
利用 Fivetran 集成简化郁金香数据工程
目的
利用 Tulip 简化数据工程管道,在整个企业中使用 Tulip 表数据
设置
这需要以下设置: * Fivetran 账户(提供免费版本) * AWS(或其他云账户) * 用于接收 Tulip 表数据的数据库或数据仓库 * Python 高级知识
工作原理
Fivetran 自动化设置的工作步骤如下:
- 设置 Fivetran 账户
- 创建目的地(如 Snowflake)
- 使用 AWS Lambda 函数创建连接器函数
- 创建 AWS Lambda 函数
- 最终确定连接器功能
- 测试 Fivetran 连接器并调整刷新频率
Fivetran 使用 lambda 函数按计划自动获取郁金香表数据,并更新目标数据库或数据仓库。所包含的示例是一个用新的刷新数据重写表的简单函数。还可添加其他功能,以改进基于事件的触发器。
设置说明
设置 Fivetran 账户
首先,你需要建立一个 Fivetran 账户。他们提供免费版本,每月刷新次数有限。
设置目的地
然后,点击 "目的地",创建第一个目的地。这就是接收郁金香表数据的数据库或数据仓库。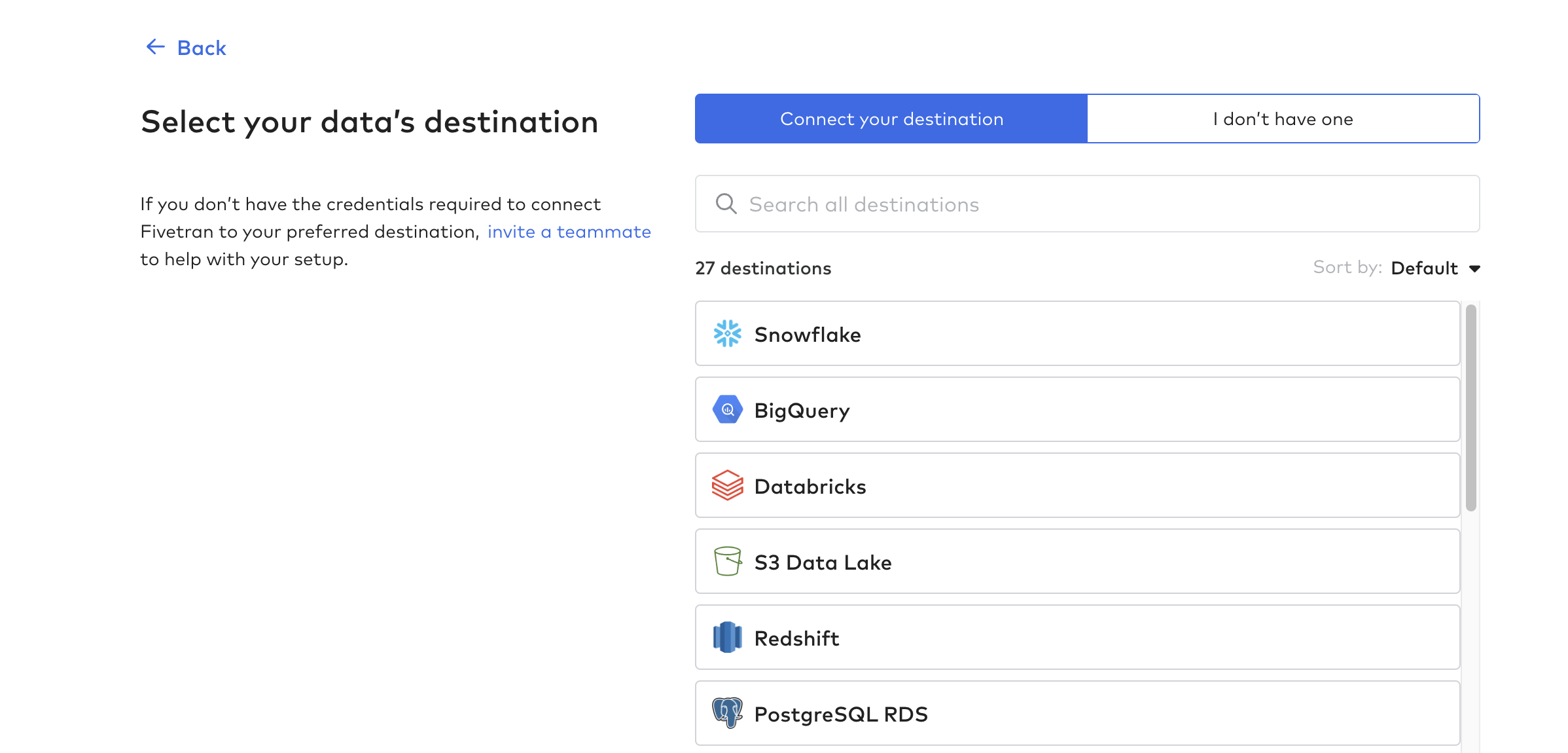
创建连接器功能
然后,创建连接器功能;这是从 Tulip 自动传输数据的过程。您可以使用任何云函数,如 AWS Lambda、Azure Functions 或 GCP Cloud Functions。在本示例中,我们将使用 AWS Lambda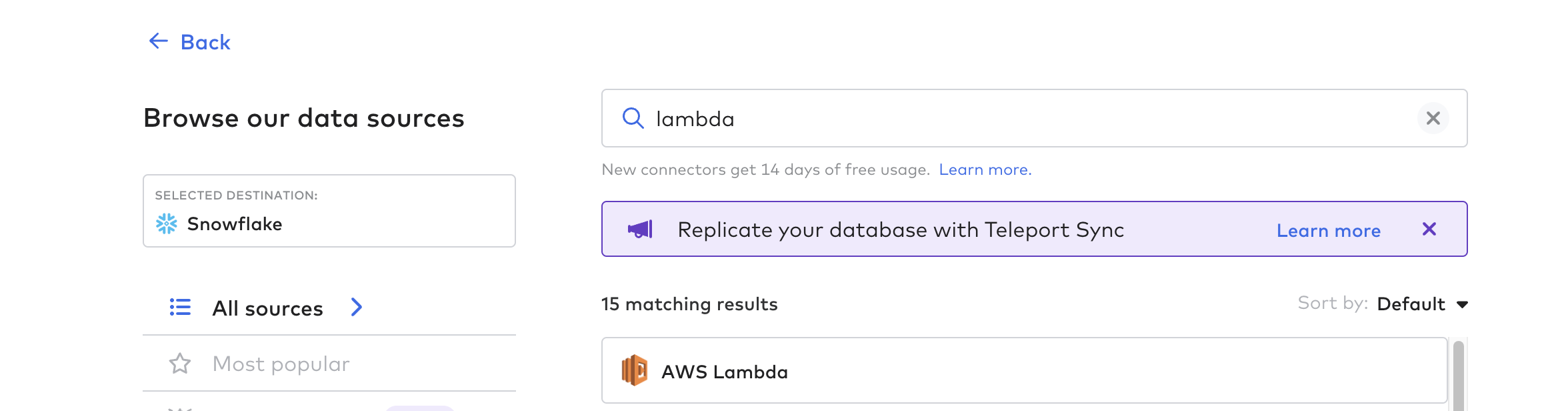
请按照 Fivetran 中的说明,使用适当的角色和权限在 AWS 上创建一个 Lambda函数 请参见 lambda 函数模板链接,作为起点以下是一些有用的提示:
- 您需要创建两个层:一个用于郁金香库,另一个用于 pandas 库。
