
Semplificare l'ingegneria dei dati di Tulip con l'integrazione di Fivetran
Scopo
La semplificazione delle pipeline di data engineering con Tulip consente di utilizzare i dati delle tabelle Tulip in tutta l'azienda.
Configurazione
Per la configurazione sono necessari i seguenti requisiti: * Account Fivetran (è disponibile la versione gratuita) * AWS (o altro account cloud) * Database o Data Warehouse per ricevere i dati delle tabelle Tulip * Conoscenza di alto livello di Python
Come funziona
Questa configurazione dell'automazione Fivetran funziona con i seguenti passaggi:
- Impostare l'account Fivetran
- Creare la destinazione (ad esempio, Snowflake)
- Creare la funzione Connector con la funzione AWS Lambda
- Creare la funzione AWS Lambda
- Finalizzare la funzione Connector
- Testare il connettore Fivetran e regolare la frequenza di aggiornamento
Fivetran utilizza la funzione lambda per recuperare automaticamente i dati delle tabelle tulipani su base programmata e aggiornare i database o i data warehouse di destinazione. L'esempio incluso è una semplice funzione che riscrive la tabella con nuovi dati aggiornati. È possibile aggiungere ulteriori funzionalità per migliorare i trigger basati su eventi.
Istruzioni per la configurazione
Impostazione dell'account Fivetran
Per prima cosa è necessario creare un account Fivetran. L'azienda offre una versione gratuita con un numero limitato di aggiornamenti al mese.
Impostazione della destinazione
Fare clic su Destinazioni e creare la prima destinazione. Si tratta essenzialmente del database o del data warehouse che riceverà i dati delle tabelle Tulip.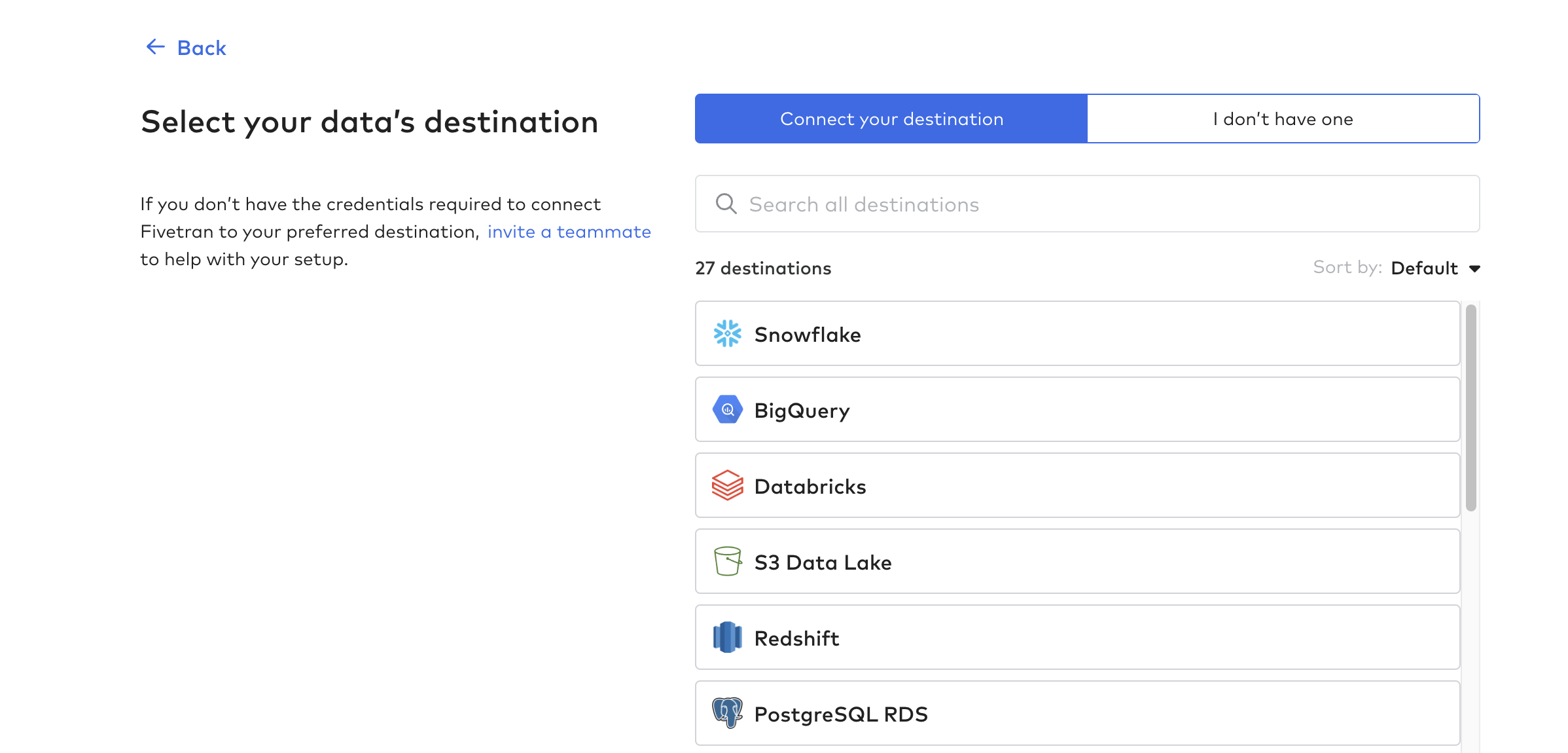
Creare la funzione connettore
Creare quindi la funzione connettore; questo è il processo per automatizzare la pipeline di dati da Tulip. È possibile utilizzare qualsiasi funzione cloud come AWS Lambda, Azure Functions o GCP Cloud Functions. Per questo esempio, utilizzeremo AWS Lambda.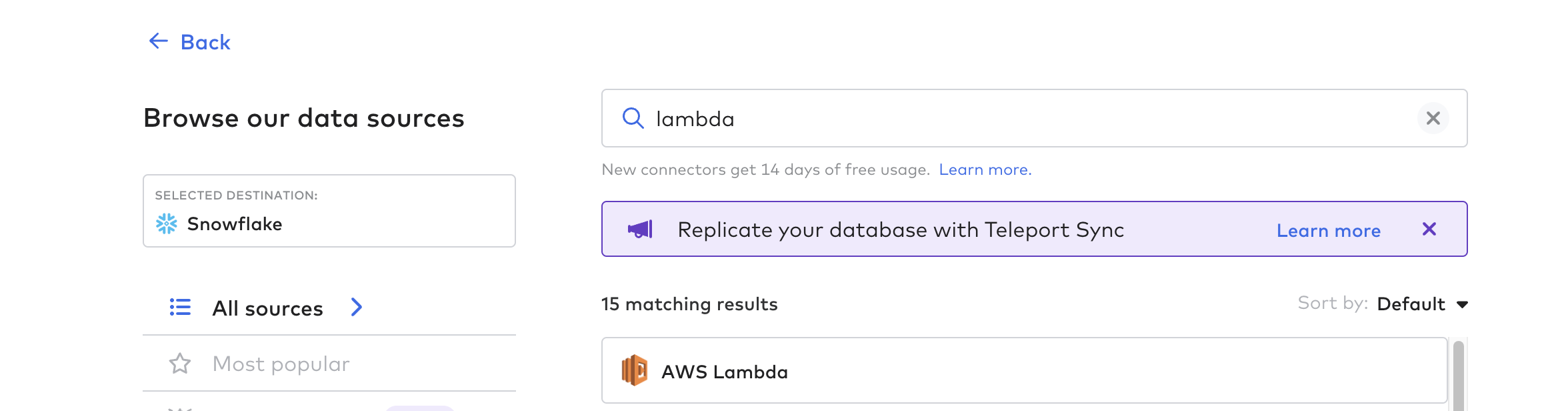
Seguire le istruzioni in-Fivetran per creare una funzione Lambda su AWS con i ruoli e i permessi appropriatiVedere il link per il modello di funzione Lambda come punto di partenzaDi seguito sono riportati alcuni suggerimenti utili:
- Dovrete creare due livelli: uno per la libreria tulip e l'altro per la libreria pandas.
