

Die Auslöseaktion Text aus Bild extrahieren extrahiert Text aus einem Bild auf der Grundlage einer Abfrage. Eine andere Möglichkeit, dies zu beschreiben, ist "Abfragebasierte OCR (optische Zeichenerkennung)" oder "Extrahiere Text aus einem Bild, indem du danach fragst."
Der Auslöser gibt immer nur den Text zurück, der tatsächlich im Bild vorhanden ist. Er fügt dem Bild keine zusätzlichen Informationen oder Interpretationen hinzu. Dies macht ihn sehr leistungsfähig für die Übertragung von Daten aus der physischen in die digitale Welt.
Beispiel für Anwendungsfälle:
- Einlesen von Daten aus einem Bestellformular, das von einem externen Lieferanten stammt. Vergessen Sie das manuelle Übertragen der 14-stelligen Bestellnummer aus einer Lieferantenrechnung in Ihr WMS. Kombinieren Sie eine einfache App und "Text aus Bild extrahieren", um diese Daten in Sekundenschnelle zu erfassen.
- Digitalisieren Sie Papierformulare. Die Daten auf bestehenden Papierformularen sind noch wertvoller, wenn sie in Tulip-Apps abgerufen werden können. Die Aktionen "Text aus Bild extrahieren" sind ein großartiger Mechanismus, um die physische und die digitale Welt zu verbinden.
- Arbeiten Sie zuverlässig mit Text in Sprachen, die für Ihre Mitarbeiter fremd sind. Die Welt der Fertigung ist global. Geben Sie Ihren Mitarbeitern Superkräfte, indem Sie die Trigger-Aktionen "Text aus Bild extrahieren" und "Übersetzen" kombinieren, um papierbasierte Informationen in etwas zu verwandeln, mit dem Ihre Mitarbeiter arbeiten können.
Trigger-Beispiel
Verwenden Sie eine mobile App, um ein Foto von einem Etikett auf einem Produkt zu machen und die Chargennummer zu ermitteln.
| Bild | Auslöser | Ergebnis |
|---|---|---|
| image.png{height="" width="400"} | image.png{height="" width="400"} | 11EP8F4WA58CCX |
Wert aus Bild extrahieren
Eingänge und Ausgänge
Die Triggeraktion hat zwei Eingänge, Input Image und Query, und einen Ausgang, den extrahierten Text.
Eingabe: Eingabebild
Dies ist das Bild, aus dem der Text extrahiert werden soll. Es kann vom Kamera-Eingabe-Widget, von Tulip Vision oder von externen Systemen stammen.
| Unterstützter Datentyp | |
|---|---|
| Eingabe | Bild-URL |
Eingabe: Abfrage
Dies ist die Abfrage, die zum Extrahieren des Textes aus dem Bild oder Dokument verwendet wird.
Best Practices für die Abfrage:* Verwenden Sie nach Möglichkeit Wörter aus dem Dokument. Dies ist besonders hilfreich bei Akronymen und Abkürzungen (z. B. SN, ID, SSN, Lot No., etc.). Die Trigger-Aktionen für Textextraktion unterstützen weniger komplexe Abfragen als die Trigger-Aktionen für Fragen aus Daten/Dokumenten beantworten. * Beispiel. Große Eingabe: "Wer ist der Lieferant?" * Bsp. Schlechte Eingabe: "Wer könnte uns das geschickt haben? "* Auch die Angabe des Ortes, an dem sich die Informationen befinden, kann hilfreich sein (z. B. "Wie lautet die Referenznummer auf dem Boden?")
| Unterstützter Datentyp | |
|---|---|
| Eingabe | Text |
Ausgabe: Extrahierter Text
Dies ist der Text, der auf der Grundlage der Abfrage aus dem Bild extrahiert wurde.
| Unterstützter Datentyp | |
|---|---|
| Ausgabe | Text |
Werte aus Bild/Dokument extrahieren
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Werte aus Bild/Dokument extrahieren funktioniert genauso wie Werte aus Bild extrahieren, unterstützt aber ein Array von Fragen. Dies ist wesentlich leistungsfähiger als die Trigger-Aktion "Wert aus Bild extrahieren".
Eingabe: Eingabe Bild/Dokument
Dies ist das Bild, aus dem der Text extrahiert werden soll. Es kann vom Kamera-Eingabe-Widget, von Tulip Vision oder von externen Systemen stammen. Bei Dateien kann dies statisch festgelegt werden, mit dem Dateieingabe-Widget eingegeben werden oder auf Dateien verweisen, die in Tabellen gespeichert sind.
| Unterstützter Datentyp | |
|---|---|
| Eingabe | Bild-URL |
Eingabe: Abfrage
Dies ist die Abfrage, die für die Extraktion des Textes aus dem Bild verwendet wird. Dies sollte ein Array/Liste von Textwerten sein.
| Unterstützter Datentyp | |
|---|---|
| Eingabe | Text-Liste |
Ausgabe: Extrahierter Text
Dies ist der Text, der auf der Grundlage der Abfrage aus dem Bild extrahiert wurde.
| Unterstützter Datentyp | |
|---|---|
| Ausgabe | Objekt-Array. Jedes Element hat ein Attribut "Frage" und "Antwort". |
Gesamten Text aus Bild/Dokument extrahieren
In manchen Fällen ist das Schlüssel:Wert-Paradigma der Extraktwert-Auslöseaktionen für Ihren Anwendungsfall nicht sinnvoll. Das Auslesen aller Daten aus einem Bild bietet eine nahezu unendliche Flexibilität bei den Problemen, die von Copilot gelöst werden können. Die Trigger-Aktionen "Extract All Text" bieten Ihnen diese Flexibilität.
