
Rationalisierung des Abrufs von Daten von Tulip zu AWS für umfassendere Analysen und Integrationsmöglichkeiten
Zweck
Diese Anleitung zeigt Schritt für Schritt, wie man Daten aus Tulip Tables über eine Lambda-Funktion in AWS abruft.
Die Lambda-Funktion kann über eine Vielzahl von Ressourcen wie Event Bridge Timer oder ein API Gateway ausgelöst werden.
Eine Beispielarchitektur ist unten aufgeführt:
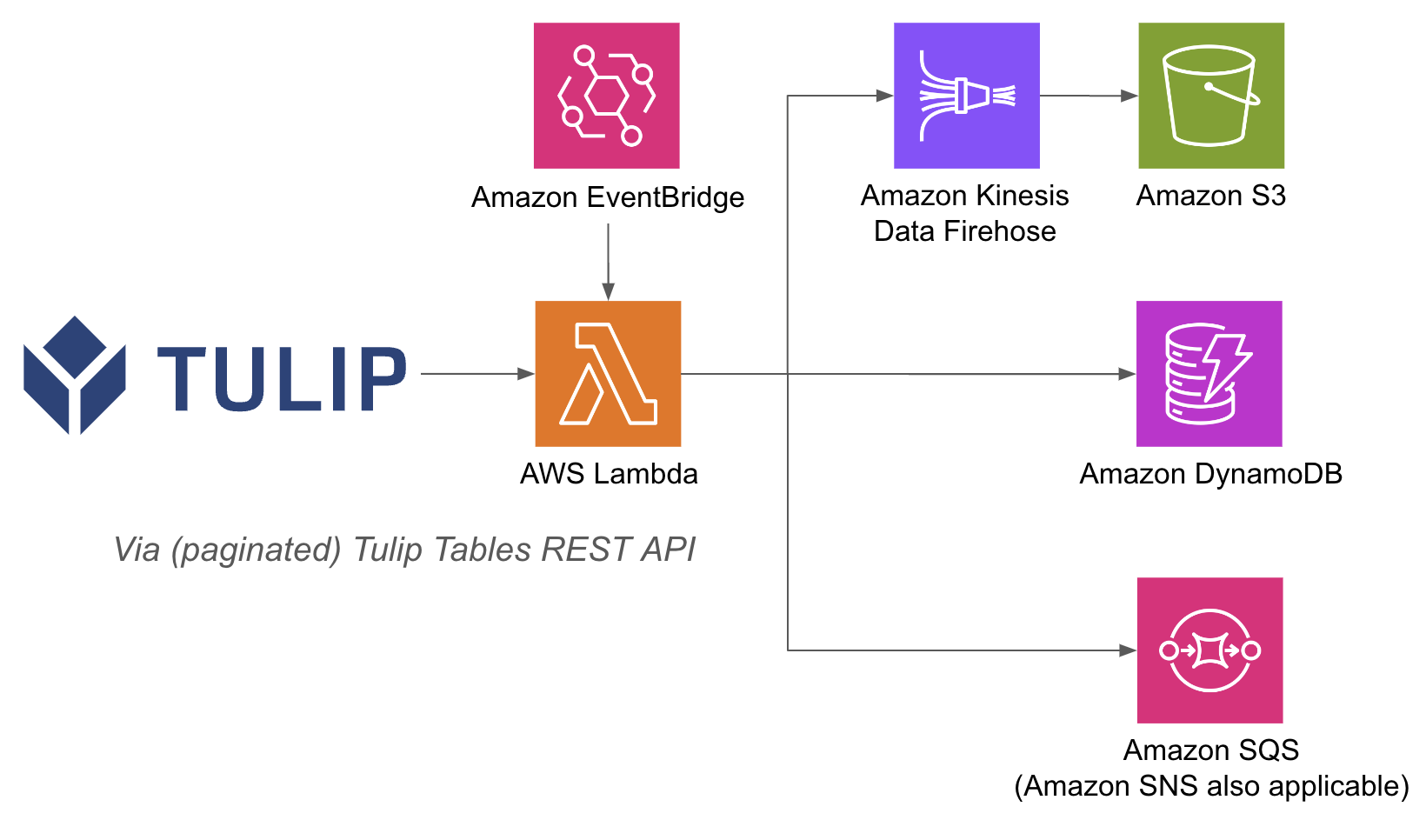
Die Durchführung von AWS-Operationen innerhalb einer Lambda-Funktion kann einfacher sein, denn mit API Gateway und Lambda-Funktionen müssen Sie Datenbanken auf der Tulip-Seite nicht mit Benutzernamen und Passwort authentifizieren; Sie können sich auf die IAM-Authentifizierungsmethoden innerhalb von AWS verlassen. Dies vereinfacht auch die Nutzung anderer AWS-Dienste wie Redshift, DynamoDB und andere.
