
Оптимизация проектирования данных Tulip с помощью интеграции с Fivetran
Назначение
Оптимизация конвейеров инженерии данных с помощью Tulip позволяет использовать данные таблиц Tulip в масштабах предприятия
Установка
Для установки требуется: * учетная запись Fivetran (доступна бесплатная версия) * AWS (или другая облачная учетная запись) * база данных или хранилище данных для получения данных из таблиц Tulip * знание языка Python на высоком уровне.
Как это работает
Данная настройка автоматизации Fivetran состоит из следующих шагов:
- Настройте учетную запись Fivetran
- Создание Destination (например, Snowflake)
- Создать функцию Connector с помощью функции AWS Lambda
- Создать функцию AWS Lambda
- Доработка функции коннектора
- Протестируйте коннектор Fivetran и настройте частоту обновления
Fivetran использует лямбда-функцию для автоматического получения данных из таблиц tulip по расписанию и обновления баз или хранилищ данных назначения. Приведенный пример представляет собой простую функцию, которая переписывает таблицу с новыми, обновленными данными. Дополнительные функции могут быть добавлены для улучшения триггеров, основанных на событиях.
Инструкции по настройке
Настройка учетной записи Fivetran
Сначала необходимо создать учетную запись Fivetran. Они предлагают бесплатную версию с ограниченным количеством обновлений в месяц.
Настройка пункта назначения
Затем щелкните на Destinations и создайте первую точку назначения. По сути, это база данных или хранилище данных, в которое будут поступать данные из таблиц Tulip.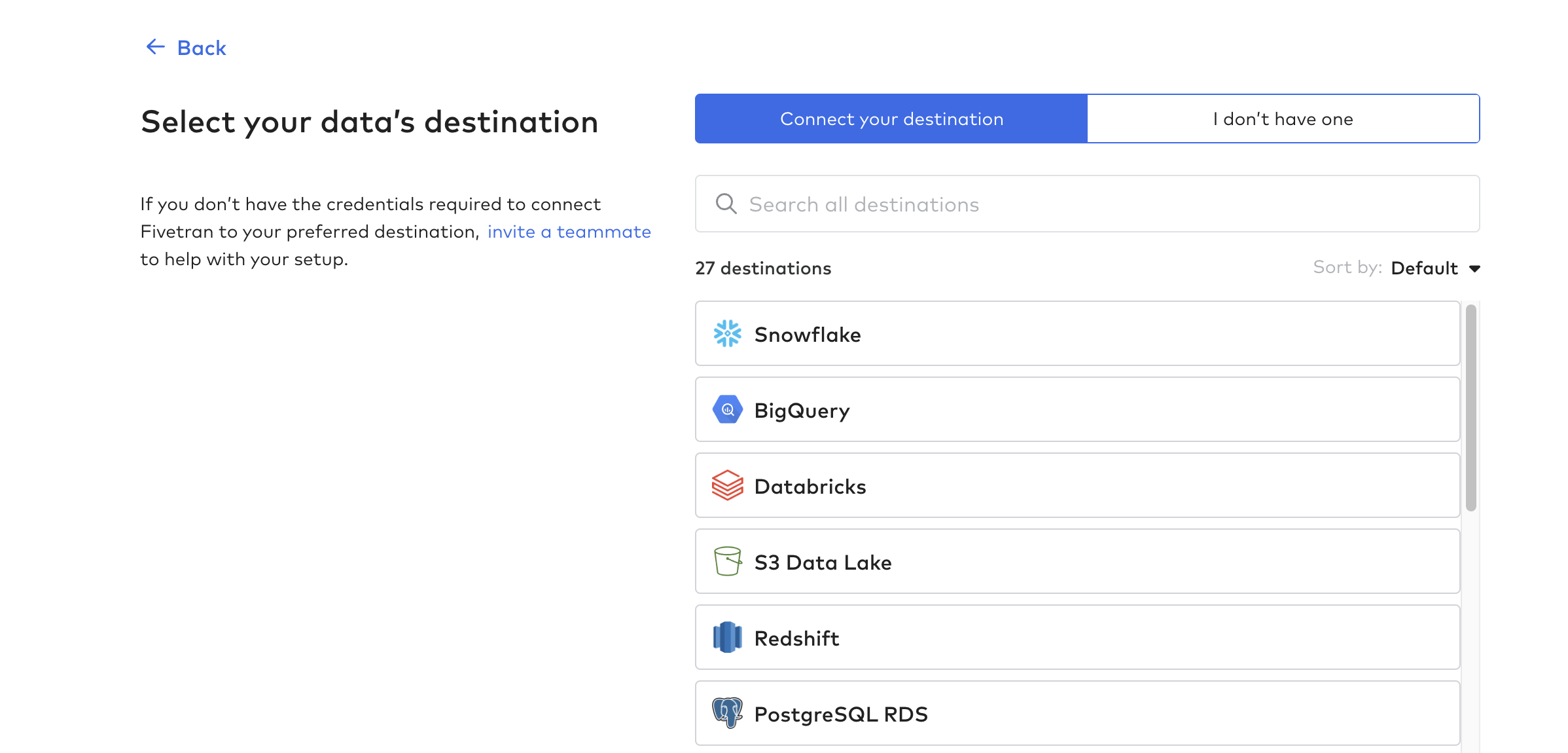
Создать функцию коннектора
Затем создайте функцию коннектора; это процесс автоматизации конвейера данных из Tulip. Можно использовать любую облачную функцию, например AWS Lambda, Azure Functions или GCP Cloud Functions. В данном примере мы будем использовать AWS Lambda.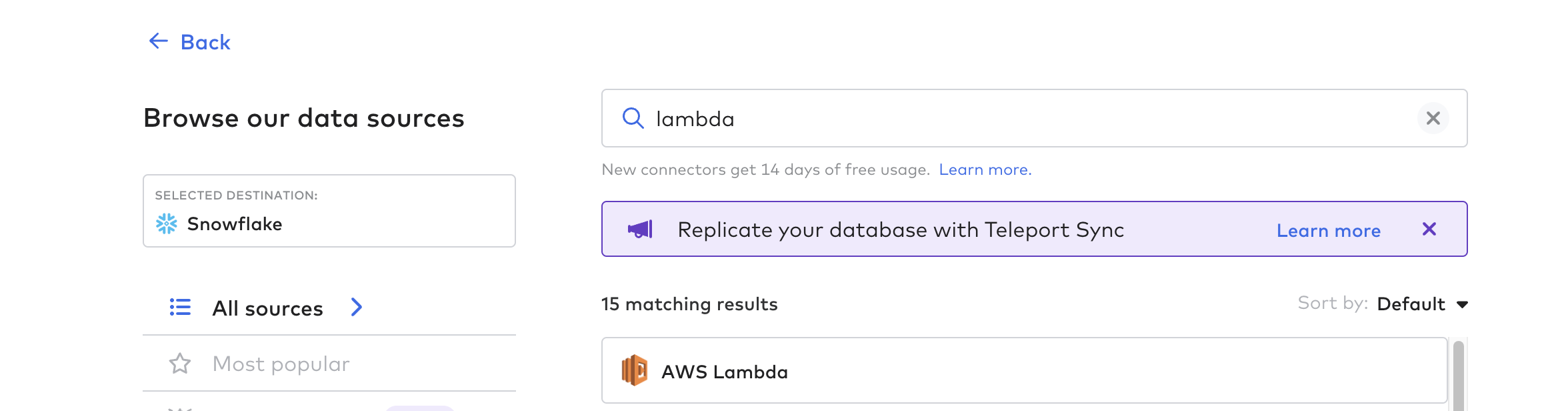
Следуйте инструкциям in-Fivetran по созданию функции Lambda на AWS с соответствующими ролями и разрешениямиСм. ссылку на шаблон функции Lambda в качестве отправной точкиНиже приведены несколько полезных советов:
- Вам придется создать два слоя: один - для библиотеки tulip, другой - для библиотеки pandas.
