
더 광범위한 분석 및 통합 기회를 위해 Tulip에서 Snowflake로 데이터 가져오기 간소화
목적
이 가이드에서는 Microsoft 패브릭(Azure 데이터 팩토리)을 통해 Tulip 테이블에서 Snowflake로 데이터를 가져오는 방법을 단계별로 안내합니다.
높은 수준의 아키텍처는 다음과 같습니다: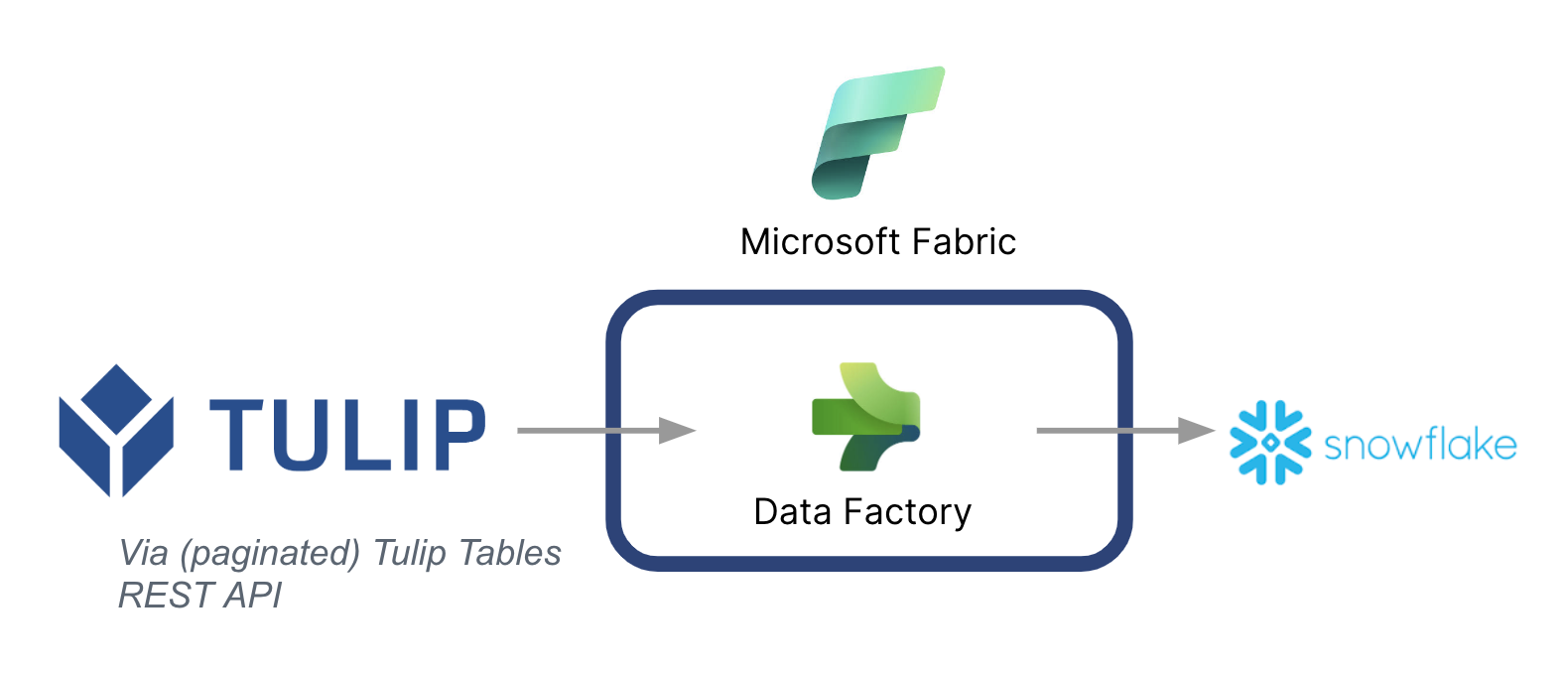
한 가지 중요한 점은 Microsoft를 데이터 파이프라인으로 사용하여 Tulip의 데이터를 다른 데이터 소스, 심지어 Microsoft가 아닌 데이터 소스로 동기화할 수 있다는 점입니다.