Einrichtung
Dieses Integrationsbeispiel erfordert Folgendes:
- Verwendung von Tulip Tables API (API-Schlüssel und Geheimnis in den Kontoeinstellungen abrufen)
- Tulip Table (Holen Sie sich die Unique ID der Tabelle
Wichtigste Schritte: 1. Erstellen Sie eine AWS Lambda Funktion mit dem entsprechenden Trigger (API Gateway, Event Bridge Timer, etc.) 2. Holen Sie die Daten der Tulip-Tabelle mit folgendem Beispiel ```python import json import pandas as pd import numpy as np import requests
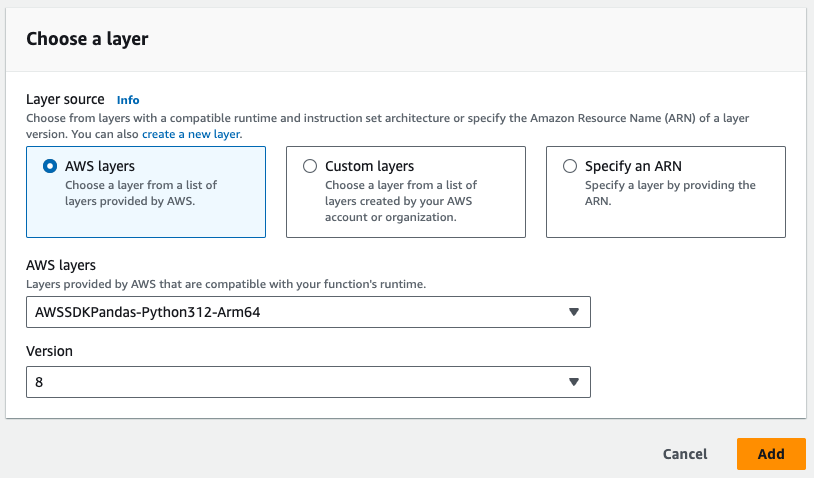
# HINWEIS: Die Pandas-Schicht von AWS muss
# zu der Lambda-Funktion hinzugefügt werden
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # Dies fügt 100 Datensätze an einen Datenrahmen an und kann dann für S3, Firehose, etc. verwendet werden. # Verwenden Sie die Datenvariable, um in S3, Firehose,
# Datenbanken, und mehr ````.
- Der Trigger kann über einen Timer laufen oder über eine URL ausgelöst werden.
- Beachten Sie die erforderliche Pandas-Schicht in der Abbildung unten
- Zum Schluss fügen Sie alle erforderlichen Integrationen hinzu. Sie können die Daten aus Lambda-Funktionen in eine Datenbank, S3 oder einen Benachrichtigungsdienst schreiben.
Anwendungsfälle und nächste Schritte
Sobald Sie die Integration mit Lambda abgeschlossen haben, können Sie die Daten ganz einfach mit einem Sagemaker-Notebook, QuickSight oder einer Vielzahl anderer Tools analysieren.
1. Fehlervorhersage- Identifizieren Sie Produktionsfehler, bevor sie auftreten, und erhöhen Sie die Fehlerquote beim ersten Mal. - Identifizieren Sie die wichtigsten Qualitätsfaktoren in der Produktion, um Verbesserungen zu implementieren.
2. Optimierung der Qualitätskosten- Identifizierung von Möglichkeiten zur Optimierung des Produktdesigns ohne Beeinträchtigung der Kundenzufriedenheit
3. Energieoptimierung in der Produktion- Identifizierung von Produktionshebeln zur Optimierung des Energieverbrauchs
4. Liefer- und Planungsvorhersage und -optimierung- Optimierung des Produktionsplans auf der Grundlage der Kundennachfrage und des Echtzeit-Auftragsplans
5. Globales Maschinen-/Linien-Benchmarking- Benchmarking ähnlicher Maschinen oder Anlagen mit Normalisierung
6. Globales/regionales digitales Leistungsmanagement- Konsolidierte Daten zur Erstellung von Dashboards in Echtzeit