
Fivetranとの統合でチューリップのデータエンジニアリングを効率化
目的
Tulipとのデータエンジニアリングパイプラインの合理化により、企業全体でのTulipテーブルデータの利用が可能になります。
セットアップ
Fivetranアカウント(無料版あり) * AWS(または他のクラウドアカウント) * チューリップテーブルのデータを受け取るためのデータベースまたはデータウェアハウス * Pythonの高度な知識
どのように動作するか
このFivetran自動化セットアップは、以下のステップで動作します:
- Fivetranアカウントのセットアップ
- デスティネーションを作成する(例:Snowflake)
- AWS Lambda関数でConnector関数を作成する
- AWS Lambda関数を作成
- コネクタ関数を確定する
- Fivetranコネクタをテストし、リフレッシュ頻度を調整する
Fivetranはラムダ関数を使用して、スケジュールベースでチューリップテーブルのデータを自動的に取得し、デスティネーションデータベースまたはデータウェアハウスを更新します。サンプルは、リフレッシュされた新しいデータでテーブルを書き換えるシンプルな関数です。イベントベースのトリガーを改良するために、機能を追加することができます。
セットアップ手順
Fivetranアカウントのセットアップ
まず、Fivetranアカウントをセットアップする必要があります。Fivetranは、月間のリフレッシュ回数に制限のある無料版を提供しています。
デスティネーションの設定
次に、Destinationsをクリックし、最初のデスティネーションを作成します。これは基本的に、チューリップ・テーブルのデータを受け取るデータベースまたはデータウェアハウスです。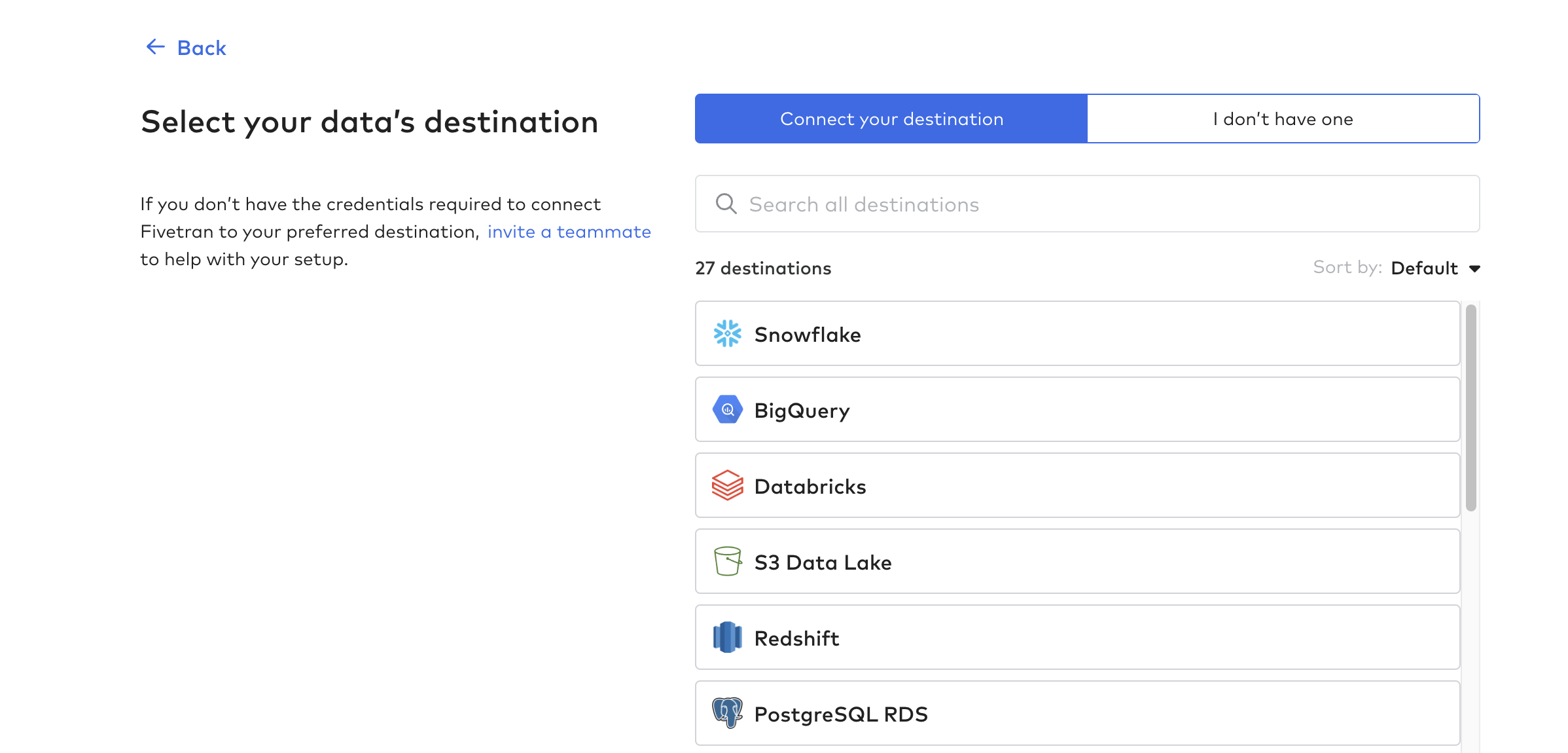
コネクタ関数の作成
