
Az adatok Tulipből Snowflake-be történő lekérdezésének egyszerűsítése a szélesebb körű elemzési és integrációs lehetőségek érdekében.
Cél
Ez az útmutató lépésről lépésre bemutatja, hogyan lehet a Microsoft Fabric (Azure Data Factory) segítségével adatokat lekérni a Tulip táblákból a Snowflake-be.
Az alábbiakban egy magas szintű architektúra szerepel: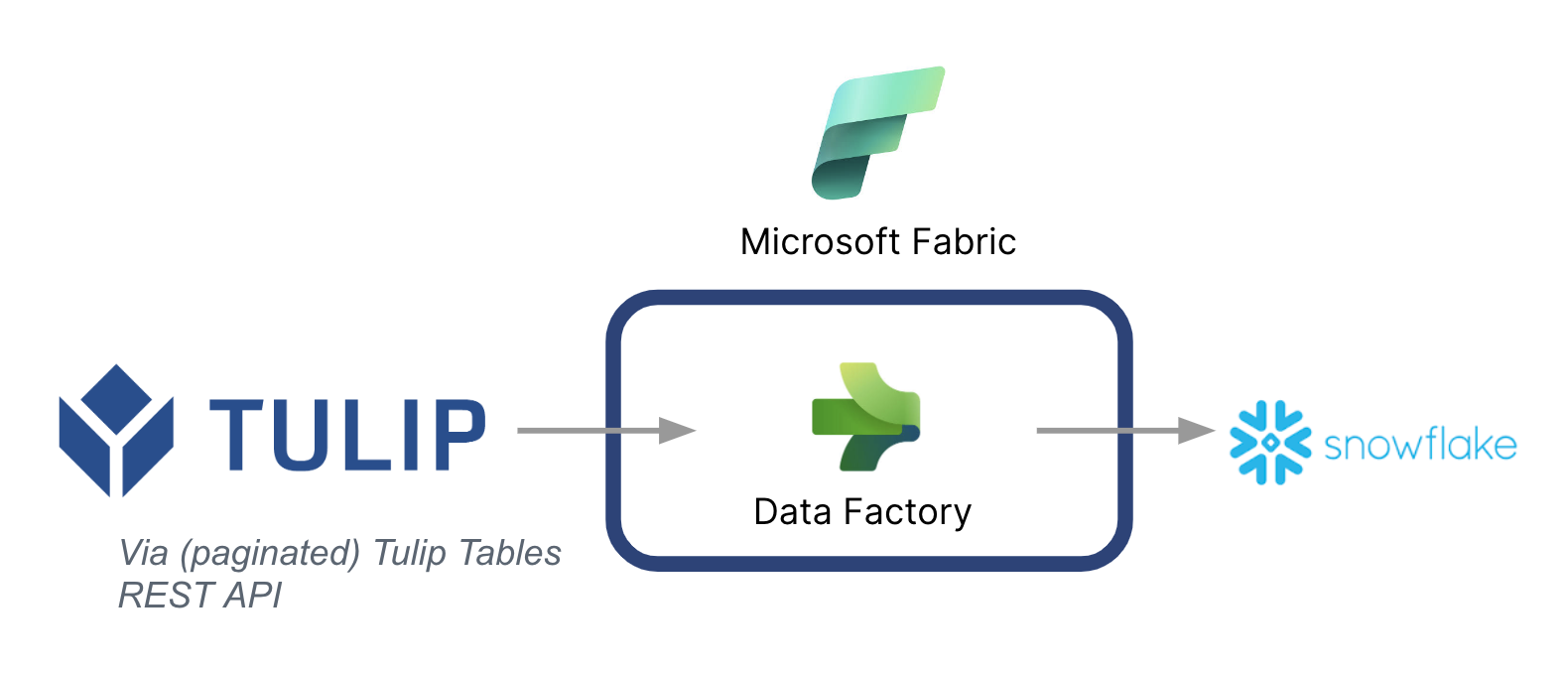
Fontos megjegyezni, hogy a Microsoft adatcsővezetékként használható a Tulipból származó adatok más adatforrásokkal való szinkronizálására -- Még a nem Microsoft adatforrásokkal is.
