
Simplifique a engenharia de dados da Tulip com a integração do Fivetran
Objetivo
Otimizar os pipelines de engenharia de dados com o Tulip permite o uso dos dados das tabelas do Tulip em toda a empresa.
Configuração
Isso requer o seguinte para a configuração: * Conta Fivetran (a versão gratuita está disponível) * AWS (ou outra conta na nuvem) * Banco de dados ou data warehouse para receber dados das tabelas Tulip * Conhecimento de alto nível de Python
Como funciona
Essa configuração de automação do Fivetran funciona com as seguintes etapas:
- Configurar a conta Fivetran
- Criar destino (por exemplo, Snowflake)
- Criar função de conector com a função AWS Lambda
- Criar a função AWS Lambda
- Finalizar a função do conector
- Testar o conector Fivetran e ajustar a frequência de atualização
O Fivetran usa a função lambda para buscar automaticamente os dados das tabelas de tulipas em uma base programada e atualizar os bancos de dados ou data warehouses de destino. O exemplo incluído é uma função simples que reescreve a tabela com dados novos e atualizados. Funcionalidades adicionais podem ser adicionadas para acionadores aprimorados baseados em eventos.
Instruções de configuração
Configurar a conta Fivetran
Primeiro, você precisará configurar uma conta no Fivetran. Eles oferecem uma versão gratuita com um número limitado de atualizações por mês
Configurar destino
Em seguida, clique em Destinations (Destinos) e crie seu primeiro destino. Esse é essencialmente o banco de dados ou data warehouse que receberá os dados das tabelas Tulip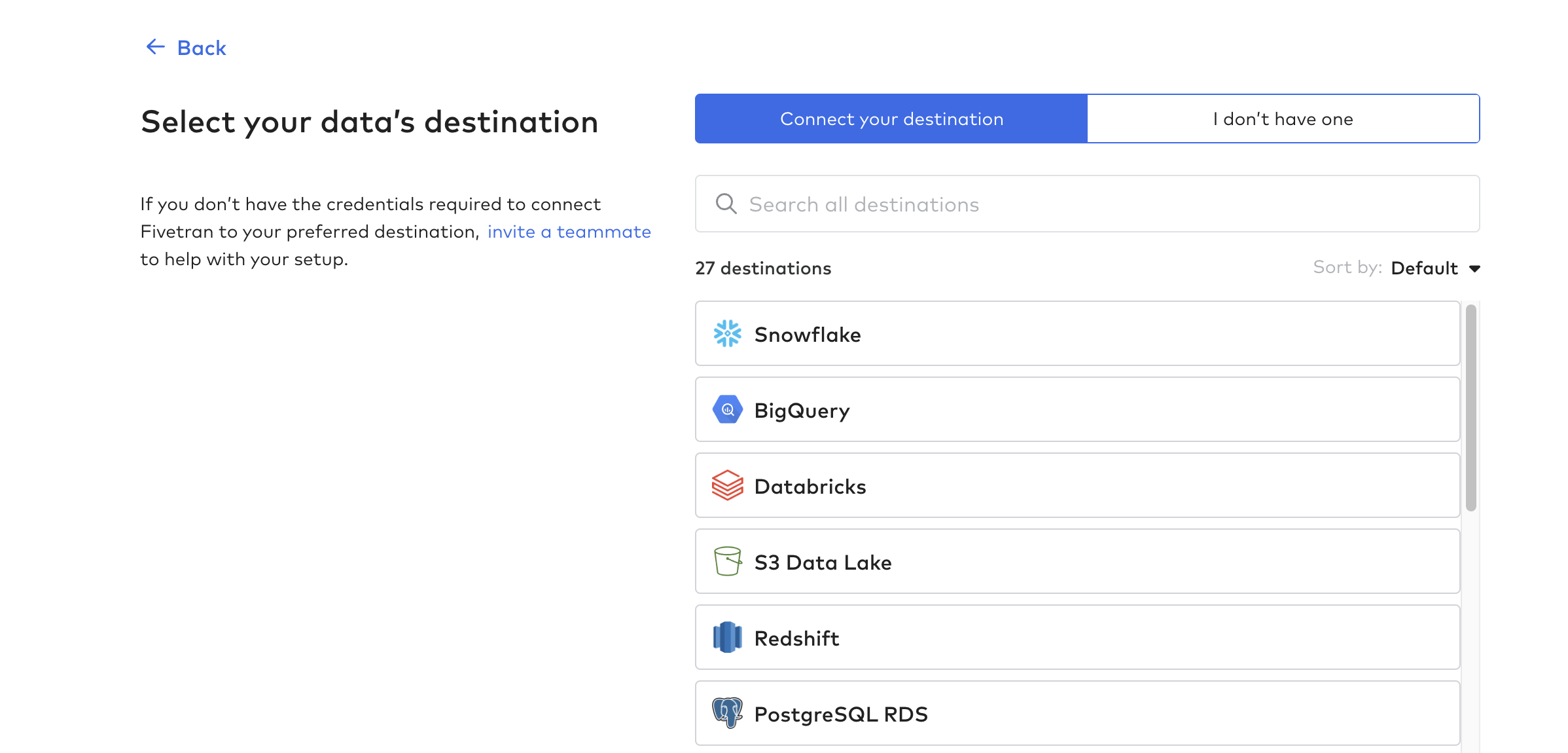
Criar função de conector
Em seguida, crie a função de conector; esse é o processo para automatizar o pipeline de dados do Tulip. Você pode usar qualquer função de nuvem, como AWS Lambda, Azure Functions ou GCP Cloud Functions. Para este exemplo, usaremos o AWS Lambda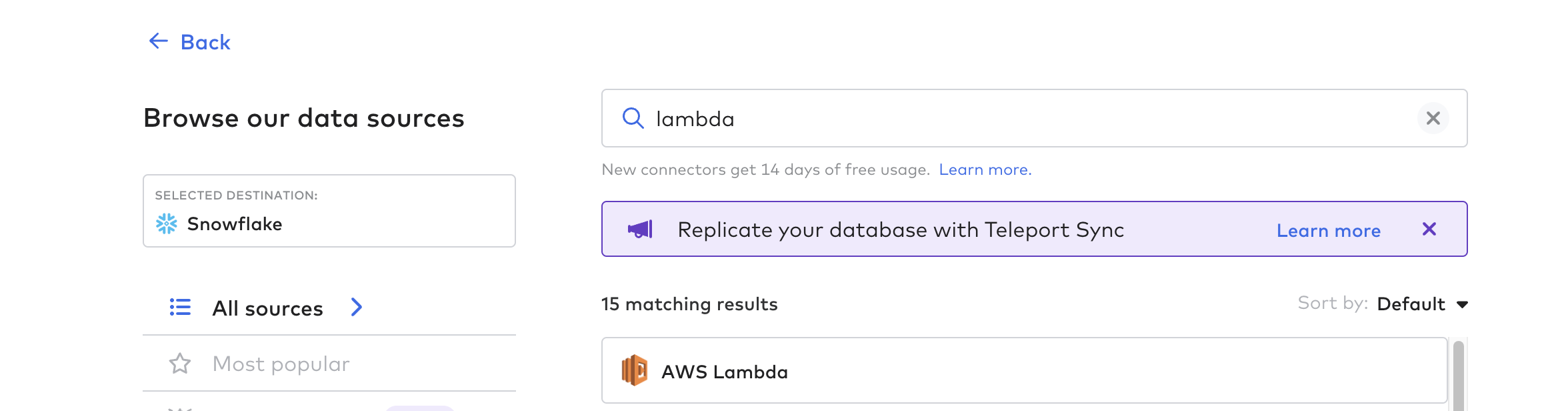