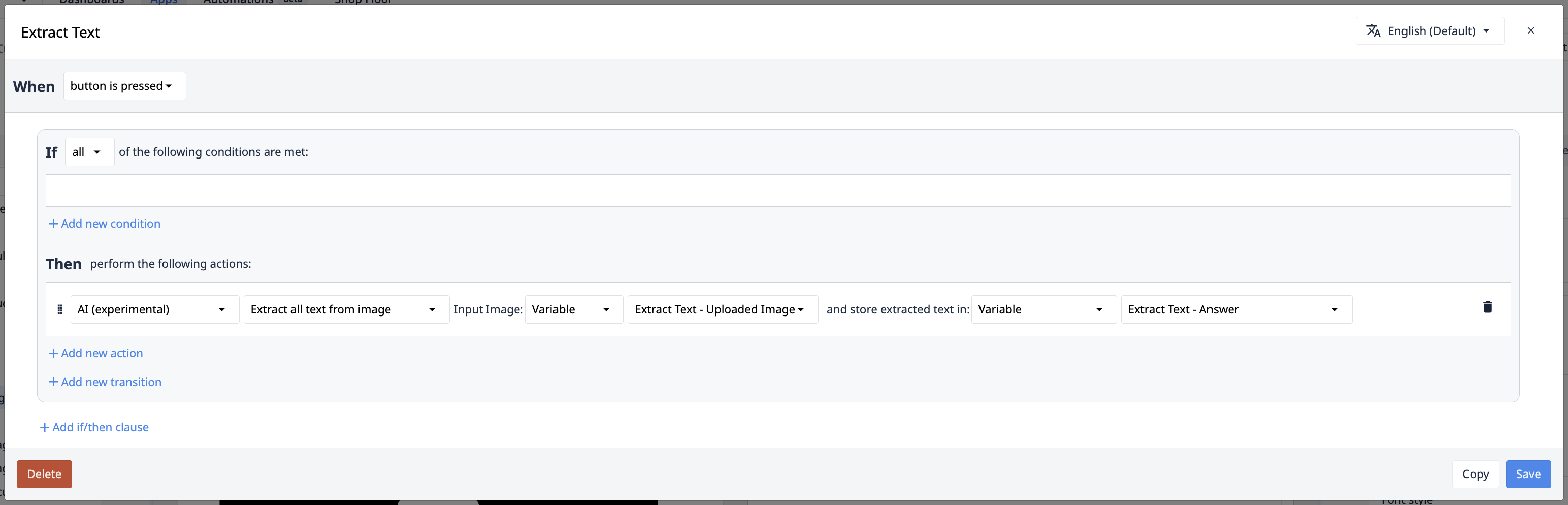
Eingabe: Eingabebild/Dokument
Dies ist das Bild, aus dem der Text extrahiert werden soll. Es kann vom Kamera-Eingabe-Widget, von Tulip Vision oder von externen Systemen stammen. Bei Dateien kann dies statisch festgelegt werden, mit dem Dateieingabe-Widget eingegeben werden oder auf Dateien verweisen, die in Tabellen gespeichert sind.
| Unterstützter Datentyp | |
|---|---|
| Eingabe | Bild-URL oder Datei-URL |
Ausgabe: Extrahierter Text
Dies ist der gesamte Text, der in dem jeweiligen Bild oder Dokument gefunden wurde. Dokumente geben ein Array von Daten zurück, wobei jedes Element den Text einer Seite des angegebenen Dokuments darstellt.
| Unterstützter Datentyp | |
|---|---|
| Ausgabe | (für Bilder) Text. (für Dokumente) Textliste |
Rand-Fälle
Kein Eingabebild und/oder keine Abfrage bereitgestellt
Wenn kein Eingabebild oder keine Abfrage für die Auslöseaktion bereitgestellt wird, zeigt die App den folgenden Systemfehler an*: Ihre Eingabe oder Abfrage ist leer*
Dies geschieht in allen folgenden Fällen:* Dem Eingabebild und/oder der Abfrage ist kein Wert zugewiesen. Dies ist gleichbedeutend mit "null".* Der Abfrage ist eine leere Zeichenfolge zugewiesen.
Kein Ergebnis für die Abfrage
Wenn für die Abfrage kein Ergebnis gefunden werden konnte, gibt die Triggeraktion einen leeren Text zurück.
Grenzwerte
The following languages are the only languages supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
Derzeit gibt es die folgenden Grenzen für "Text aus Bild extrahieren"-Trigger. Diese Grenzen werden auf Instanzebene verfolgt. Wenn diese Grenzen überschritten werden, schlägt die Triggeraktion "Text aus Bild extrahieren" fehl.