
Rationalisierung der Tulip-Datentechnik mit Fivetran-Integration
Zweck
Rationalisierung der Datenentwicklungspipelines mit Tulip ermöglicht die Nutzung von Daten aus Tulip-Tabellen im gesamten Unternehmen
Einrichtung
Für die Einrichtung ist Folgendes erforderlich: * Fivetran-Konto (kostenlose Version ist verfügbar) * AWS (oder ein anderes Cloud-Konto) * Datenbank oder Data Warehouse für den Empfang von Tulip Tables-Daten * Gute Python-Kenntnisse
Wie es funktioniert
Die Einrichtung der Fivetran-Automatisierung erfolgt in den folgenden Schritten:
- Fivetran-Konto einrichten
- Ziel erstellen (z.B. Snowflake)
- Erstellen einer Connector-Funktion mit AWS Lambda-Funktion
- AWS Lambda-Funktion erstellen
- Fertigstellung der Connector-Funktion
- Fivetran-Konnektor testen und Aktualisierungshäufigkeit anpassen
Fivetran verwendet die Lambda-Funktion, um die Daten der Tulip-Tabellen automatisch nach einem bestimmten Zeitplan abzurufen und die Zieldatenbanken oder Data Warehouses zu aktualisieren. Das mitgelieferte Beispiel ist eine einfache Funktion, die die Tabelle mit neuen, aktualisierten Daten neu schreibt. Für verbesserte ereignisbasierte Auslöser können zusätzliche Funktionen hinzugefügt werden.
Anweisungen zur Einrichtung
Fivetran-Konto einrichten
Zunächst müssen Sie ein Fivetran-Konto einrichten. Es wird eine kostenlose Version mit einer begrenzten Anzahl von Aktualisierungen pro Monat angeboten.
Ziel einrichten
Klicken Sie dann auf Destinationen und erstellen Sie Ihr erstes Ziel. Dies ist im Wesentlichen die Datenbank oder das Data Warehouse, das die Daten aus den Tulip-Tabellen erhalten soll.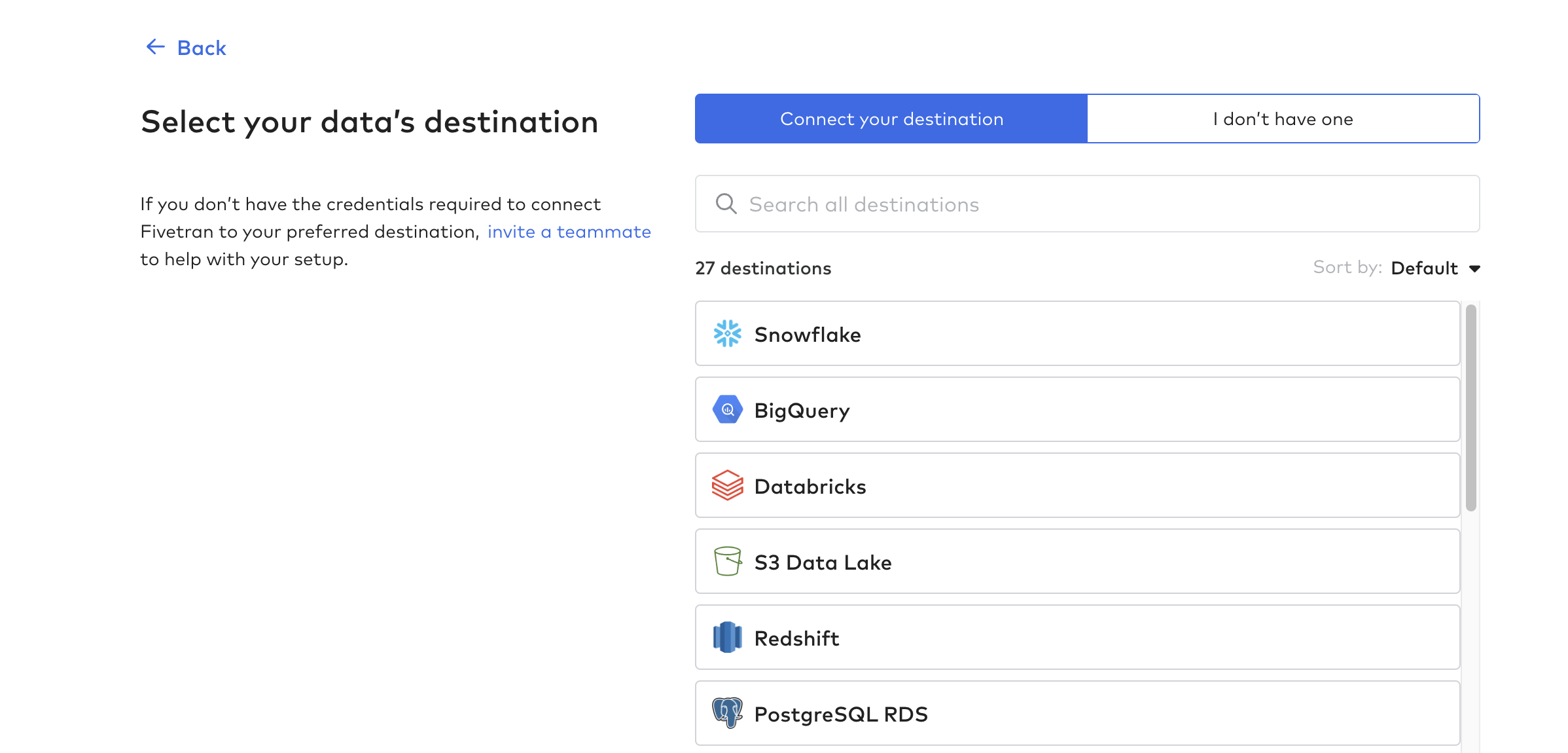
Konnektor-Funktion erstellen
Erstellen Sie dann die Konnektor-Funktion; dies ist der Prozess zur Automatisierung der Datenpipeline von Tulip. Sie können eine beliebige Cloud-Funktion wie AWS Lambda, Azure Functions oder GCP Cloud Functions verwenden. Für dieses Beispiel werden wir AWS Lambda verwenden.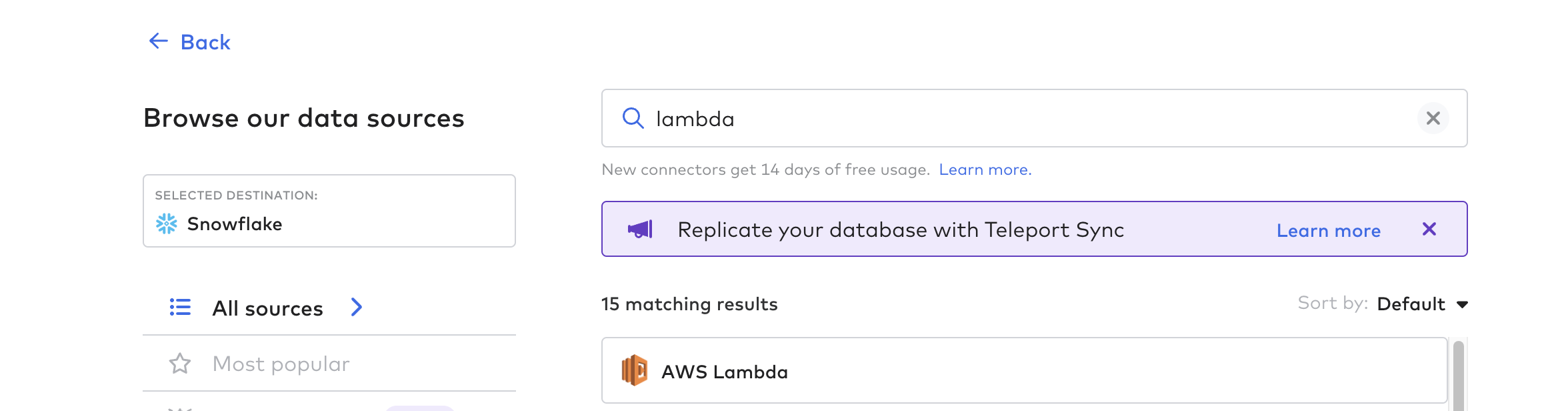
