
Agilice la ingeniería de datos de Tulip con la integración de Fivetran
Propósito
La racionalización de los procesos de ingeniería de datos con Tulip permite el uso de los datos de las tablas de Tulip en toda la empresa.
Configuración
Esto requiere lo siguiente para la configuración: * Fivetran cuenta (Free Version está disponible) * AWS (u otra cuenta en la nube) * Base de datos o almacén de datos para la recepción de datos Tulip Tables * Alto nivel de conocimiento de Python
Cómo funciona
Esta configuración de automatización de fivetran funciona con los siguientes pasos:
- Configurar cuenta Fivetran
- Crear destino (por ejemplo, Snowflake)
- Crear función Connector con función AWS Lambda
- Crear función AWS Lambda
- Finalizar la función de conector
- Probar el conector Fivetran y ajustar la frecuencia de actualización
Fivetran utiliza la función lambda para obtener automáticamente los datos de las tablas tulipán de forma programada y actualizar las bases de datos de destino o los almacenes de datos. El ejemplo incluido es una función sencilla que reescribe la tabla con datos nuevos y actualizados. Se pueden añadir funciones adicionales para mejorar los desencadenadores basados en eventos.
Instrucciones de configuración
Configuración de la cuenta de Fivetran
En primer lugar, deberá crear una cuenta en Fivetran. Ofrecen una versión gratuita con un número limitado de actualizaciones al mes.
Configurar destino
A continuación, haga clic en Destinos y cree su primer destino. Esta es esencialmente la base de datos o almacén de datos que recibirá los datos de las tablas Tulip.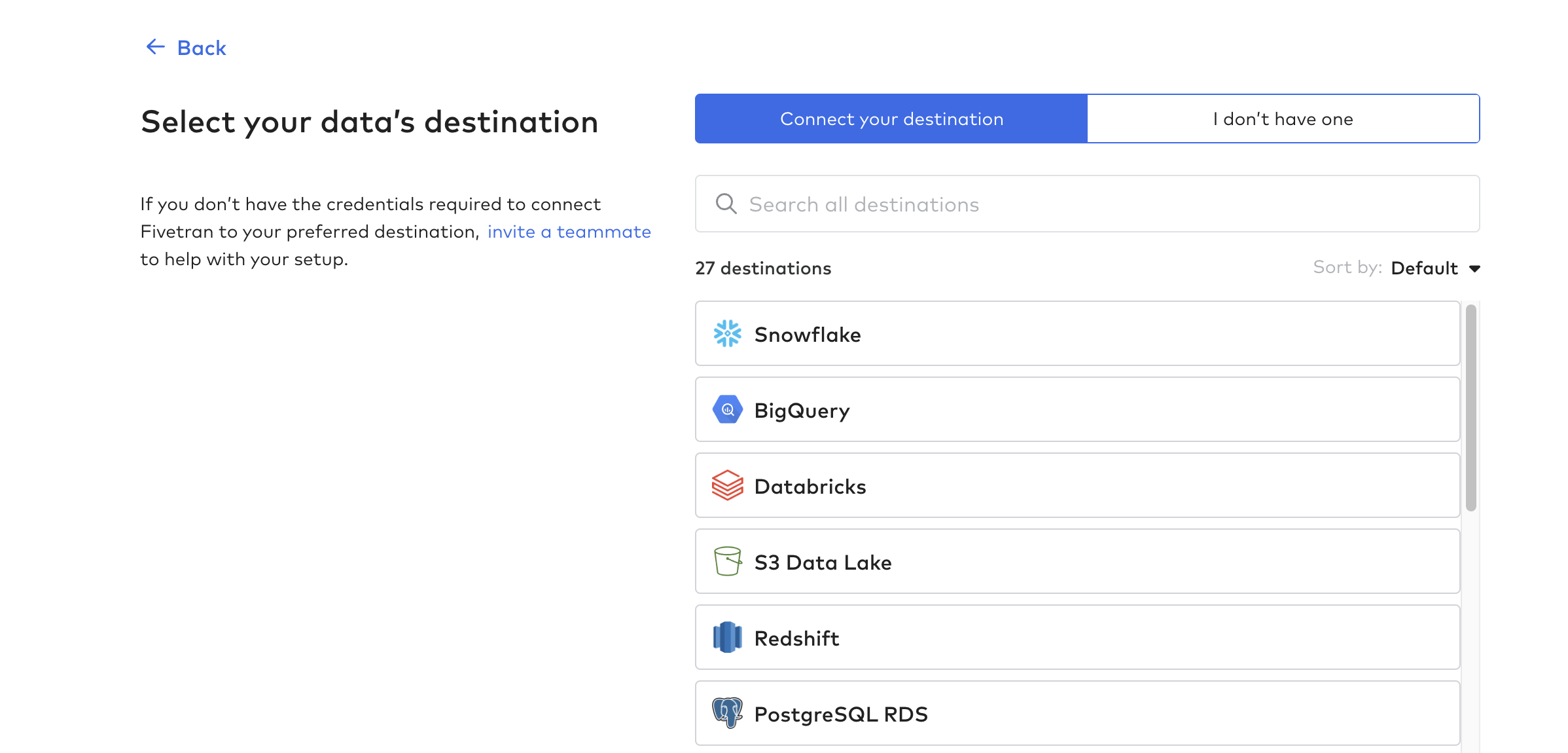
Crear función de conexión
A continuación, cree la función de conector; este es el proceso para automatizar la canalización de datos desde Tulip. Puedes utilizar cualquier función en la nube como AWS Lambda, Azure Functions o GCP Cloud Functions. Para este ejemplo, utilizaremos AWS Lambda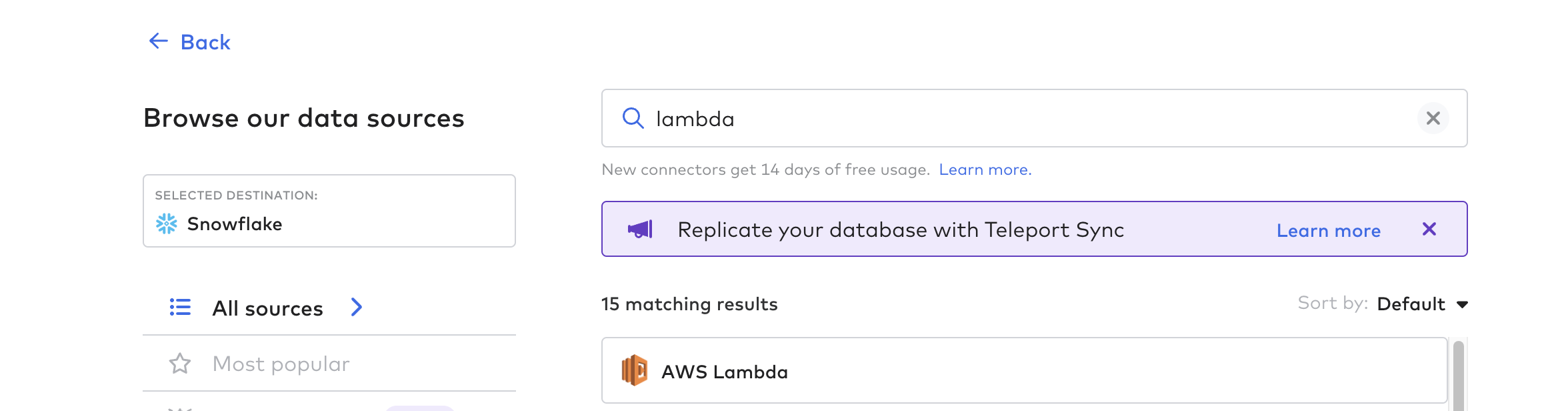