- È possibile visualizzare l'API della comunità Tulip qui
- In alternativa, è possibile scaricare il file zip qui (è stato preparato per essere aggiunto a un livello).
- È possibile aggiungere facilmente il livello pandas in AWS qui sotto
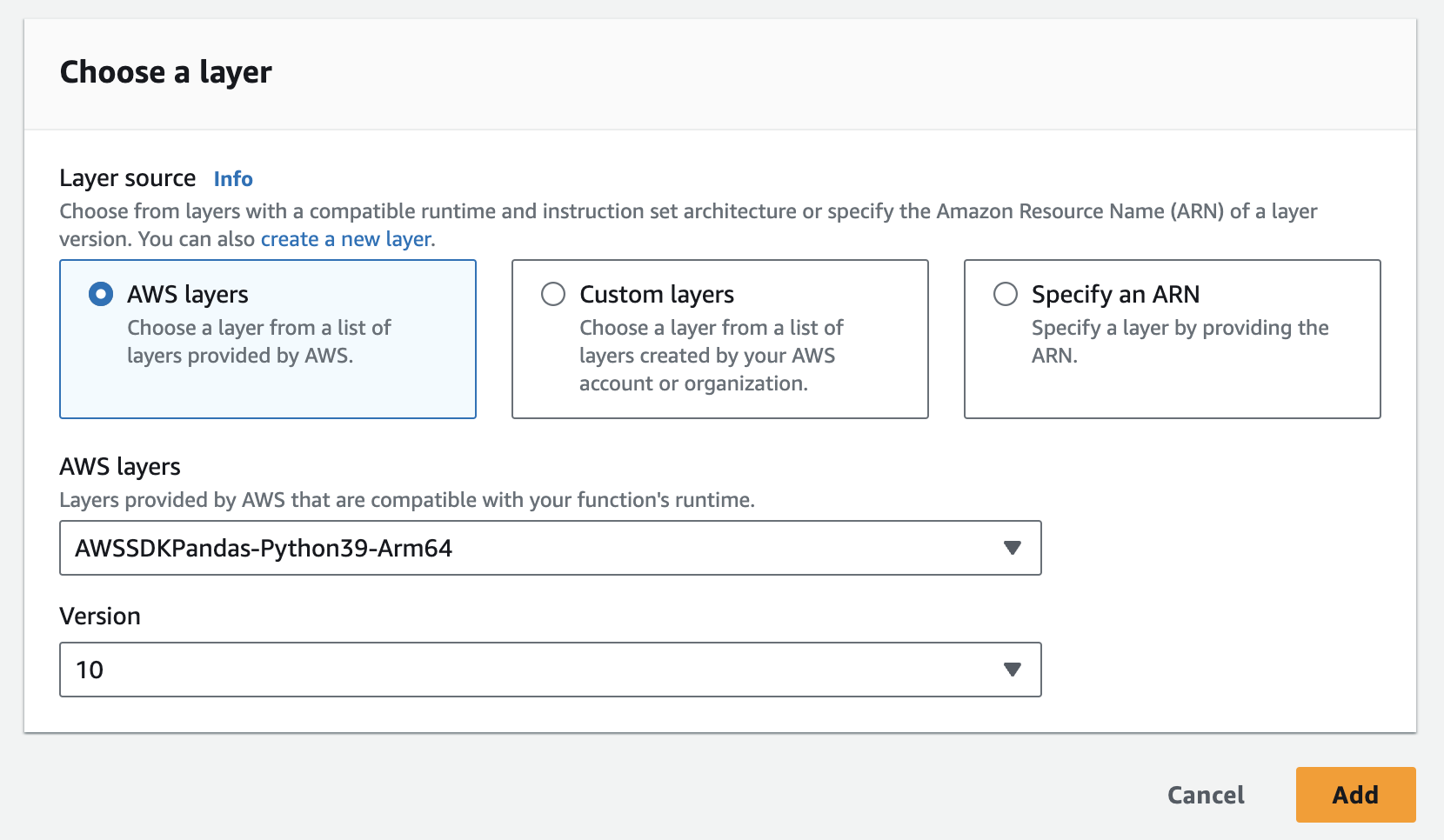
- È necessario aggiungere l'istanza, la chiave API e il segreto API come variabili d'ambiente alla funzione lambda. Potrebbe essere necessario aggiornare le impostazioni del runtime per aumentare il tempo di timeout e la memoria utilizzata. La schermata seguente mostra l'aggiornamento della configurazione
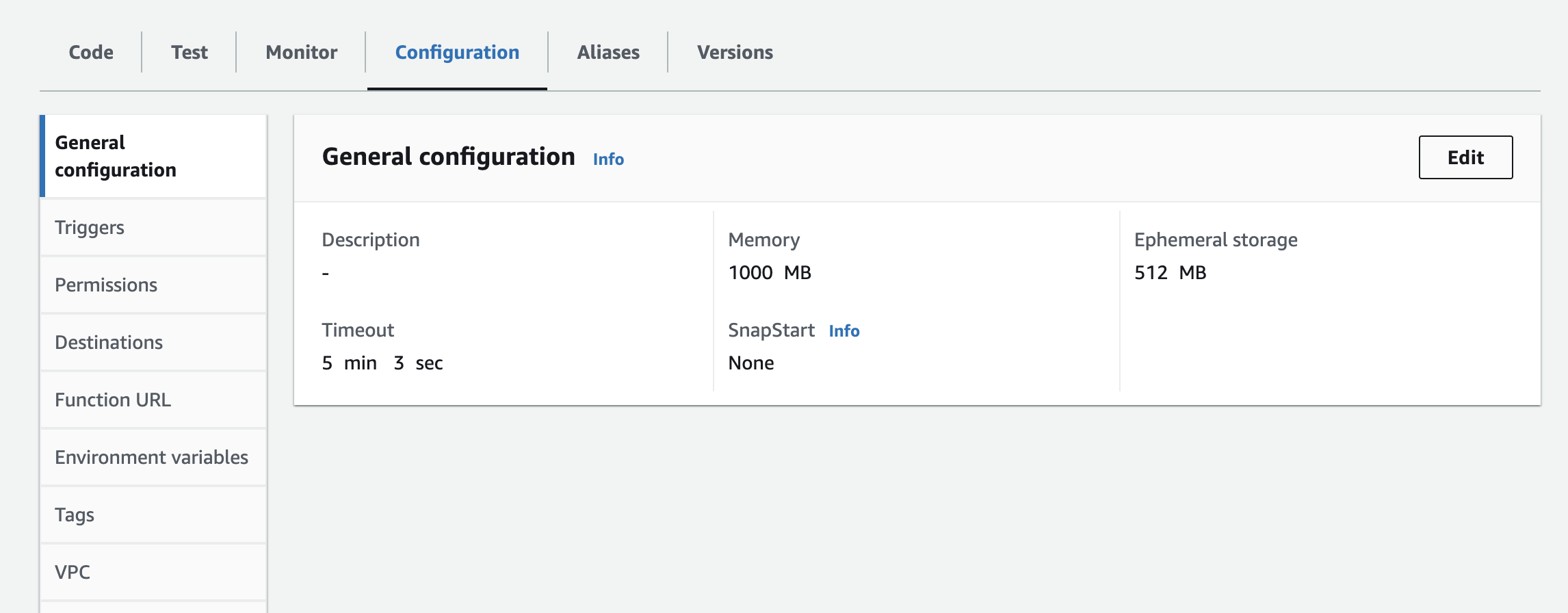
Passi successivi
Una volta che la funzione connettore è operativa, è possibile regolare la frequenza di aggiornamento, visualizzare le informazioni sulle tabelle Tulip nel database di destinazione o nel Data Warehouse e altre funzionalità aggiuntive.
Alcuni casi d'uso specifici per questa pipeline di dati: * Analisi ed elaborazione dei dati Tulip a livello aziendale * Automazioni batch con sistemi aziendali * Contestualizzazione con Data Warehouse e Data Lake
Risorse aggiuntive
Contattate Fivetran per ulteriore supporto quiContattateFivetran per ulteriore supporto qui * Inoltre, hanno fornito un modulo per apportare modifiche e richieste di integrazione semplificata delle tabelle Tulip. Fornite feedback e richieste qui