Tulipからのデータパイプラインを自動化するためのプロセスです。AWS Lambda、Azure Functions、GCP Cloud Functionsなど、任意のクラウド関数を使用できます。この例では、AWS Lambdaを使用します。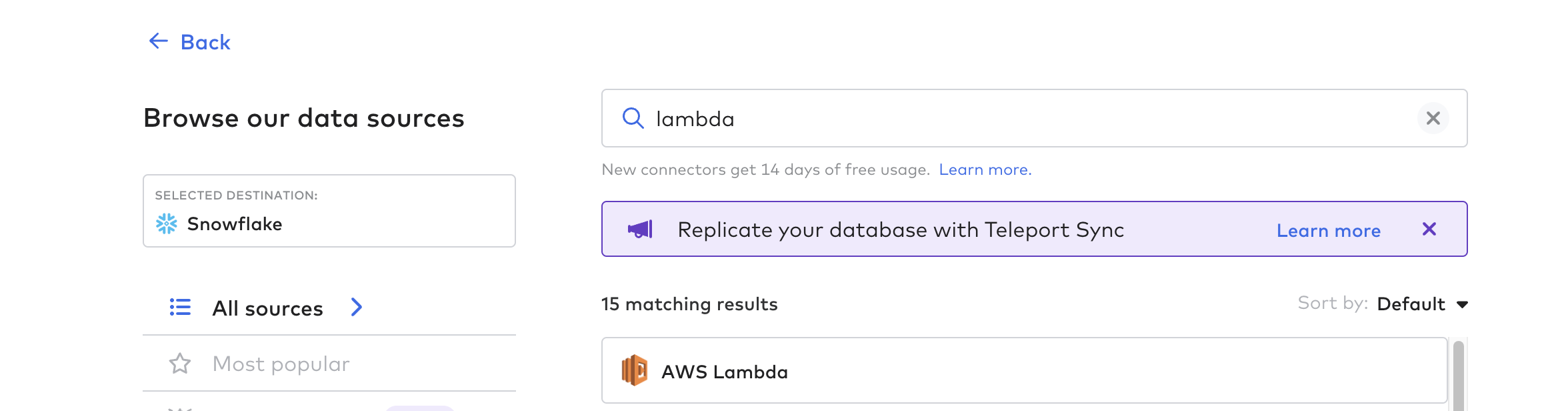
適切な役割と権限でAWS上にLambda関数を作成するためのin-Fivetranの手順に従ってください:
- 2つのレイヤーを作成する必要があります: 1つはtulipライブラリ用、もう1つはpandasライブラリ用です。
- TulipコミュニティAPIはこちらからご覧いただけます。
- zipファイルはこちらからダウンロードできます。
- pandasレイヤーは以下のAWSで簡単に追加できます。
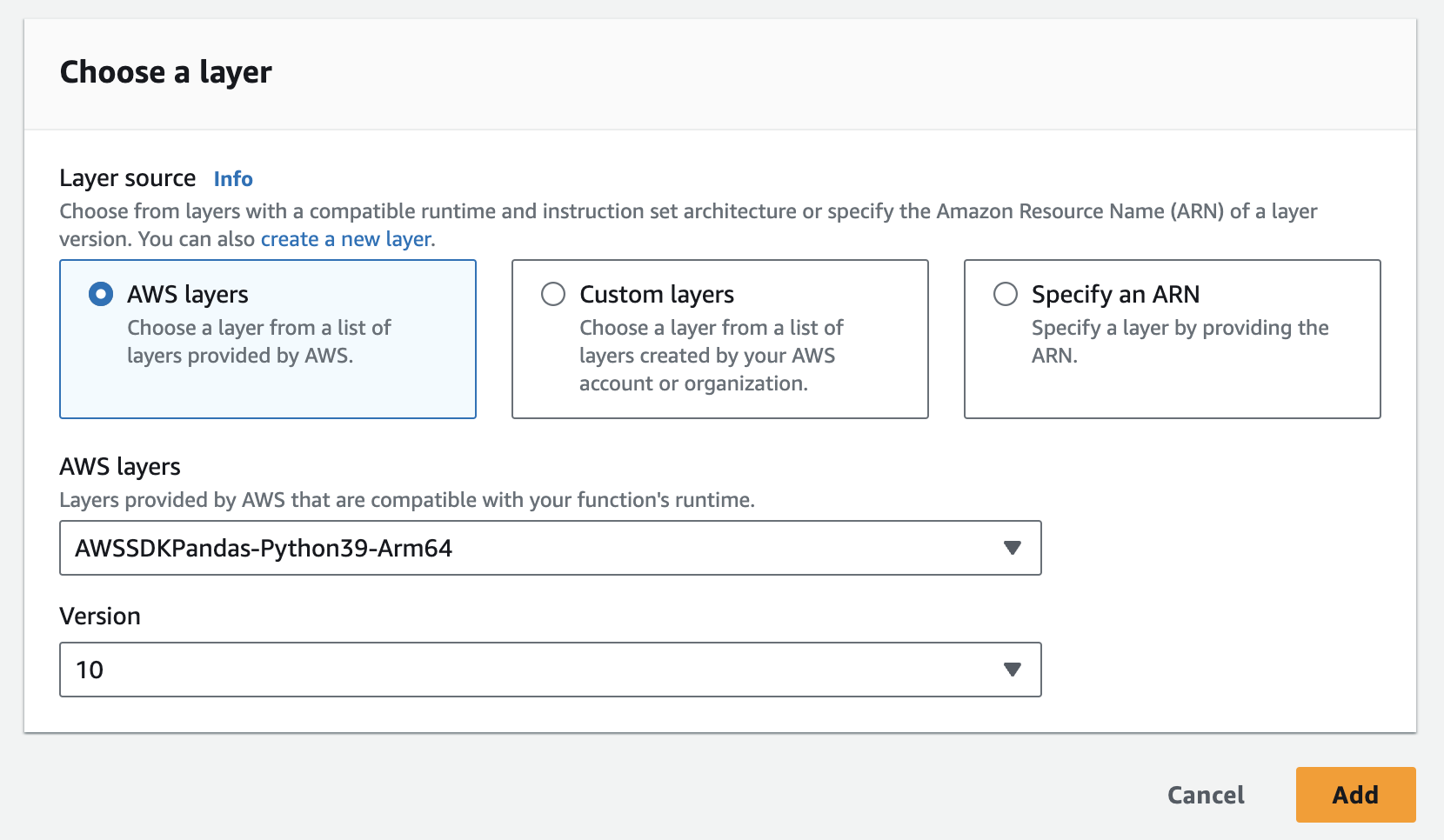
