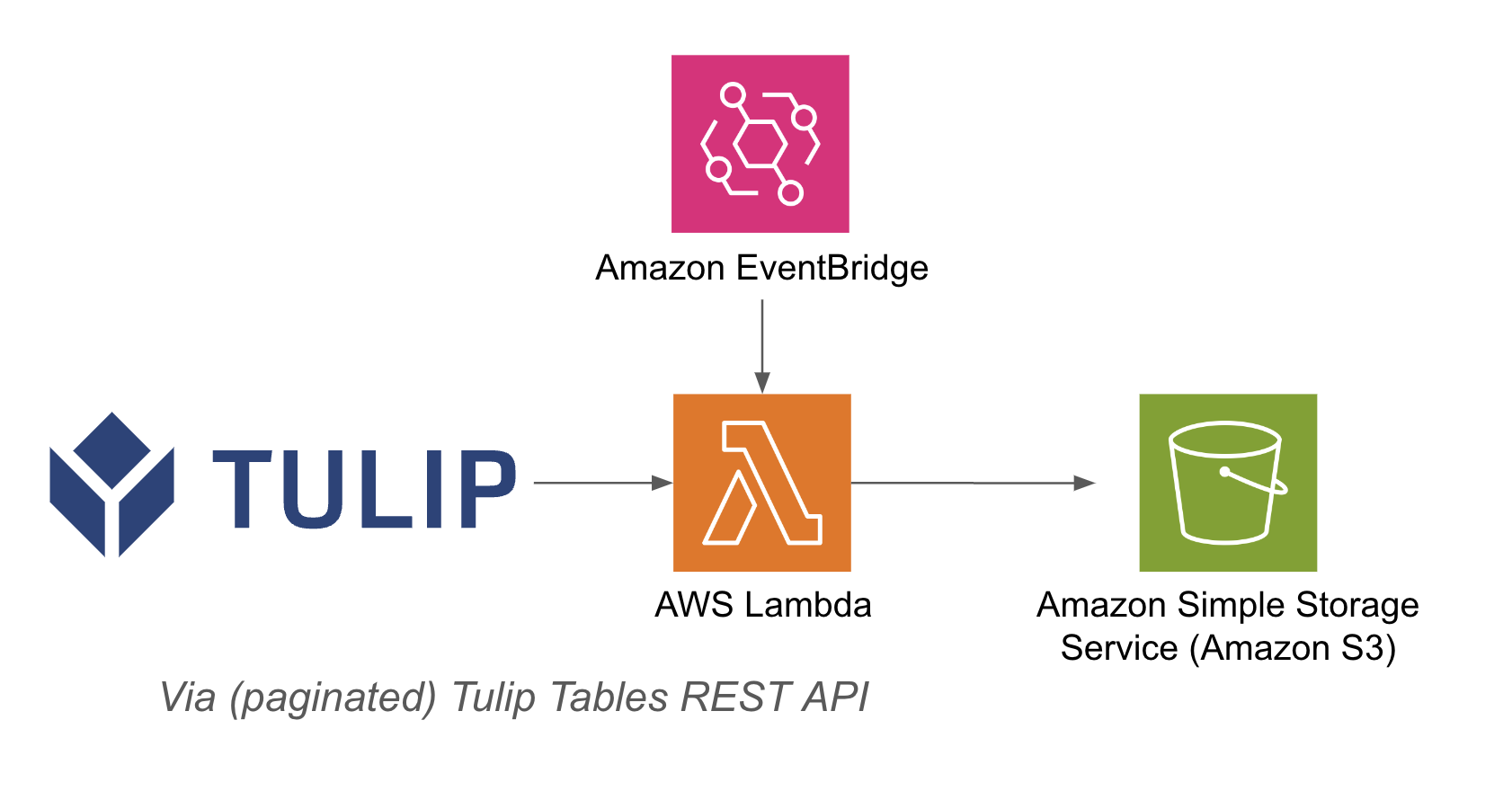
Einrichtung
Dieses Integrationsbeispiel erfordert Folgendes:
- Verwendung von Tulip Tables API (API-Schlüssel und Geheimnis in den Kontoeinstellungen abrufen)
- Tulip Table (Holen Sie sich die Unique ID der Tabelle
Schritte auf hoher Ebene:1. eine AWS Lambda Funktion mit dem entsprechenden Trigger (API Gateway, Event Bridge Timer, etc.) erstellen2. sicherstellen, dass die 3. die Daten der Tulip Tabelle mit dem folgenden Beispiel abrufen```pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os
# Ermitteln des aktuellen Zeitstempels für eindeutige Dateinamen
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# Funktion zur Umwandlung von Dictionaries in Strings
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# Funktion erstellen
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# Write DataFrame to S3 as CSVwr.s3.to_csv( df=df, path=path, index=False)print(f "Wrote {table} to {path}")return f "Wrote {table} to {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# Tabelle abfragen functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')}
## Anwendungsfälle und nächste Schritte
Sobald Sie die Integration mit Lambda abgeschlossen haben, können Sie die Daten einfach mit einem Sagemaker-Notebook, QuickSight oder einer Vielzahl anderer Tools analysieren.
**1. Fehlervorhersage -** Erkennen von Produktionsfehlern, bevor sie auftreten, und Steigerung der Fehlerquote beim ersten Mal - Identifizieren der wichtigsten Qualitätsfaktoren in der Produktion, um Verbesserungen zu implementieren
**2. Optimierung der Qualitätskosten -** Identifizierung von Möglichkeiten zur Optimierung des Produktdesigns ohne Beeinträchtigung der Kundenzufriedenheit
**3. Energieoptimierung in der Produktion -** Identifizierung von Produktionshebeln zur Optimierung des Energieverbrauchs
**4. Liefer- und Planungsvorhersage und -optimierung -** Optimierung des Produktionsplans auf der Grundlage der Kundennachfrage und des Echtzeit-Auftragsplans
**5. Globales Maschinen-/Linien-Benchmarking -** Benchmarking ähnlicher Maschinen oder Anlagen mit Normalisierung
**6. Globales/regionales digitales Leistungsmanagement -** Konsolidierte Daten zur Erstellung von Echtzeit-Dashboards