
Rationaliser la récupération des données de Tulip à Snowflake pour élargir les possibilités d'analyse et d'intégration
Objectif
Ce guide explique étape par étape comment récupérer les données des tables Tulip dans Snowflake via Microsoft Fabric (Azure Data Factory).
Une architecture de haut niveau est présentée ci-dessous :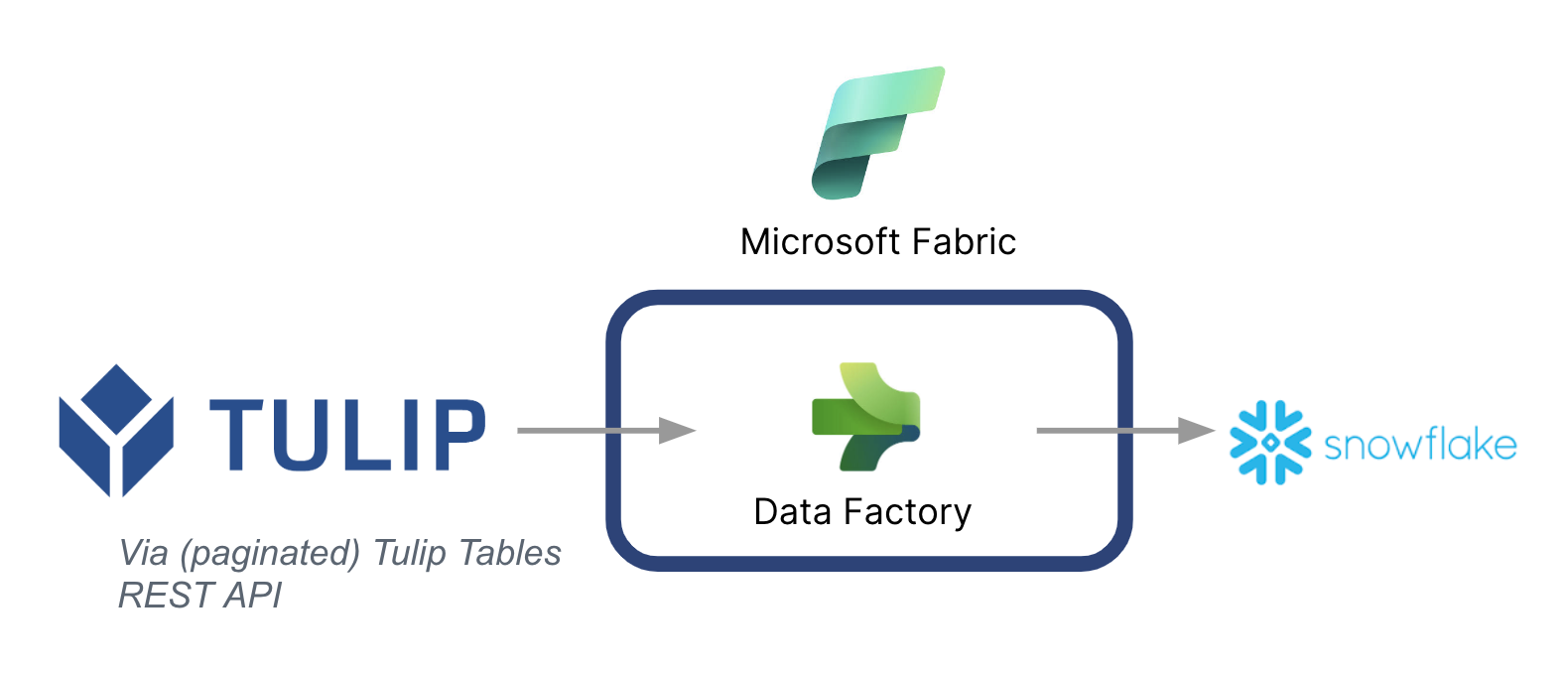
Il est essentiel de noter que Microsoft peut être utilisé comme un pipeline de données pour synchroniser les données de Tulip avec d'autres sources de données -- même des sources de données non-Microsoft.