- インスタンス、API Key、API Secretを環境変数としてラムダ関数に追加する必要があります。タイムアウト時間と使用メモリを増やすために、ランタイム設定を更新する必要があるかもしれません。設定を更新するためのスクリーンショット
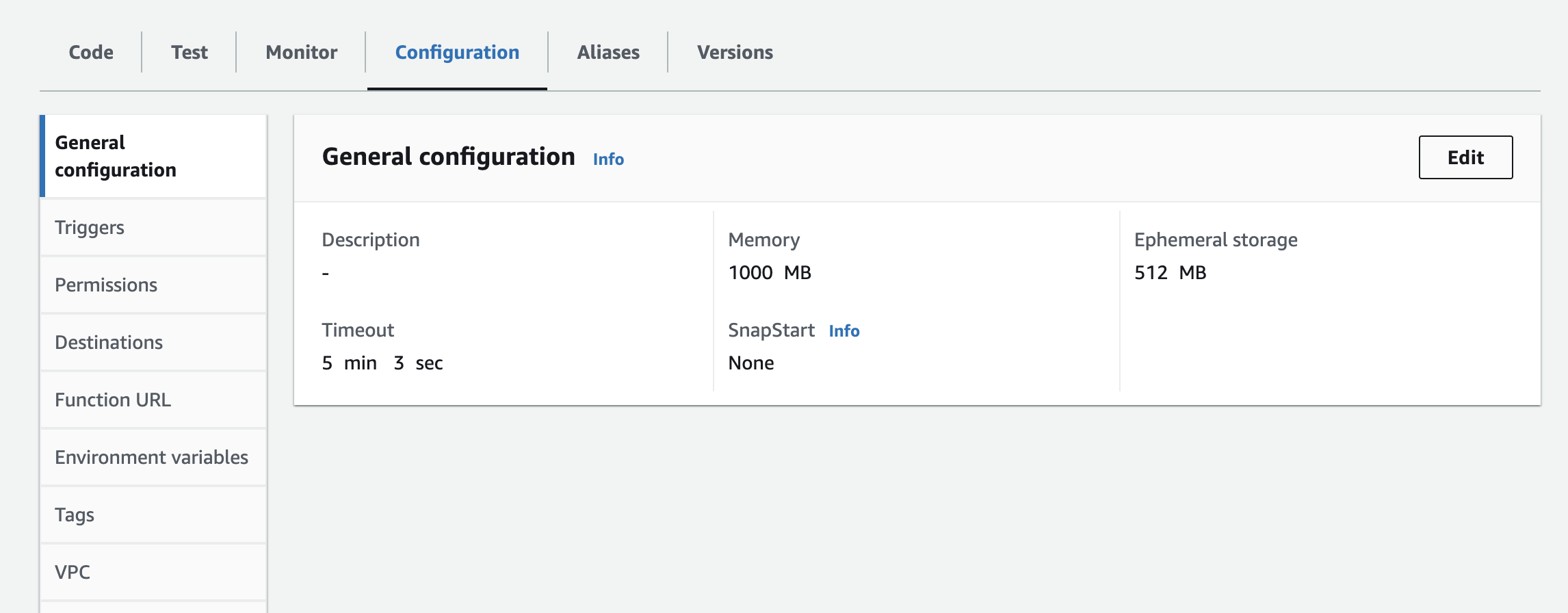
次のステップ
コネクター機能が動作したら、リフレッシュ頻度を調整したり、接続先のデータベースやデータウェアハウスでTulipテーブルの情報を表示したり、さらに機能を追加したりできます。
このデータパイプラインの具体的な使用例: * Tulipデータのエンタープライズレベルの分析とデータ処理 * エンタープライズシステムとのバッチ自動化 * データウェアハウスやデータレイクとのコンテキスト化
追加リソース
Fivetranへの追加サポートはこちらFivetranへの追加サポートはこちら * さらに、チューリップテーブルの統合を簡素化するための調整とリクエストを行うためのフォームを提供しています。フィードバックとリクエストはこちら