- 你需要将实例、API Key 和 API Secret 作为环境变量添加到 lambda 函数中。你可能需要更新运行时设置,以增加超时时间和内存使用量。更新配置的截图如下
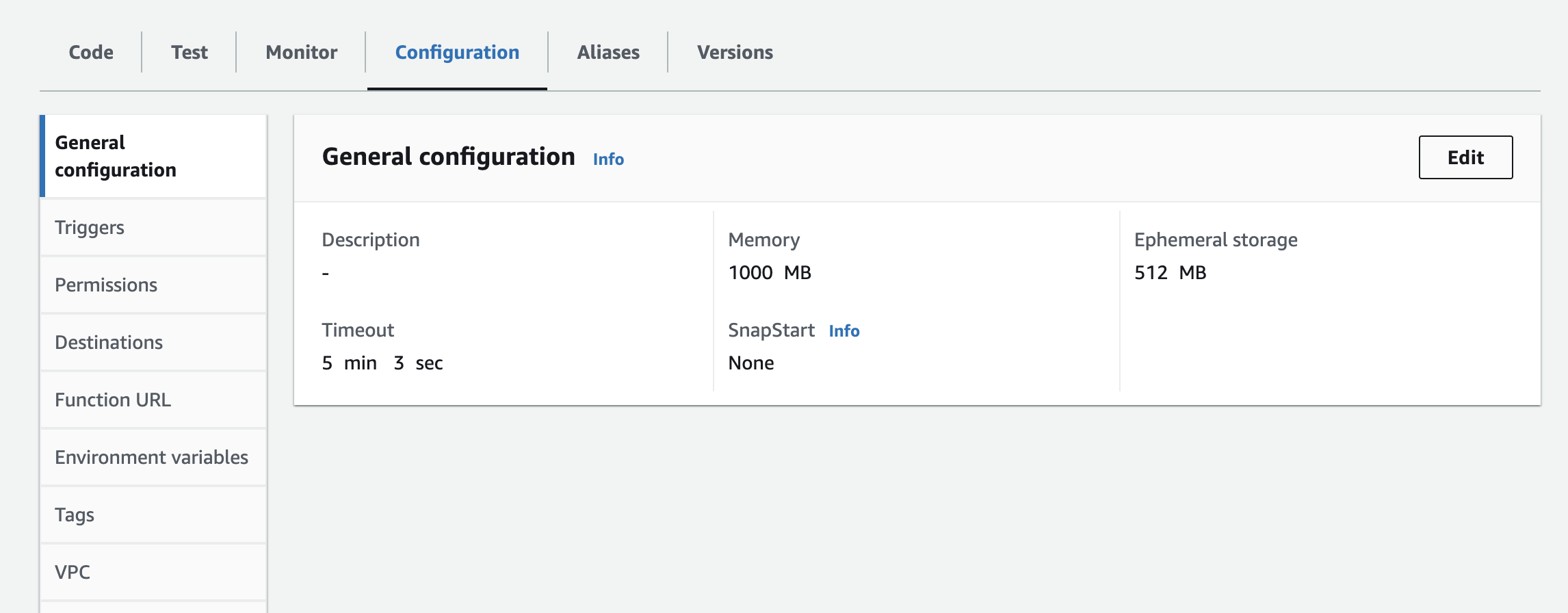
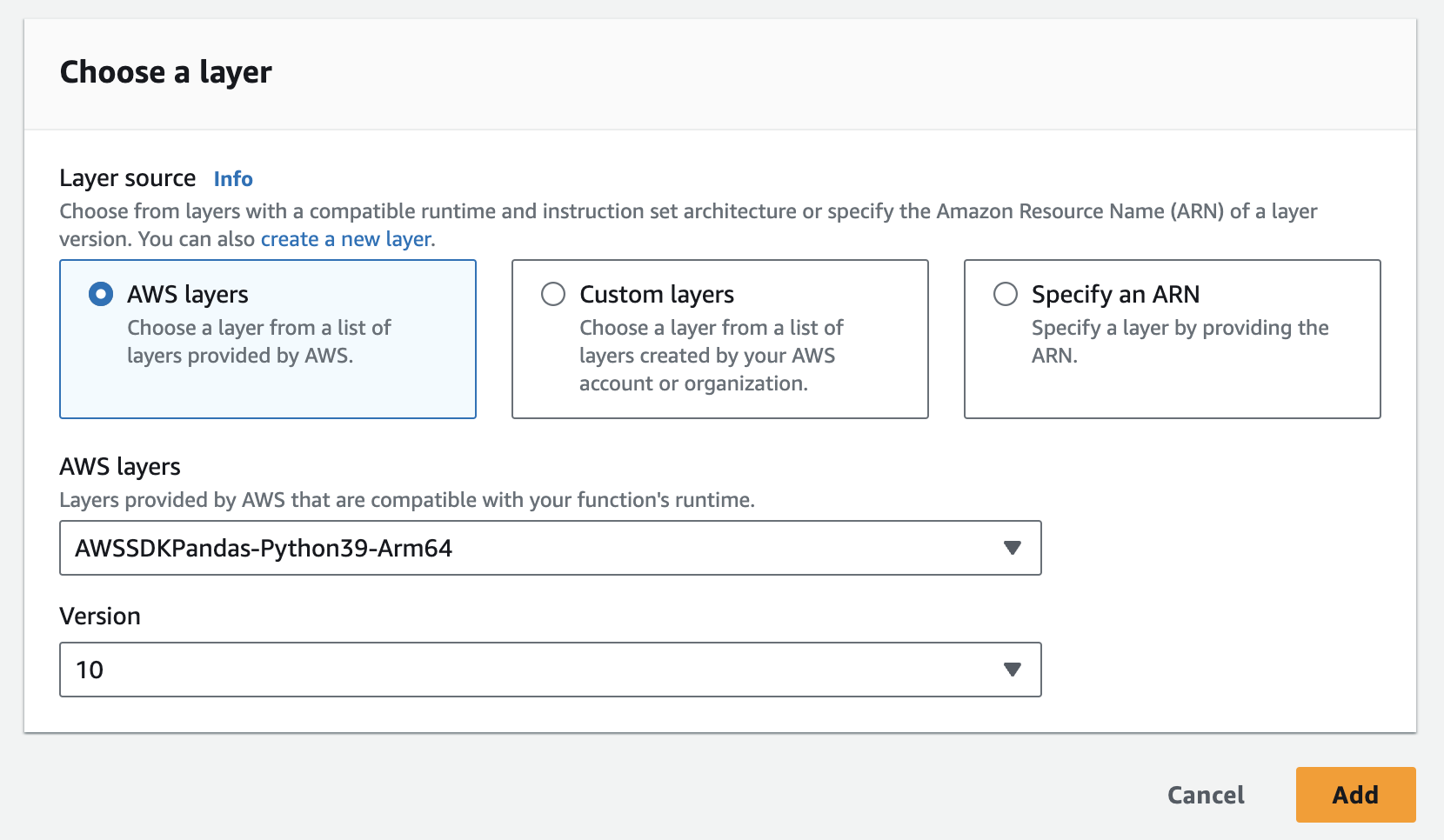
下一步
一旦连接器功能正常运行,你就可以调整刷新频率,查看目标数据库或数据仓库中的郁金香表信息,以及其他更多功能。
该数据管道的一些特定用例: * 企业级分析和 Tulip 数据的数据处理 * 企业系统的批量自动化 * 数据仓库和数据湖的上下文化
其他资源
点击此处联系 Fivetran 以获取更多支持点击此处联系Fivetran 以获取更多支持 * 此外,他们还提供了一份表格,用于调整和请求简化 Tulip 表格集成。在此提供反馈和请求