
Agilice la obtención de datos de Tulip a Snowflake para ampliar las oportunidades de análisis e integración.
Propósito
Esta guía explica paso a paso cómo obtener datos de las tablas de Tulip en Snowflake a través de Microsoft Fabric (Azure Data Factory).
A continuación se muestra una arquitectura de alto nivel: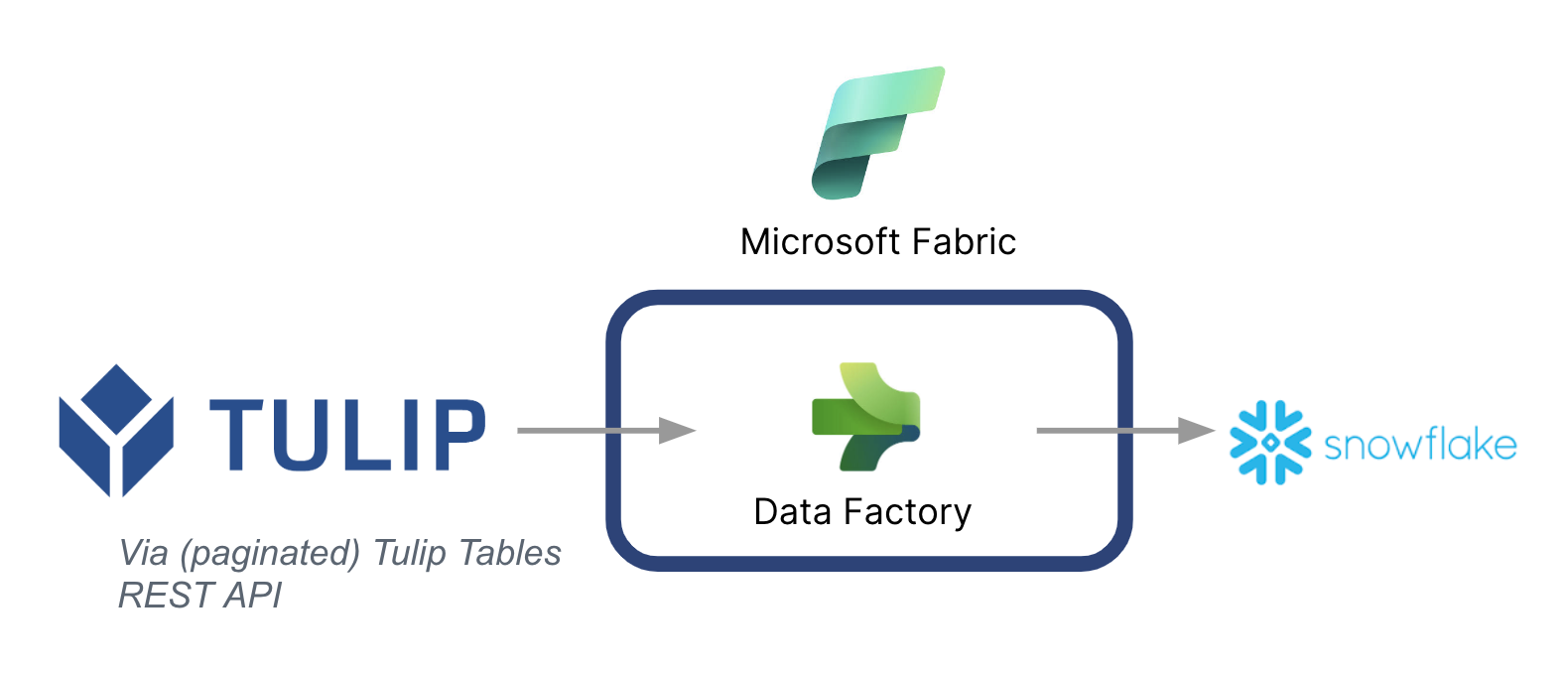
Es fundamental tener en cuenta que Microsoft se puede utilizar como una tubería de datos para sincronizar los datos de Tulip a otras fuentes de datos - Incluso las fuentes de datos que no son de Microsoft.