Siga las instrucciones de in-Fivetran para crear una función Lambda en AWS con los roles y permisos adecuadosConsulte el enlace para la plantilla de la función lambda como punto departida A continuación encontrará algunos consejos útiles:
- Tendrás que crear dos capas: una es para la librería tulip; la otra es para la librería pandas
- Puedes ver la API de la comunidad Tulip aquí
- Puedes descargar el archivo zip aquí alternativamente (Esto ha sido preparado para añadir a una capa
- Puedes añadir fácilmente la capa de pandas en AWS a continuación
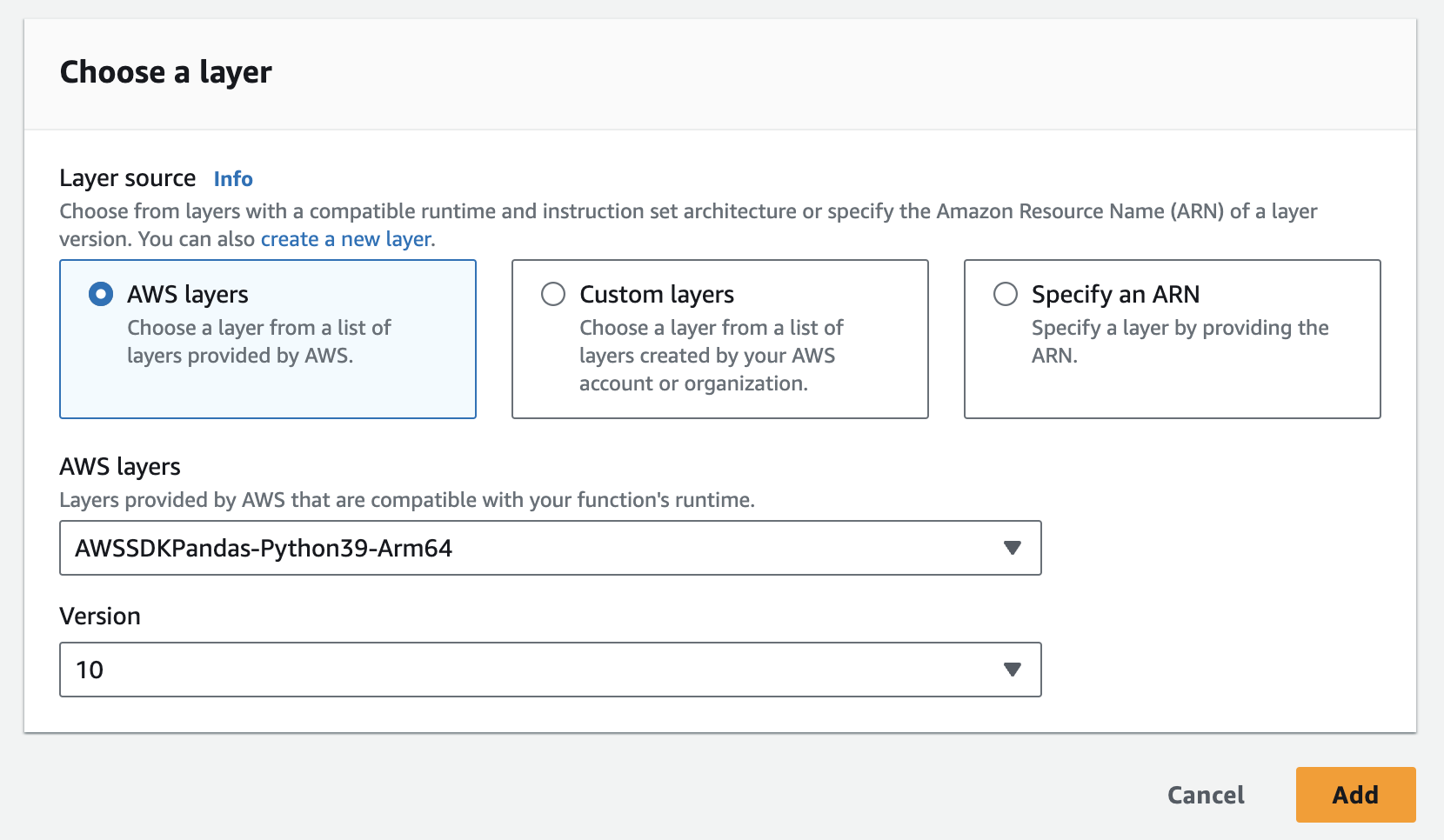
- Tendrás que añadir la instancia, API Key, y API Secret como variables de entorno a la función lambda. Es posible que tenga que actualizar la configuración de tiempo de ejecución para aumentar el tiempo de espera y la memoria utilizada. Captura de pantalla a continuación para actualizar la configuración