Contexte de Microsoft Fabric
Microsoft Fabric comprend tous les outils pertinents pour l'ingestion, le stockage, l'analyse et la visualisation des données de bout en bout.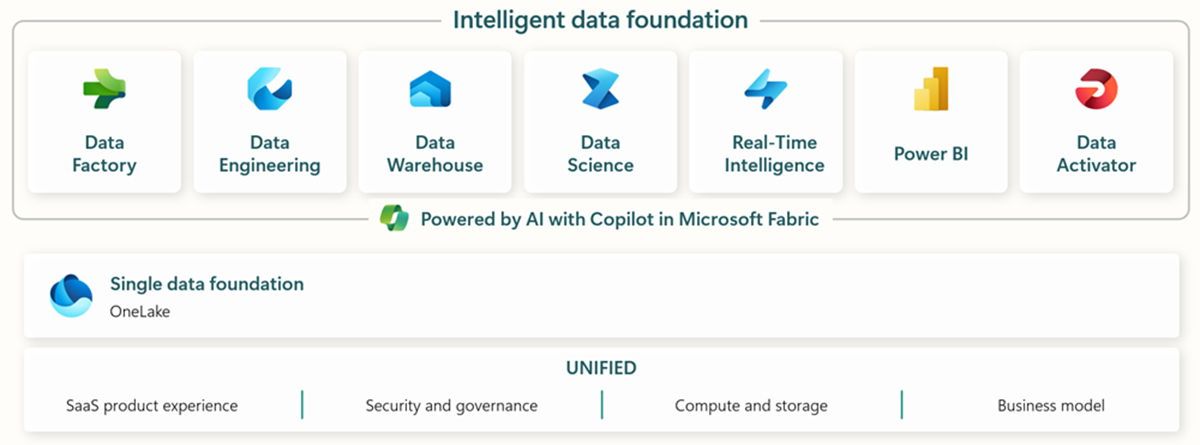
Lesservices spécifiques sont résumés ci-dessous :* Data Factory - ingérer, copier ou extraire des données d'autres systèmes * Data Engineering - transformer et manipuler des données * Data Warehouse - stocker des données sur un Data Warehouse SQL * Data Science - analyser des données avec des notebooks hébergés * Real Time Analytics - utiliser des outils d'analyse et de visualisation en continu dans un cadre unique de Fabric * PowerBI - permettre à l'entreprise d'obtenir des informations avec PowerBI pour l'intelligence d'entreprise.
Consultez ce lien pour plus d'informations sur Microsoft Fabric.
Cependant, des capacités spécifiques peuvent également être utilisées en conjonction avec d'autres nuages de données. Par exemple, Microsoft Data Factory peut fonctionner avec les magasins de données non Microsoft suivants : * Google BigQuery * Snowflake * MongoDB * AWS S3
Consultez ce lien pour plus de détails
Création de valeur
Ce guide présente un moyen simple de récupérer par lots des données de Tulip vers Snowflake pour une analyse plus large à l'échelle de l'entreprise. Si vous utilisez Snowflake pour stocker d'autres données d'entreprise, cela peut être un excellent moyen de les contextualiser avec les données de l'atelier afin de prendre de meilleures décisions basées sur les données.
Instructions de configuration
Créez un pipeline de données sur Data Factory (In Fabric) et faites en sorte que la source soit REST et le puits Snowflake.
Configuration de la source :
- Sur la page d'accueil de Fabric, allez à Data Factory
- Créer un nouveau pipeline de données sur Data Factory
- Commencez par l'"Assistant de copie de données" pour rationaliser le processus de création.
- Détails de l'assistant de copie de données :
- Source de données : REST
- URL de base : https://[instance].tulip.co/api/v3
- Type d'authentification : Basique
- Nom d'utilisateur : Clé API de Tulip
- Mot de passe : Secret API de Tulip
- URL relative : tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Request : GET
- Nom de l'option de pagination : QueryParameters.{offset}
- Valeur de l'option de pagination : RANGE:0:10000:100
- Remarque : la limite peut être inférieure à 100 si nécessaire, mais l'incrément dans la pagination doit correspondre.
- Remarque : la valeur de la pagination pour la plage doit être supérieure au nombre d'enregistrements dans la table.