Befolgen Sie die Anweisungen von in-Fivetran zur Erstellung einer Lambda-Funktion auf AWS mit den entsprechenden Rollen und BerechtigungenSiehe Link für die Lambda-Funktionsvorlage als AusgangspunktIm Folgenden finden Sie einige hilfreiche Tipps:
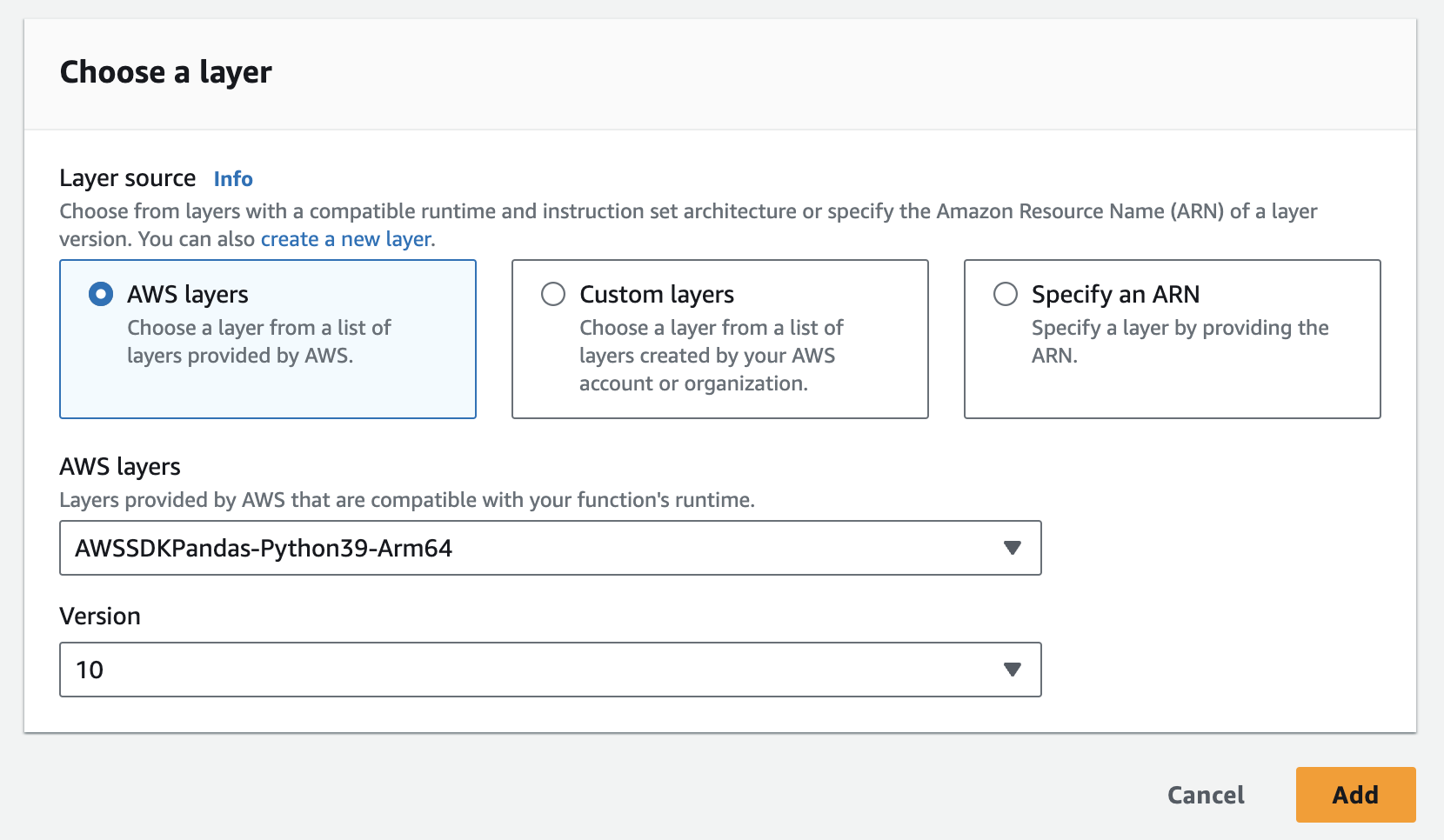
- Sie müssen zwei Ebenen erstellen: eine für die Tulip-Bibliothek, die andere für die Pandas-Bibliothek
- Sie können die Tulip Community API hier einsehen
- Sie können die Zip-Datei alternativ hier herunterladen (Diese wurde für das Hinzufügen zu einer Ebene vorbereitet
- Sie können die Pandas-Ebene in AWS ganz einfach wie folgt hinzufügen
- Sie müssen die Instanz, den API-Schlüssel und das API-Geheimnis als Umgebungsvariablen in die Lambda-Funktion einfügen. Möglicherweise müssen Sie die Laufzeiteinstellungen aktualisieren, um die Timeout-Zeit und den verwendeten Speicher zu erhöhen. Screenshot unten für die Aktualisierung der Konfiguration
