
Abfrage von Tulip-Tabellen mit einem Glue-ETL-Skript zur Vereinfachung der Übertragung von Daten von Tulip zu Redshift (oder anderen Datenwolken)
Zweck
Dieses Skript bietet einen einfachen Ausgangspunkt für die Abfrage von Daten in Tulip-Tabellen und die Übertragung zu Redshift oder anderen Data Warehouses
Architektur auf hoher Ebene
Diese High-Level-Architektur kann verwendet werden, um Daten von der Tulip Tables API abzufragen und dann in Redshift für weitere Analysen und Verarbeitung zu speichern.
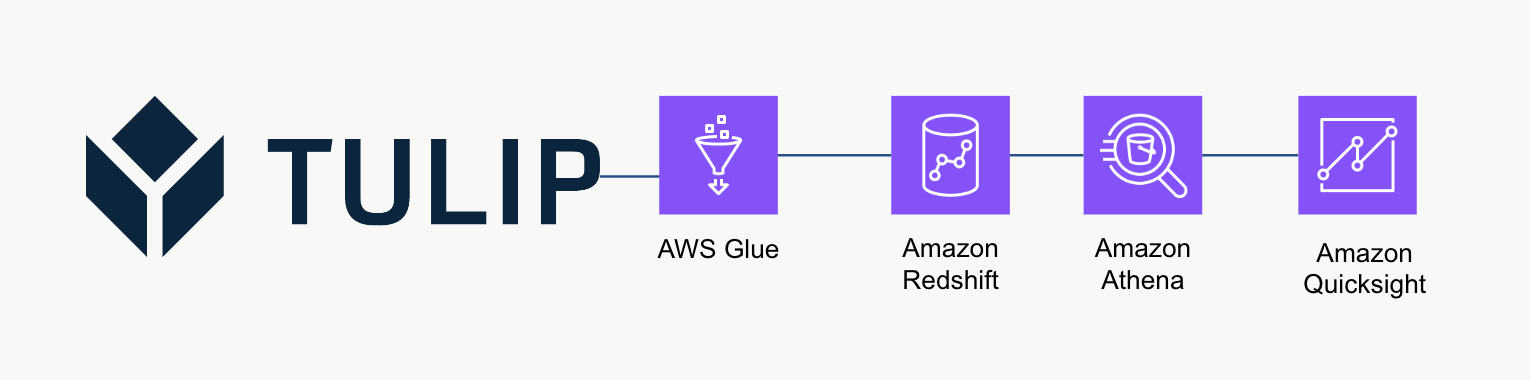
Beispiel-Skript
Das folgende Beispielskript zeigt, wie eine einzelne Tulp-Tabelle mit Glue ETL (Python Powershell) abgefragt und dann in Redshift geschrieben wird. HINWEIS: Für skalierte Produktionsanwendungen wird stattdessen empfohlen, in einen temporären S3-Bucket zu schreiben und den Bucket-Inhalt dann nach S3 zu kopieren. Außerdem werden die Anmeldeinformationen über AWS Secrets Manager gespeichert.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name): # Secrets Manager Client erstellen session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e: # Für eine Liste der ausgelösten Ausnahmen, siehe # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# SQL-Engine erstellen
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Autorisierung' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# Datums-/Zeitstempel erfassen
now = datetime.now() df['datetime\_updated'] = now
# Schreiben in Redshift
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
Überlegungen zur Skalierung
Ziehen Sie in Erwägung, S3 als temporären Zwischenspeicher zu verwenden, um die Daten dann von S3 nach Redshift zu kopieren, anstatt sie direkt in Redshift zu schreiben. Dies kann rechnerisch effizienter sein.
Darüber hinaus können Sie auch Metadaten verwenden, um alle Tulip-Tabellen in ein Data Warehouse zu schreiben, anstatt nur einzelne Tulip-Tabellen
Schließlich wird in diesem Beispielskript jedes Mal die gesamte Tabelle überschrieben. Eine effizientere Methode wäre die Aktualisierung von Zeilen, die seit der letzten Aktualisierung oder Abfrage geändert wurden.
Nächste Schritte
Für weitere Informationen lesen Sie bitte das Amazon Well-Architected Framework. Dies ist eine großartige Ressource für das Verständnis optimaler Methoden für Datenflüsse und Integrationen