Contexto de Microsoft Fabric
Microsoft Fabric incluye todas las herramientas relevantes para la ingestión, almacenamiento, análisis y visualización de datos de extremo a extremo.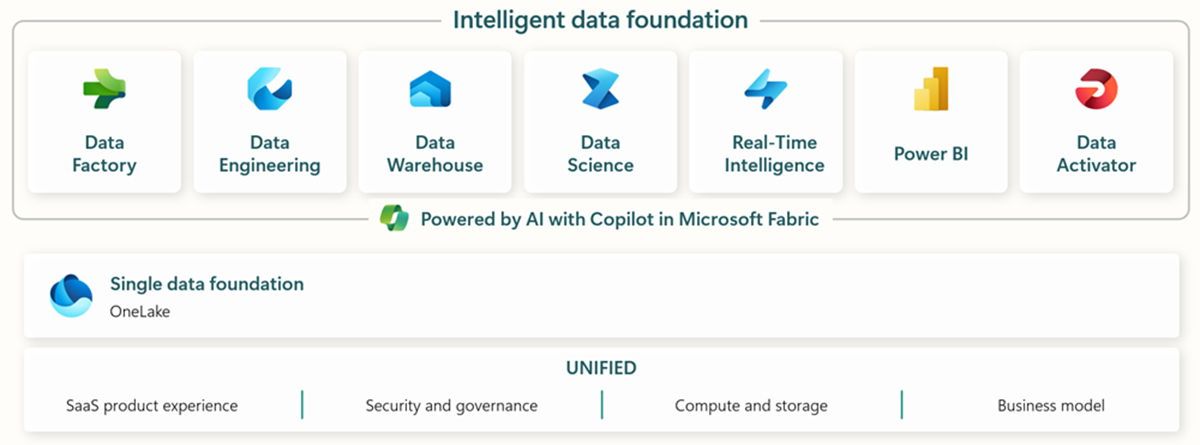
Los servicios específicos se resumen a continuación:* Data Factory - ingiere, copia o extrae datos de otros sistemas * Data Engineering - transforma y manipula datos * Data Warehouse - almacena datos en un almacén de datos SQL * Data Science - Analiza datos con cuadernos alojados * Real Time Analytics - Utiliza herramientas de análisis y visualización en tiempo real bajo un único marco de Fabric * PowerBI - Habilita la visión empresarial con PowerBI para inteligencia de negocio.
Consulte este enlace para obtener más información sobre Microsoft Fabric
Sin embargo, también se pueden utilizar capacidades específicas junto con otras nubes de datos. Por ejemplo, Microsoft Data Factory puede trabajar con los siguientes almacenes de datos ajenos a Microsoft: * Google BigQuery * Snowflake * MongoDB * AWS S3
Consulte este enlace para obtener más contexto
Creación de valor
Esta guía presenta una forma sencilla de obtener datos por lotes de Tulip en Snowflake para un análisis más amplio de toda la empresa. Si está utilizando Snowflake para almacenar otros datos de la empresa, esta puede ser una gran manera de contextualizar con los datos de la planta para tomar mejores decisiones basadas en datos.
Instrucciones de configuración
Cree una canalización de datos en Data Factory (In Fabric) y convierta la fuente en REST y el sumidero en Snowflake
Configuración de la fuente:
- En la página de inicio de Fabric, vaya a Data Factory
- Cree una nueva canalización de datos en Data Factory
- Comience con el "Copy Data Assistant" para agilizar el proceso de creación
- Detalles del Asistente de Copia de Datos:
- Fuente de datos: REST
- URL base: https://[instance].tulip.co/api/v3
- Tipo de autenticación: Básica
- Nombre de usuario: API Key de Tulip
- Contraseña: API Secret de Tulip
- URL relativa: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Petición: GET
- Nombre de la opción de paginación: QueryParameters.{offset}
- Pagination Option Value: RANGE:0:10000:100
- Nota: El límite puede ser inferior a 100 si es necesario, pero el incremento en la paginación debe coincidir.
- Nota: el valor de paginación para el rango debe ser mayor que el número de registros de la tabla.