Microsoft Fabric kontextus
A Microsoft Fabric tartalmazza az összes releváns eszközt a végponttól végpontig tartó adatbevitelhez, tároláshoz, elemzéshez és vizualizáláshoz.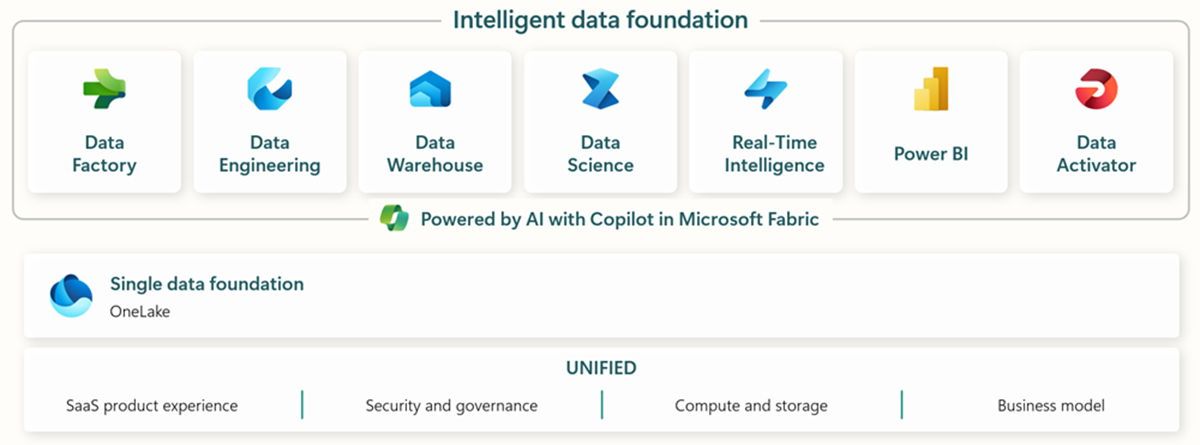
Akonkrét szolgáltatásokat az alábbiakban foglaljuk össze:* Data Factory - adatok felvétele, másolása vagy kivonása más rendszerekből * Data Engineering - adatok átalakítása és manipulálása * Data Warehouse - adatok tárolása egy SQL Data Warehouse-ban * Data Science - adatok elemzése hosztolt notebookokkal * Real Time Analytics - a Fabric egységes keretrendszerében használjon streaming analitikai és vizualizációs eszközöket * PowerBI - vállalati betekintés lehetővé tétele a PowerBI segítségével az üzleti intelligencia számára.
A Microsoft Fabricról további információkért látogasson el erre a linkre
Az egyes képességek azonban más adatfelhőkkel együtt is használhatók. A Microsoft Data Factory például a következő, nem Microsoft adattárolókkal működhet együtt: * Google BigQuery * Snowflake * MongoDB * AWS S3
További kontextusért nézze meg ezt a linket
Értékteremtés
Ez az útmutató egy egyszerű módját mutatja be annak, hogyan lehet a Tulipból kötegelt adatot behívni a Snowflake-be a szélesebb körű vállalati elemzésekhez. Ha a Snowflake-et más vállalati adatok tárolására használja, ez remek módja lehet annak, hogy kontextusba helyezze azokat az üzemi adatokkal, hogy jobb adatvezérelt döntéseket hozhasson.
Beállítási utasítások
Hozzon létre egy adatcsővezetéket a Data Factory-n (In Fabric), és tegye a forrást REST-nek, a nyelőt pedig Snowflake-nek.
Forráskonfig:
- A Fabric kezdőlapján lépjen a Data Factory-ra.
- Hozzon létre egy új adatcsővezetéket a Data Factory-n
- A létrehozási folyamat egyszerűsítése érdekében kezdje az "Adatmásoló asszisztens" használatával
- Copy Data Assistant részletek:
- Data Source: Data Source (adatforrás): A másoláshoz szükséges adatok másolása: Data Source (adatforrás): REST
- Bázis URL: https://[instance].tulip.co/api/v3
- Authentication type: Basic
- Felhasználónév: API-kulcs a Tuliptól
- Jelszó: API titok a Tuliptól
- Relatív URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Kérés: Tulip: Tulip: Tulip: Tulip: Tulip: GET
- Oldalszámozási opció neve: QueryParameters.{offset}
- Pagination Option Value: RANGE:0:10000:100
- Megjegyzés: A határérték szükség esetén 100-nál alacsonyabb is lehet, de a lépésszámnak meg kell egyeznie a lapozásban.
- Megjegyzés: A tartomány Pagination Value értékének nagyobbnak kell lennie, mint a táblázatban lévő rekordok száma.
