
TulipからSnowflakeへのデータ取得を合理化し、アナリティクスや統合の機会を拡大
目的
このガイドでは、Microsoft Fabric(Azure Data Factory)を介してTulipテーブルからSnowflakeにデータをフェッチする方法を順を追って説明します。
ハイレベルなアーキテクチャを以下に示します: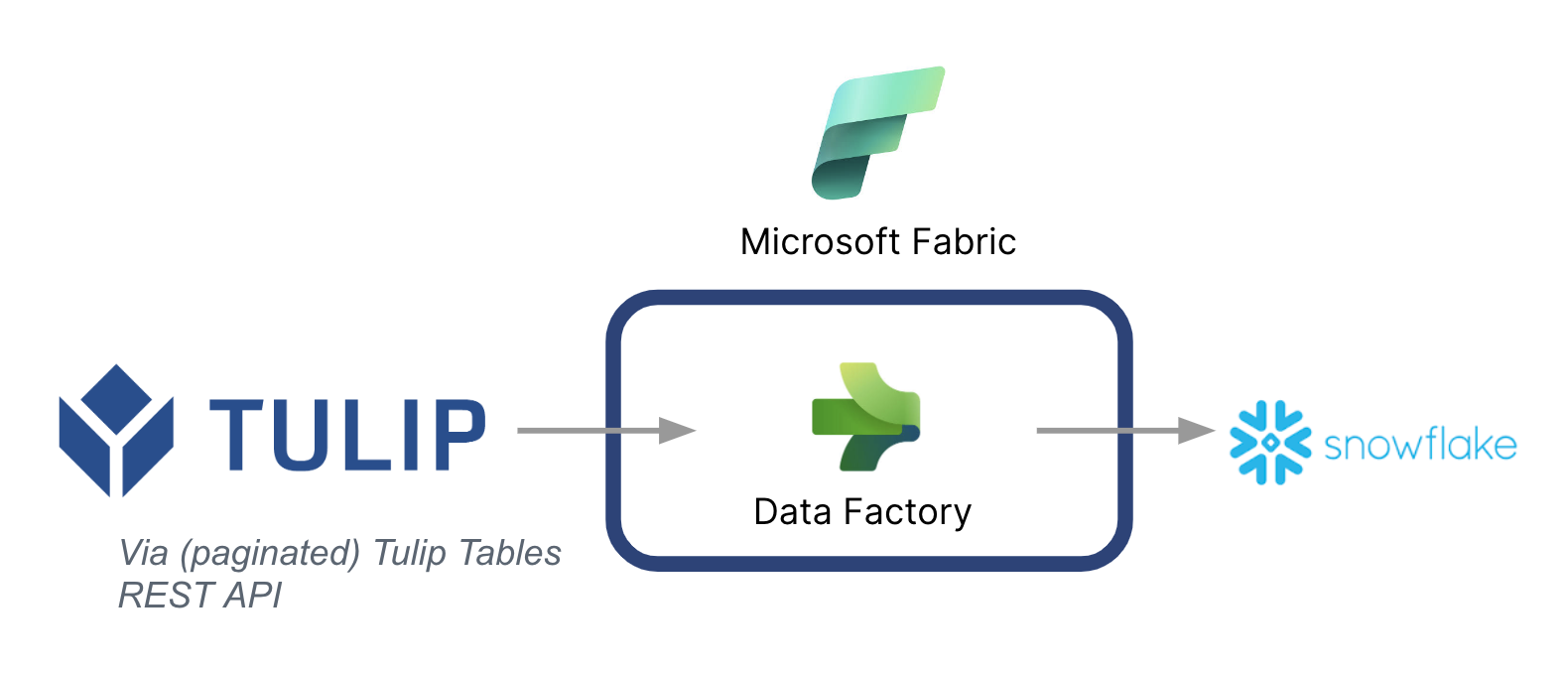
Microsoftは、Tulipから他のデータソースにデータを同期するためのデータパイプラインとして使用できることに注意することが重要です。
Microsoft Fabricのコンテキスト
Microsoft Fabricには、エンドツーエンドのデータ取り込み、保存、分析、可視化のための関連ツールがすべて含まれている。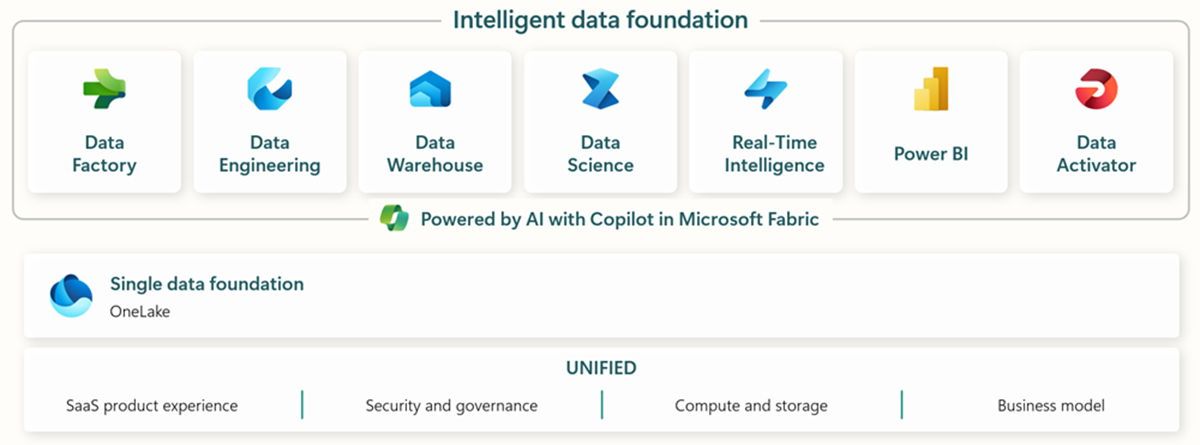
データ・ファクトリ - 他のシステムからのデータの取り込み、コピー、抽出 * データ・エンジニアリング - データの変換と操作 * データ・ウェアハウス - SQLデータ・ウェアハウスにデータを格納 * データ・サイエンス - ホスティングされたノートブックでデータを分析 * リアルタイム・アナリティクス - ファブリックの単一のフレームワークの下でストリーミング・アナリティクスと可視化ツールを利用 * PowerBI - ビジネス・インテリジェンスのためのPowerBIでエンタープライズ・インサイトを実現