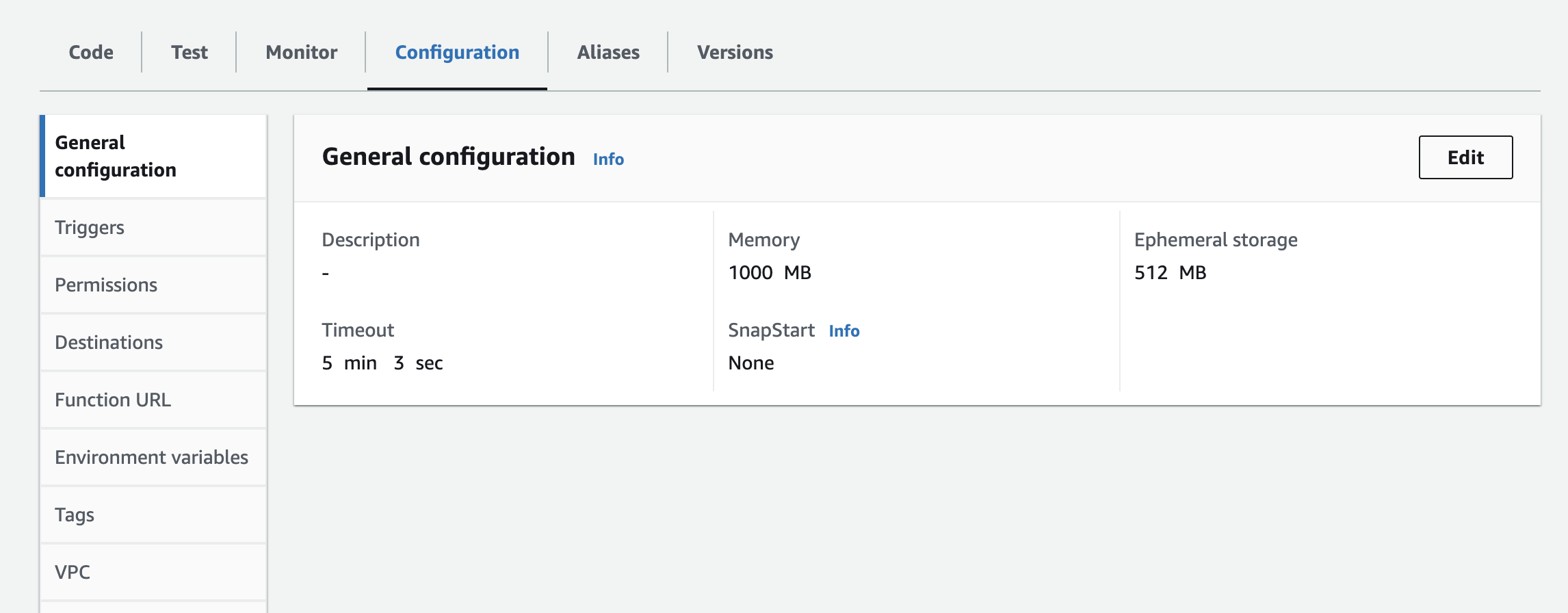
Pasos siguientes
Una vez que la función de conector está funcionando, puede ajustar la frecuencia de actualización, ver la información de las tablas de Tulip en la base de datos de destino o Data Warehouse y más funcionalidad adicional.
Algunos casos de uso específicos para esta canalización de datos: * Análisis a nivel empresarial y procesamiento de datos de Tulip * Automatizaciones por lotes con sistemas empresariales * Contextualización con Data Warehouses y Data Lakes
Recursos adicionales
Póngase en contacto con Fivetran para obtener soporte adicionalaquíPóngase encontacto con Fivetran para obtener soporte adicional aquí * Además, han proporcionado un formulario para realizar ajustes y solicitudes de integración simplificada de tablas Tulip. Envíe sus comentarios y solicitudes aquí