Microsoft 패브릭 컨텍스트
Microsoft Fabric에는 엔드투엔드 데이터 수집, 저장, 분석 및 시각화를 위한 모든 관련 도구가 포함되어 있습니다.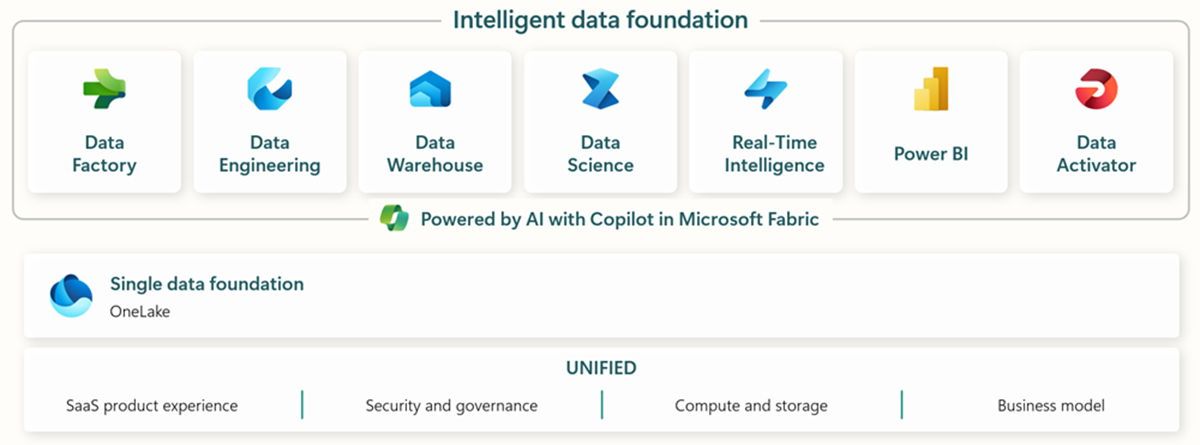
구체적인 서비스는 다음과 같습니다.* Data Factory - 다른 시스템에서 데이터 수집, 복사 또는 추출* Data Engineering - 데이터 변환 및 조작* Data Warehouse - SQL 데이터 웨어하우스에 데이터 저장* Data Science - 호스팅된 노트북으로 데이터 분석* 실시간 분석 - 패브릭의 단일 프레임워크에서 스트리밍 분석 및 시각화 도구 활용* PowerBI - 비즈니스 인텔리전스용 PowerBI로 엔터프라이즈 인사이트 지원
Microsoft Fabric에 대한 자세한 내용은 이 링크를 확인하세요.
그러나 특정 기능은 다른 데이터 클라우드와 함께 사용할 수도 있습니다. 예를 들어, Microsoft Data Factory는 다음과 같은 타사 데이터 저장소와 함께 사용할 수 있습니다: * Google BigQuery* Snowflake* MongoDB* AWS S3
가치 창출
이 가이드에서는 광범위한 전사적 분석을 위해 Tulip에서 Snowflake로 데이터를 일괄 가져오는 간단한 방법을 소개합니다. 다른 엔터프라이즈 데이터를 저장하기 위해 Snowflake를 사용하는 경우, 현업의 데이터로 컨텍스트화하여 더 나은 데이터 기반 의사 결정을 내릴 수 있는 좋은 방법이 될 수 있습니다.
설정 지침
데이터 팩토리(패브릭 내)에서 데이터 파이프라인을 생성하고 소스를 REST 및 싱크를 Snowflake로 설정합니다.
소스 구성:
- Fabric 홈페이지에서 Data Factory로 이동합니다.
- Data Factory에서 새 데이터 파이프라인을 생성합니다.
- "데이터 복사 도우미"로 시작하여 생성 프로세스를 간소화합니다.
- 데이터 어시스턴트 세부 정보를 복사합니다:
- 데이터 소스: REST
- 기본 URL: https://[instance].tulip.co/api/v3
- 인증 유형: 기본
- 사용자 이름: Tulip의 API 키
- 비밀번호: Tulip의 API 시크릿
- 상대 URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- 요청 GET
- 페이지 매김 옵션 이름: QueryParameters.{offset}
- 페이지 매김 옵션 값: 범위:0:10000:100
- 참고: 필요한 경우 제한을 100보다 낮게 설정할 수 있지만 페이지 매김의 증분은 일치해야 합니다.
- 참고: 범위의 페이지 매김 값은 테이블의 레코드 수보다 커야 합니다.
