
Упорядочить получение данных из Tulip в Snowflake для расширения возможностей аналитики и интеграции.
Цель
В этом руководстве пошагово описано, как получать данные из таблиц Tulip в Snowflake с помощью Microsoft Fabric (Azure Data Factory).
Ниже приведена высокоуровневая архитектура: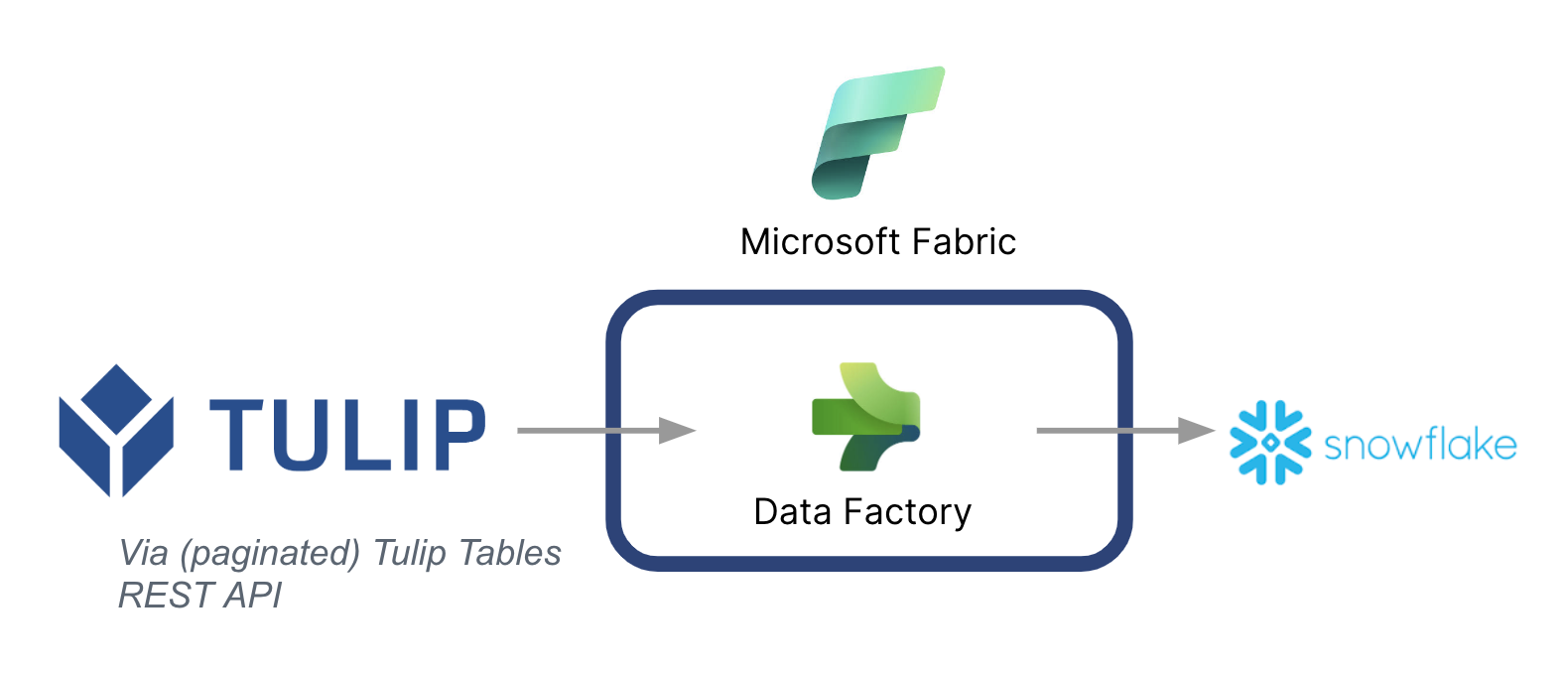
Важно отметить, что Microsoft Fabric можно использовать в качестве конвейера данных для синхронизации данных из Tulip с другими источниками данных - даже не из Microsoft.