Sink (Cél) Config:
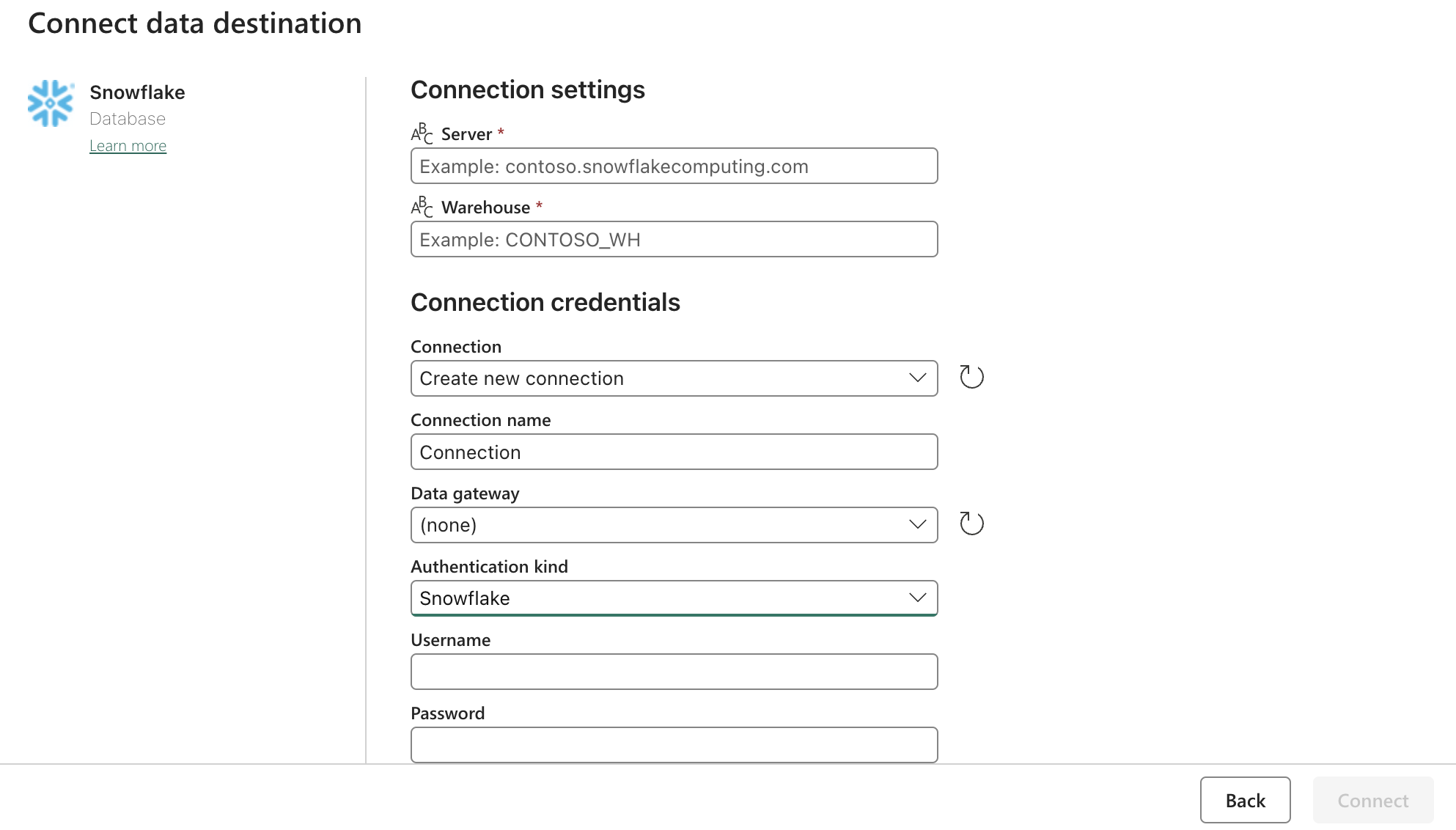
Frissítse a Snowflake OAuth2.0 beállításait a fenti űrlappal. Ezután állítsa be a kiváltókat úgy, hogy azok egy releváns műveletre, kézi vagy időzítőre vonatkozzanak.
Következő lépések
Ha ez megtörtént, vizsgálja meg a további funkciókat, például az adattisztítást a szöveten belül adatfolyamok segítségével. Ez csökkentheti az adathibákat, mielőtt más helyekre, például a Snowflake-be töltené be az adatokat.