Microsoft Fabricの詳細については、こちらのリンクを参照されたい。
しかし、特定の機能を他のデータクラウドと組み合わせて使用することもできる。例えば、Microsoft Data Factoryは、以下のMicrosoft以外のデータストアと連携することができる: * Google BigQuery * Snowflake * MongoDB * AWS S3
価値の創造
このガイドでは、TulipからSnowflakeにデータをバッチフェッチして、より広範な企業規模の分析を行う簡単な方法を紹介します。他の企業データを保存するためにSnowflakeを使用している場合、これは、より良いデータ駆動型の意思決定を行うために、現場からのデータとコンテキスト化するための素晴らしい方法です。
セットアップ手順
Data Factory(ファブリック内)でデータパイプラインを作成し、ソースをREST、シンクをSnowflakeにします。
ソースの設定
- FabricのホームページからData Factoryに移動
- データファクトリーで新しいデータパイプラインを作成する
- 作成プロセスを効率化するために、"Copy Data Assistant "で開始する。
- コピーデータアシスタントの詳細
- データソースREST
- ベースURL: https://[instance].tulip.co/api/v3
- 認証タイプ:Basicベーシック
- ユーザー名:チューリップからのAPIキー
- パスワード: チューリップからのAPIシークレット
- 相対URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- リクエストリクエスト: GET
- ページネーション・オプション名QueryParameters.{offset}
- ページ分割オプション値:範囲:0:10000:100
- 注意: 必要であれば、Limitは100より小さくすることができますが、ページネーションのインクリメントが一致する必要があります。
- 注: 範囲のページネーション値は、テーブルのレコード数より大きくする必要があります。
シンク(デスティネーション)設定
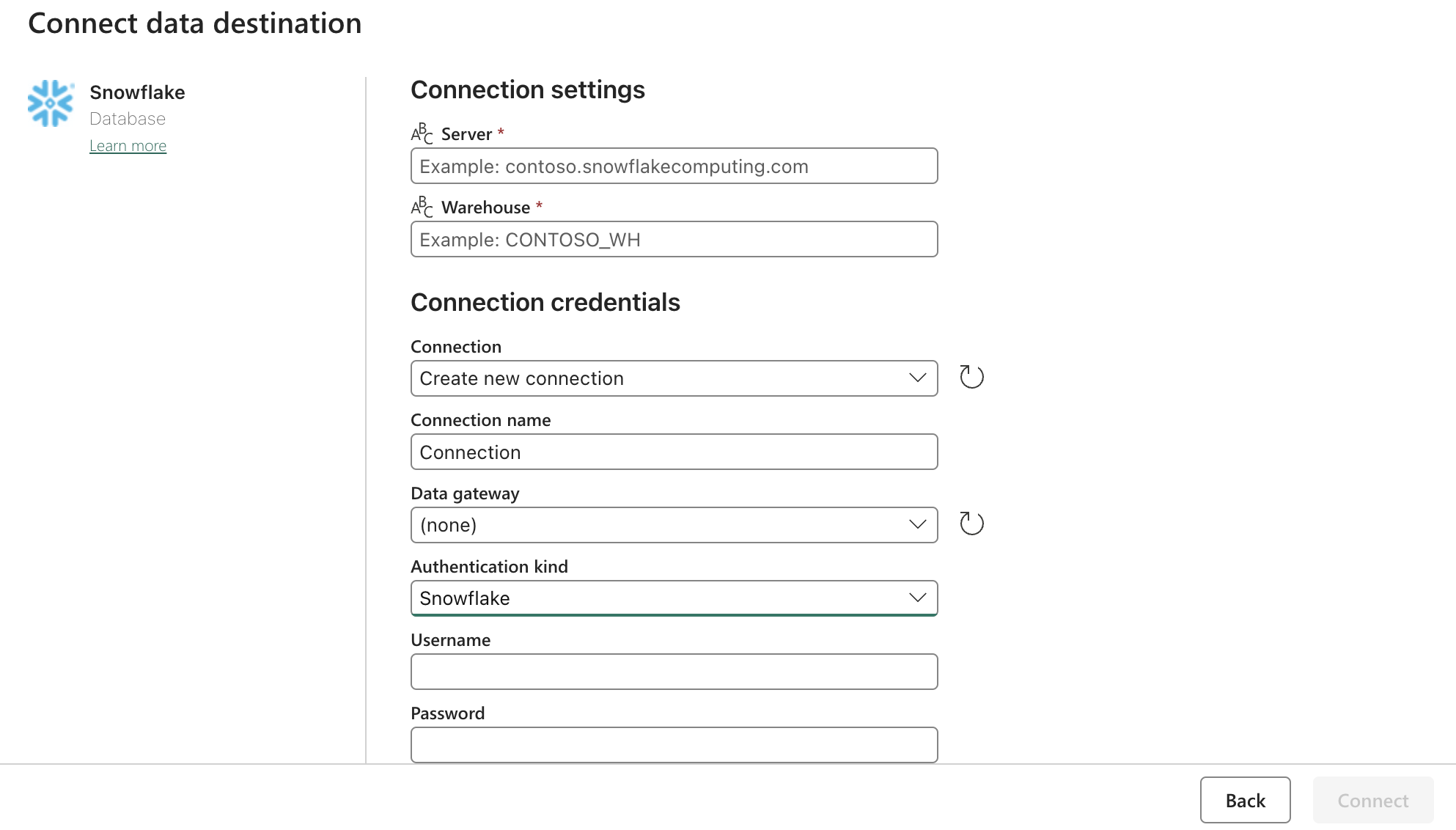
上記のフォームで Snowflake OAuth2.0 の設定を更新します。次に、関連するアクション、手動、またはタイマーにトリガーを設定します。
次のステップ
これが完了したら、データフローを使用したファブリック内のデータクリーニングなどの追加機能を検討します。これにより、Snowflakeなどの他の場所でロードする前にデータエラーを減らすことができます。