Контекст Microsoft Fabric
Microsoft Fabric включает в себя все необходимые инструменты для сквозного получения, хранения, анализа и визуализации данных.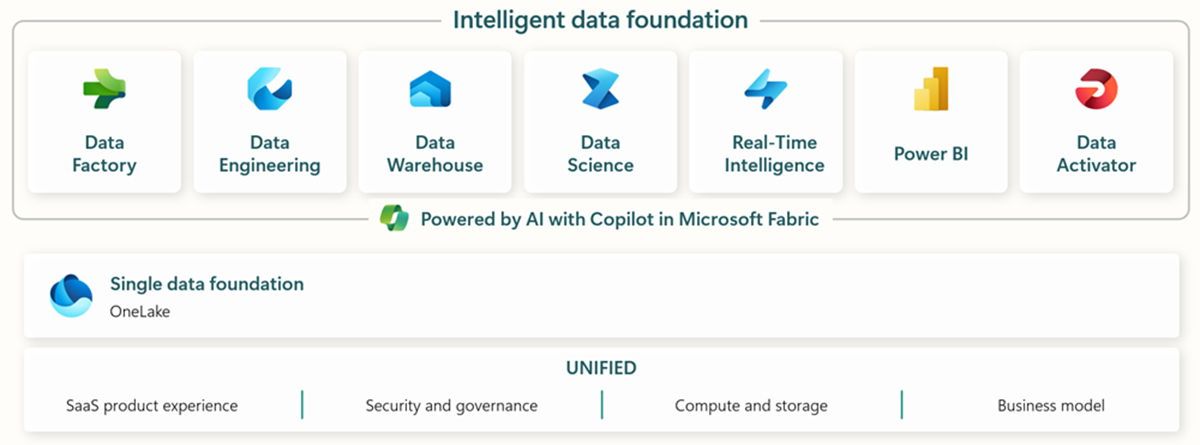
Ниже приведена краткая информация о конкретных услугах:* Фабрика данных - получение, копирование или извлечение данных из других систем * Data Engineering - преобразование и манипулирование данными * Хранилище данных - хранение данных в SQL Data Warehouse * Data Science - анализ данных с помощью размещенных блокнотов * Аналитика в реальном времени - использование потоковой аналитики и средств визуализации в рамках единой структуры Fabric * PowerBI - использование PowerBI для бизнес-аналитики.
Дополнительную информацию о Microsoft Fabric можно найти по этой ссылке.
Однако определенные возможности можно использовать и в сочетании с другими облаками данных. Например, Microsoft Data Factory может работать со следующими хранилищами данных, не принадлежащими Microsoft: * Google BigQuery * Snowflake * MongoDB * AWS S3
Ознакомьтесь с этой ссылкой для получения дополнительной информации
Создание ценности
В этом руководстве представлен простой способ пакетной выборки данных из Tulip в Snowflake для более широкой аналитики в масштабах предприятия. Если вы используете Snowflake для хранения других корпоративных данных, это может стать отличным способом контекстуализировать их с данными из цеха для принятия более эффективных решений на основе данных.
Инструкции по настройке
Создайте конвейер данных на Data Factory (в Fabric) и сделайте источник REST, а сток Snowflake
Настройка источника:
- На главной странице Fabric перейдите к Data Factory
- Создайте новый конвейер данных на Data Factory
- Начните с "Copy Data Assistant", чтобы упростить процесс создания.
- Copy Data Assistant Details:
- Источник данных: REST
- Базовый URL: https://[instance].tulip.co/api/v3
- Тип аутентификации: Базовая
- Имя пользователя: API-ключ от Tulip
- Пароль: Секрет API от Tulip
- Относительный URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Запрос: GET
- Имя опции пагинации: QueryParameters.{offset}
- Pagination Option Value: ДИАПАЗОН:0:10000:100
- Примечание: при необходимости предел может быть меньше 100, но инкремент в пагинации должен совпадать.
- Примечание: значение пагинации для диапазона должно быть больше, чем количество записей в таблице.