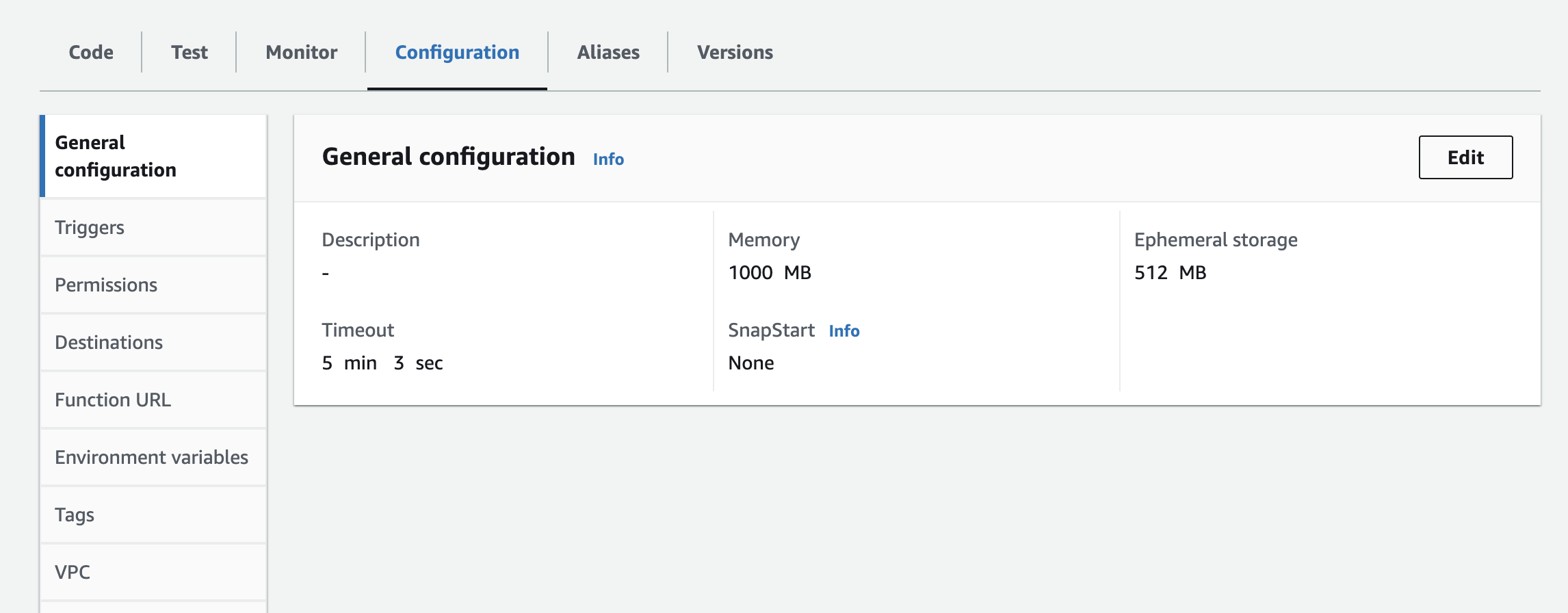
Nächste Schritte
Sobald die Konnektorfunktion funktioniert, können Sie die Aktualisierungshäufigkeit anpassen, die Informationen der Tulip-Tabellen in der Zieldatenbank oder im Data Warehouse anzeigen und weitere Funktionen nutzen
Einige spezifische Anwendungsfälle für diese Datenpipeline: * Analysen auf Unternehmensebene und Datenverarbeitung von Tulip-Daten * Batch-Automatisierungen mit Unternehmenssystemen * Kontextualisierung mit Data Warehouses und Data Lakes
Zusätzliche Ressourcen
Wenden Sie sich an Fivetran für zusätzlichen Support hierWendenSie sich an Fivetran für zusätzlichen Support hier * Zusätzlich haben sie ein Formular bereitgestellt, um Anpassungen und Anfragen für eine vereinfachte Integration von Tulip-Tabellen vorzunehmen. Geben Sie hier Ihr Feedback und Ihre Anfrage ein