Siga as instruções do in-Fivetran para criar uma função Lambda no AWS com as funções e permissões apropriadasVeja o link para o modelo de função lambda como ponto de partidaAbaixo estão algumas dicas úteis:
- Você terá que criar duas camadas: uma para a biblioteca tulip; a outra para a biblioteca pandas
- Você pode ver a API da comunidade Tulip aqui
- Como alternativa, você pode fazer o download do arquivo zip aqui (ele foi preparado para ser adicionado a uma camada)
- Você pode adicionar facilmente a camada do pandas no AWS abaixo
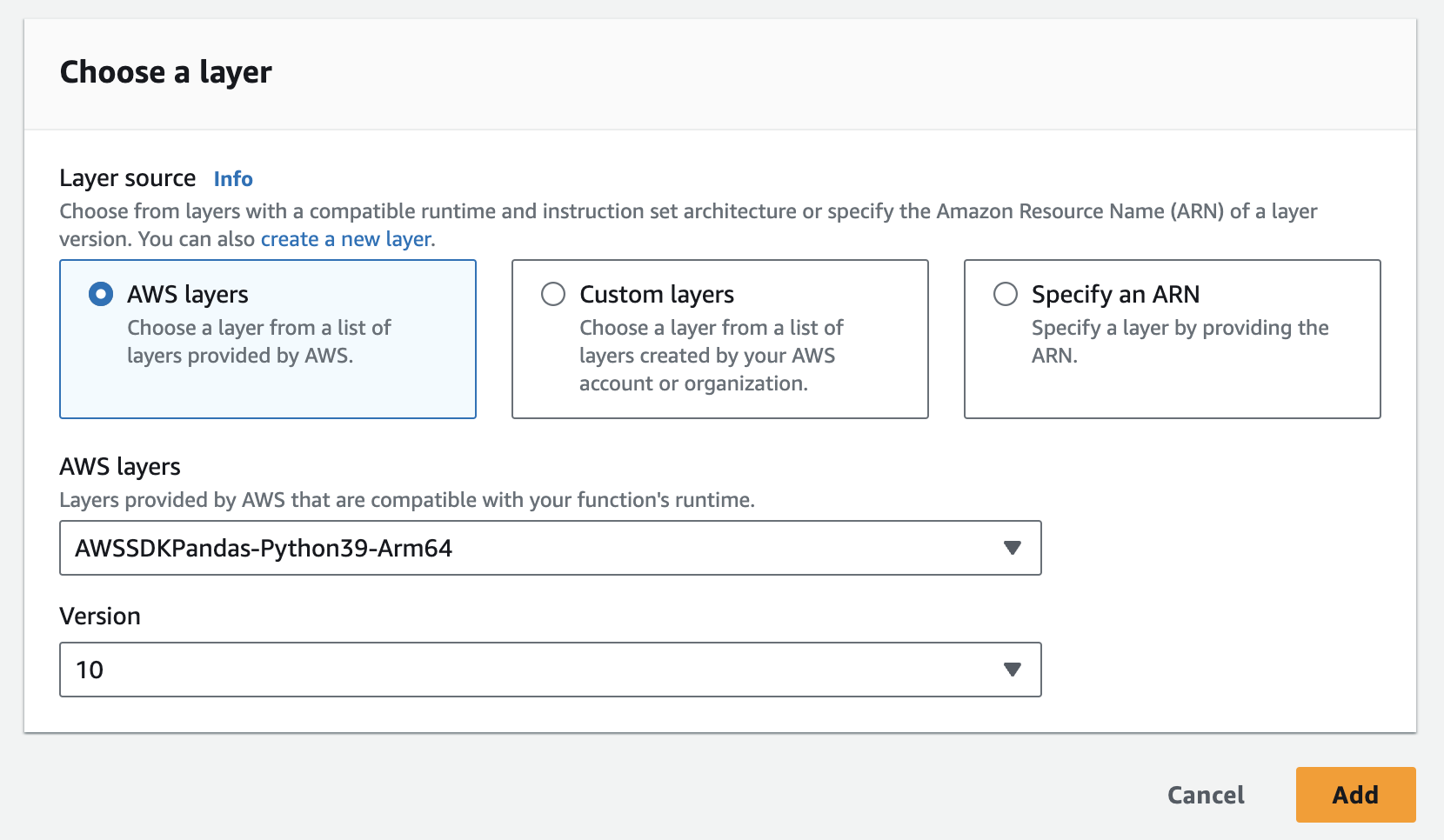
- Você terá de adicionar a instância, a chave da API e o segredo da API como variáveis de ambiente à função lambda. Talvez seja necessário atualizar as configurações de tempo de execução para aumentar o tempo limite e a memória usada. Captura de tela abaixo para atualizar a configuração