싱크(대상) 구성:
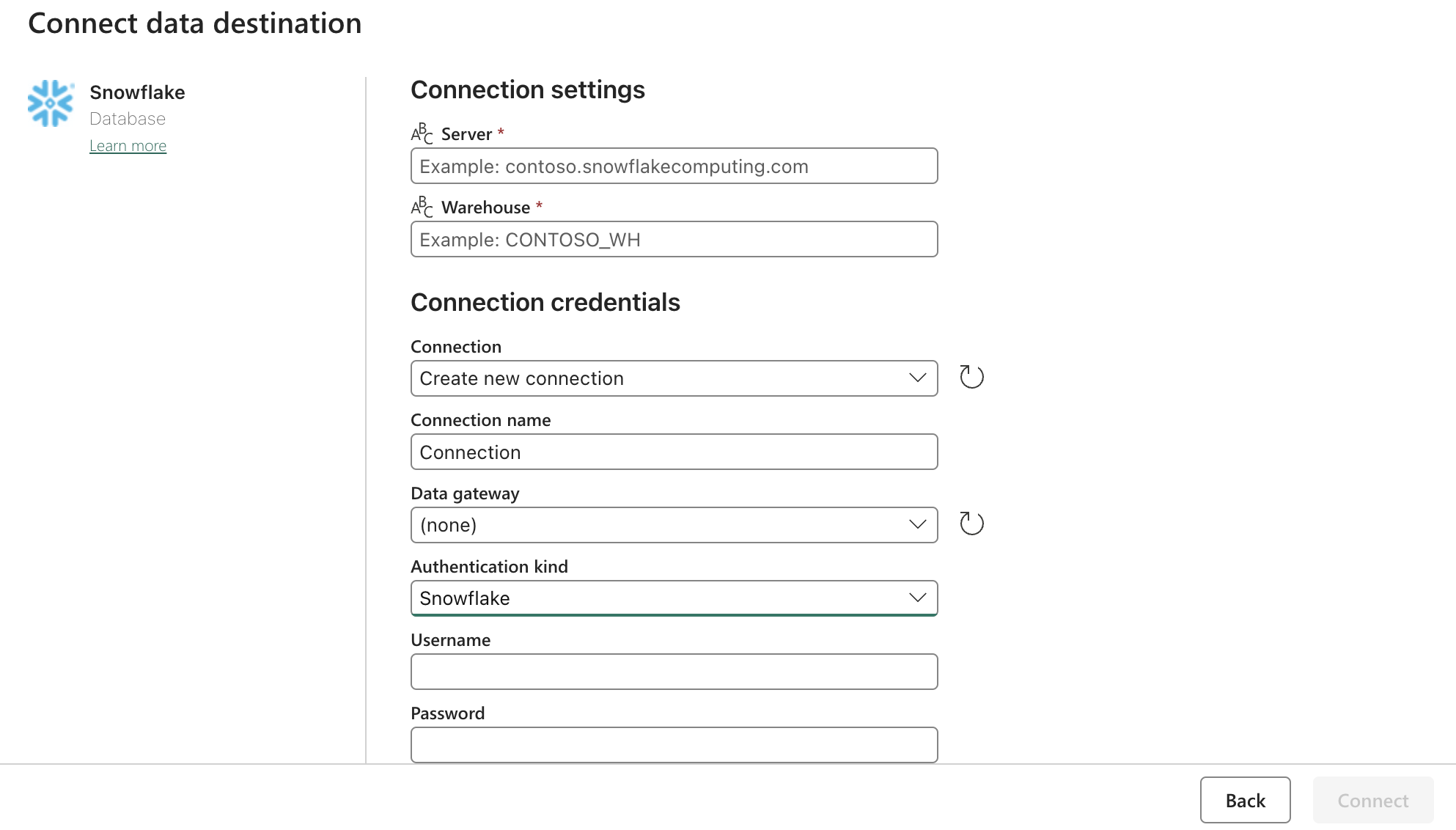
위의 양식으로 Snowflake OAuth2.0 설정을 업데이트합니다. 그런 다음 관련 작업, 수동 또는 타이머에 트리거를 구성합니다.
다음 단계
이 작업이 완료되면 데이터 흐름을 사용하여 패브릭 내부의 데이터 정리와 같은 추가 기능을 살펴보세요. 이렇게 하면 스노우플레이크와 같은 다른 위치에 데이터를 로드하기 전에 데이터 오류를 줄일 수 있습니다.