- API сообщества Tulip можно посмотреть здесь
- В качестве альтернативы можно загрузить zip-файл здесь (Он уже подготовлен для добавления в слой
- Вы можете легко добавить слой pandas в AWS, как показано ниже
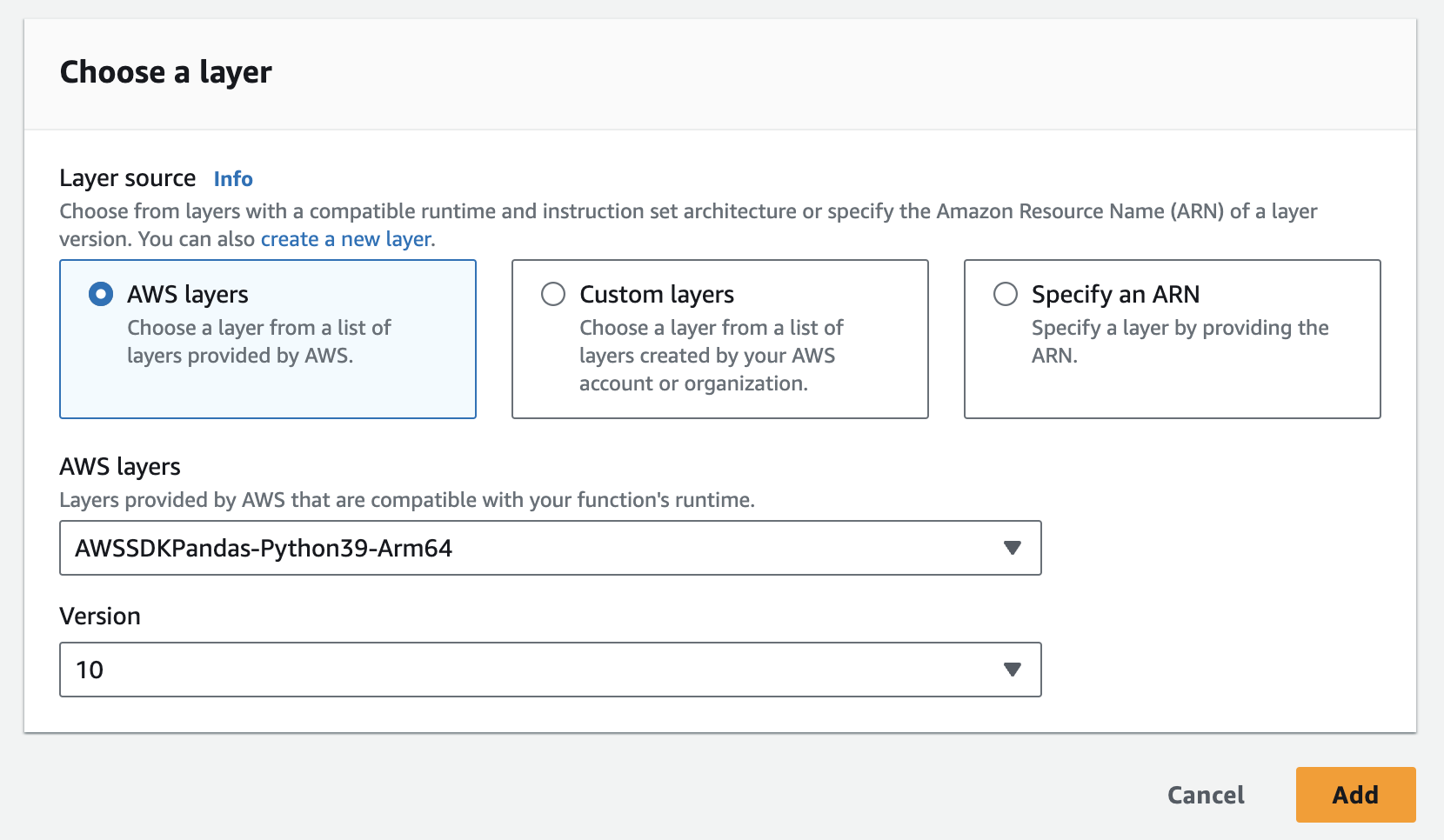
- Вам придется добавить экземпляр, API Key и API Secret в качестве переменных окружения в лямбда-функцию. Возможно, придется обновить настройки времени выполнения, чтобы увеличить время таймаута и используемую память. Ниже приведен снимок экрана для обновления настроек
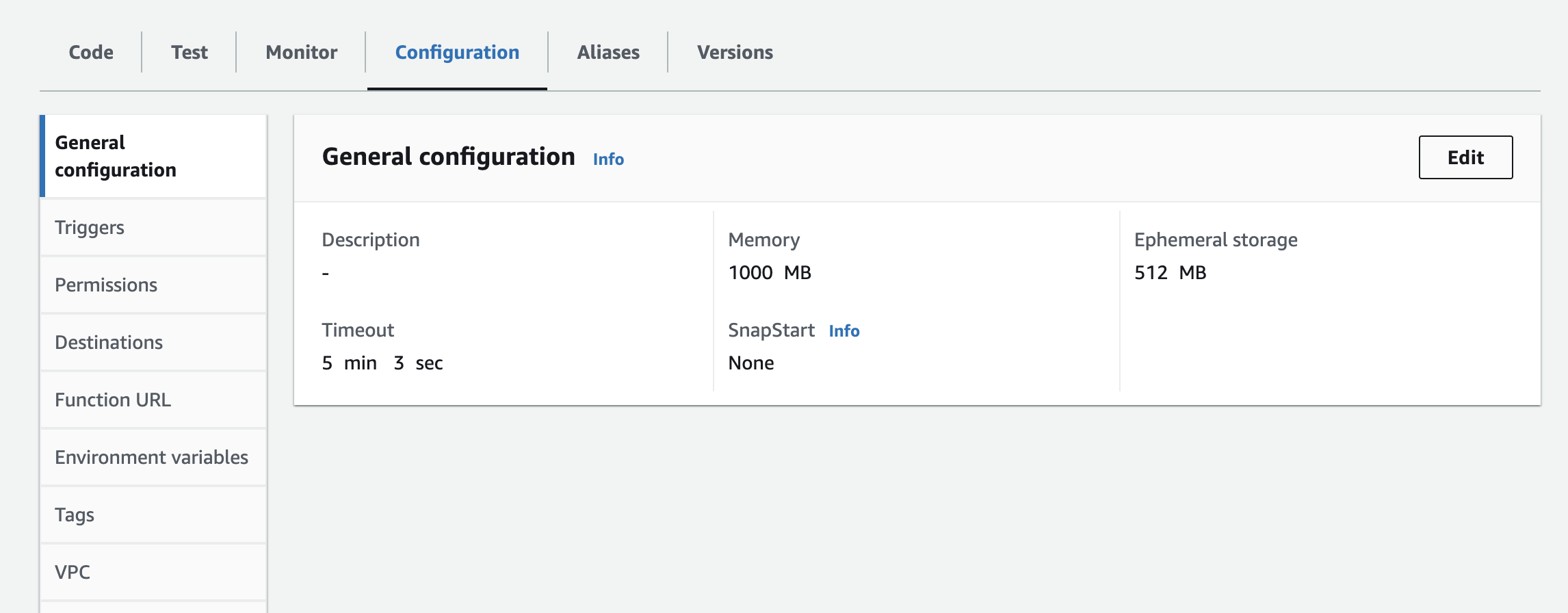
Следующие шаги
После того как функция коннектора заработает, можно настроить частоту обновления, просмотреть информацию о таблицах Tulip в целевой базе данных или Хранилище данных и другие дополнительные функции.
Некоторые конкретные примеры использования этого конвейера данных: * Аналитика и обработка данных Tulip на уровне предприятия * Пакетная автоматизация с корпоративными системами * Контекстуализация с Хранилищами данных и Озерами данных
Дополнительные ресурсы
Обратиться в компанию Fivetran за дополнительной поддержкой можно здесьОбратитьсяв компанию Fivetran за дополнительной поддержкой можно здесь * Кроме того, компания предоставила форму для внесения корректировок и запросов по упрощению интеграции таблиц Tulip. Оставить отзыв и запрос можно здесь