Настройка стока (назначения):
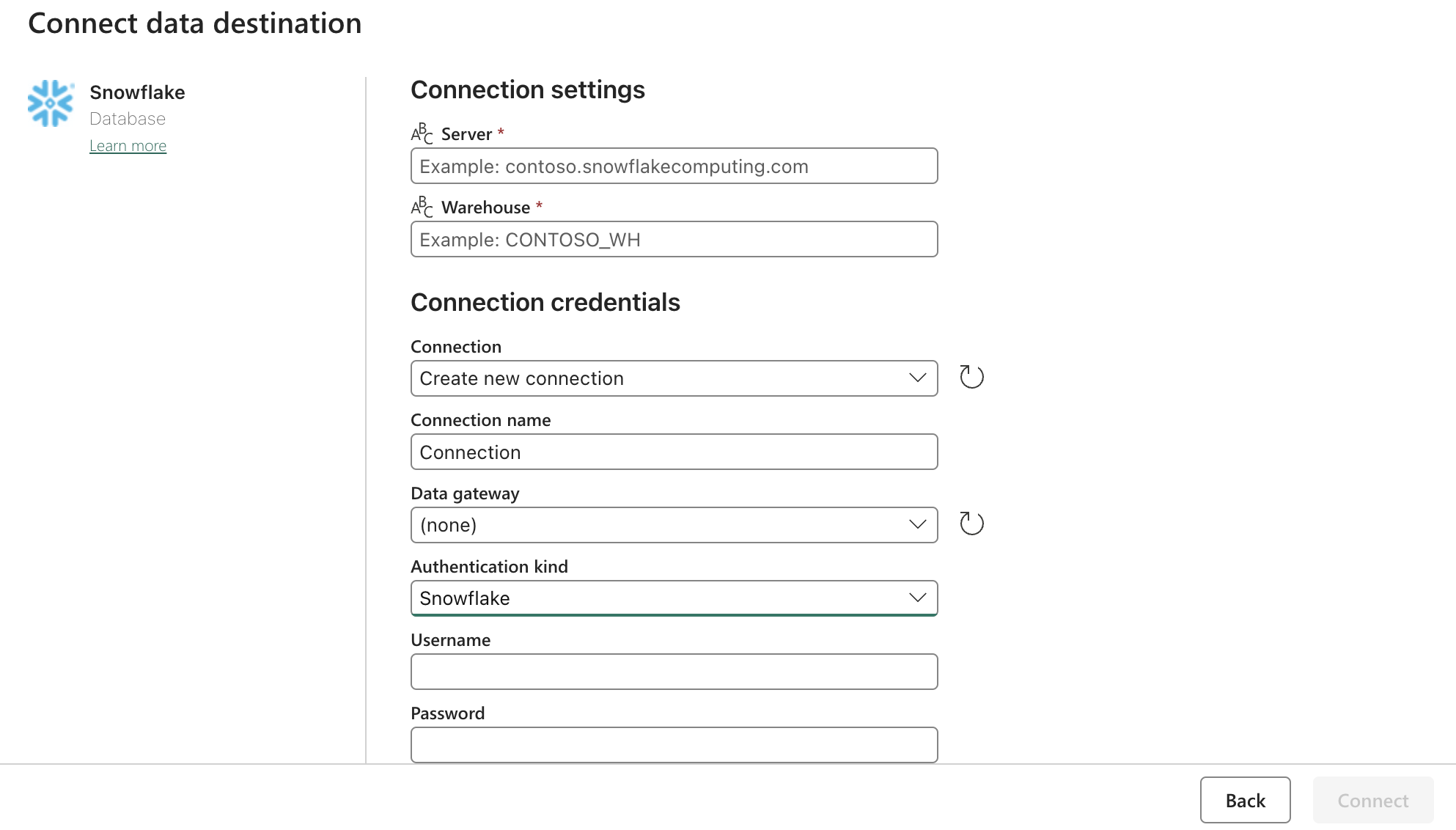
Обновите настройки Snowflake OAuth2.0 с помощью формы выше. Затем настройте триггеры на соответствующее действие, вручную или по таймеру.
Следующие шаги
Как только это будет сделано, изучите дополнительные возможности, такие как очистка данных внутри fabric с помощью потоков данных. Это поможет уменьшить количество ошибок в данных перед их загрузкой в другие места, например в Snowflake.