Config:
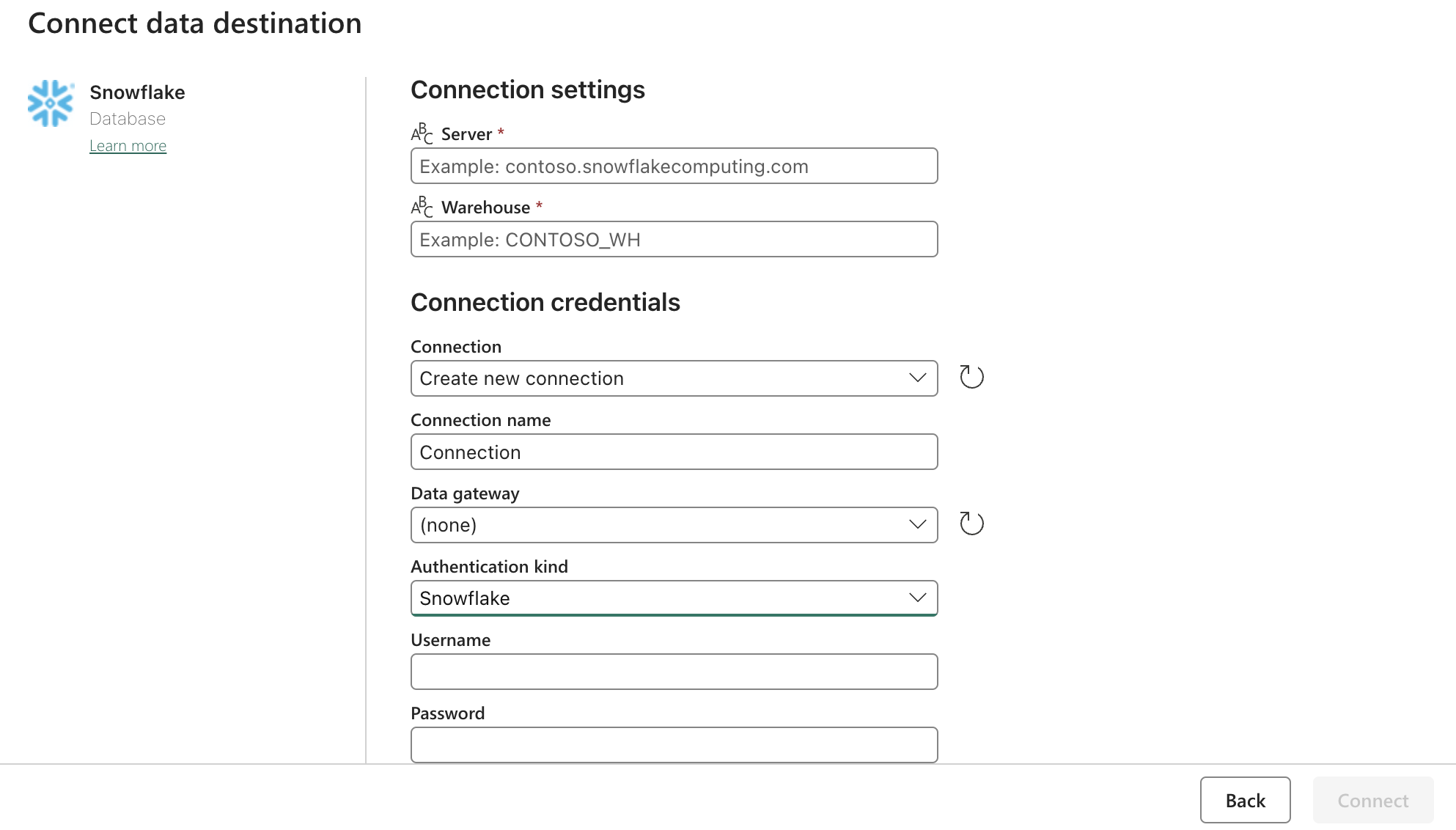
Actualice la configuración de Snowflake OAuth2.0 con el formulario anterior. A continuación, configure los desencadenantes para que estén en una acción relevante, manual o temporizador.
Siguientes pasos
Una vez hecho esto, explorar características adicionales, tales como la limpieza de datos dentro de la tela utilizando los flujos de datos. Esto puede reducir los errores de datos antes de cargarlos en otras ubicaciones como Snowflake.