Sink (Destination) Config :
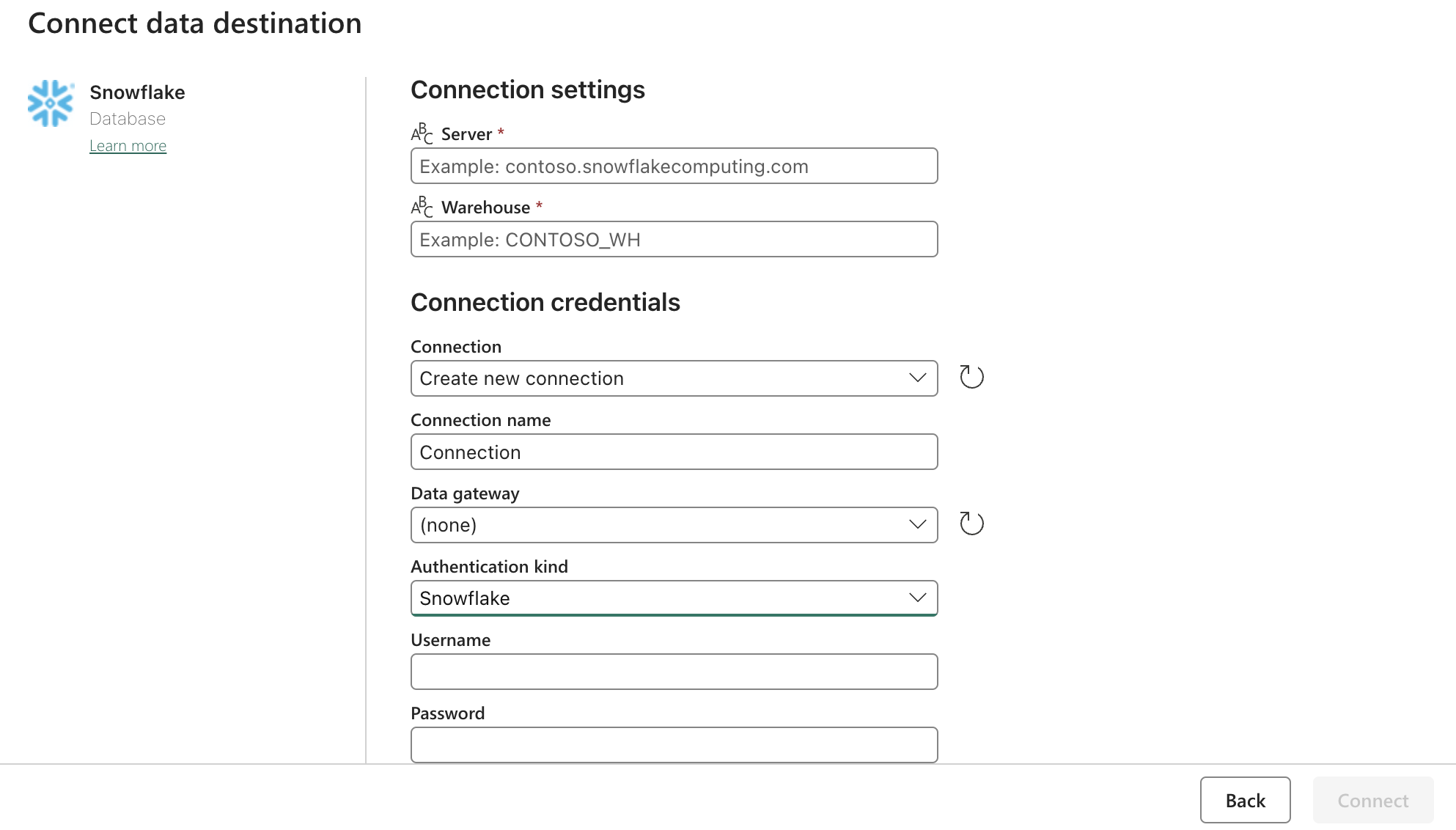
Mettez à jour les paramètres OAuth2.0 de Snowflake avec le formulaire ci-dessus. Ensuite, configurez les déclencheurs pour qu'ils soient sur une action pertinente, manuelle, ou sur une minuterie.
Prochaines étapes
Une fois que cela est fait, explorer des fonctionnalités supplémentaires telles que le nettoyage des données à l'intérieur du tissu en utilisant des flux de données. Cela peut réduire les erreurs de données avant de les charger dans d'autres endroits tels que Snowflake.