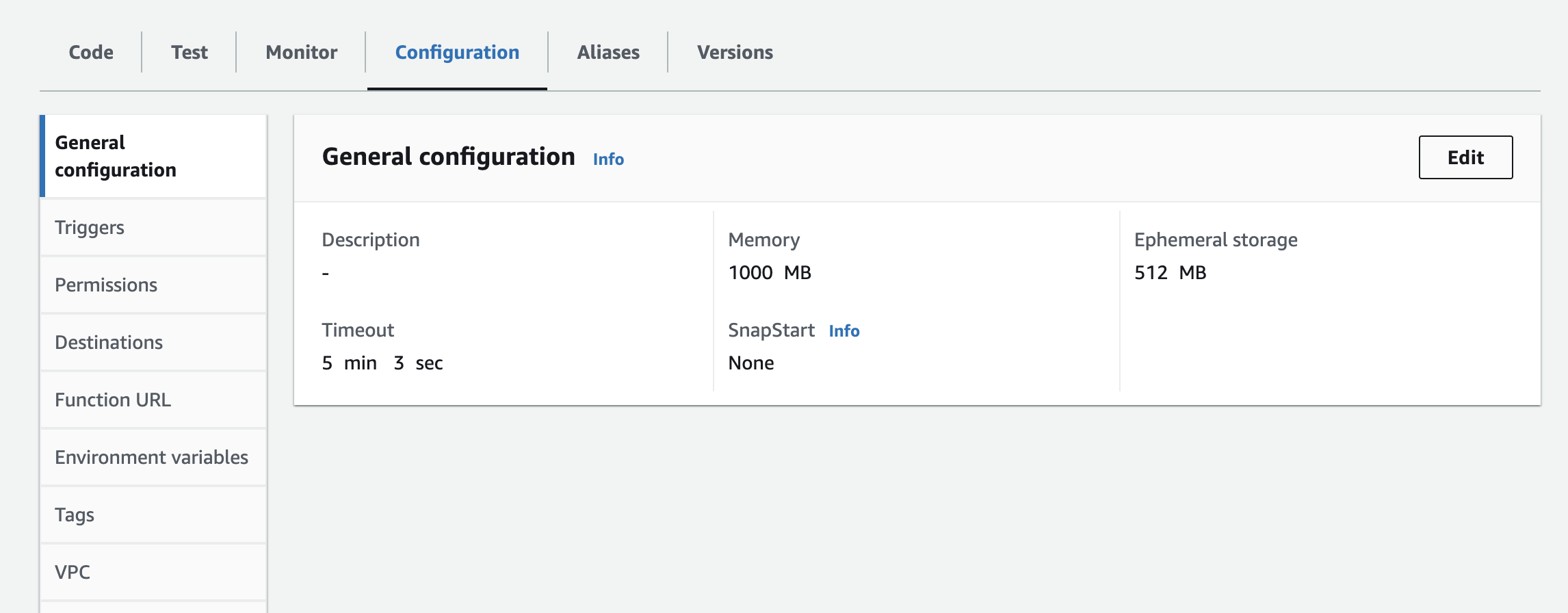
Próximas etapas
Quando a função de conector estiver funcionando, você poderá ajustar a frequência de atualização, visualizar as informações das tabelas Tulip no banco de dados de destino ou no Data Warehouse e outras funcionalidades adicionais
Alguns casos de uso específicos para esse pipeline de dados: * Análise de nível empresarial e processamento de dados do Tulip * Automações de lote com sistemas empresariais * Contextualização com Data Warehouses e Data Lakes
Recursos adicionais
Entre em contato coma Fivetran para obter suporte adicional aquiEntre em contato com a Fivetran para obter suporte adicional aqui * Além disso, eles forneceram um formulário para fazer ajustes e solicitações de integração simplificada das tabelas Tulip. Forneça comentários e solicitações aqui