
Fivetran 통합을 통한 Tulip 데이터 엔지니어링 간소화
목적
Tulip으로 데이터 엔지니어링 파이프라인을 간소화하여 전사적으로 Tulip 테이블 데이터를 사용할 수 있습니다.
설정
설정에는 다음이 필요합니다.* Fivetran 계정(무료 버전 사용 가능)* AWS(또는 기타 클라우드 계정)* Tulip 테이블 데이터를 받기 위한 데이터베이스 또는 데이터 웨어하우스* Python에 대한 높은 수준의 지식이 필요합니다.
작동 방식
이 파이브트란 자동화 설정은 다음 단계로 작동합니다:
- 파이브트란 계정 설정
- 대상 생성(예: Snowflake)
- AWS 람다 함수로 커넥터 함수 생성
- AWS 람다 함수 생성
- 커넥터 기능 마무리
- Fivetran 커넥터 테스트 및 새로 고침 빈도 조정하기
Fivetran은 람다 함수를 사용하여 예약된 방식으로 튤립 테이블 데이터를 자동으로 가져와 대상 데이터베이스 또는 데이터 웨어하우스를 업데이트합니다. 포함된 예제는 새로 새로 고친 데이터로 테이블을 다시 작성하는 간단한 함수입니다. 이벤트 기반 트리거를 개선하기 위해 추가 기능을 추가할 수 있습니다.
설정 지침
파이브트란 계정 설정
먼저 Fivetran 계정을 설정해야 합니다. 한 달에 새로 고침 횟수가 제한된 무료 버전을 제공합니다.
목적지 설정
그런 다음 대상을 클릭하고 첫 번째 대상을 만듭니다. 이것은 기본적으로 Tulip 테이블 데이터를 수신할 데이터베이스 또는 데이터 웨어하우스입니다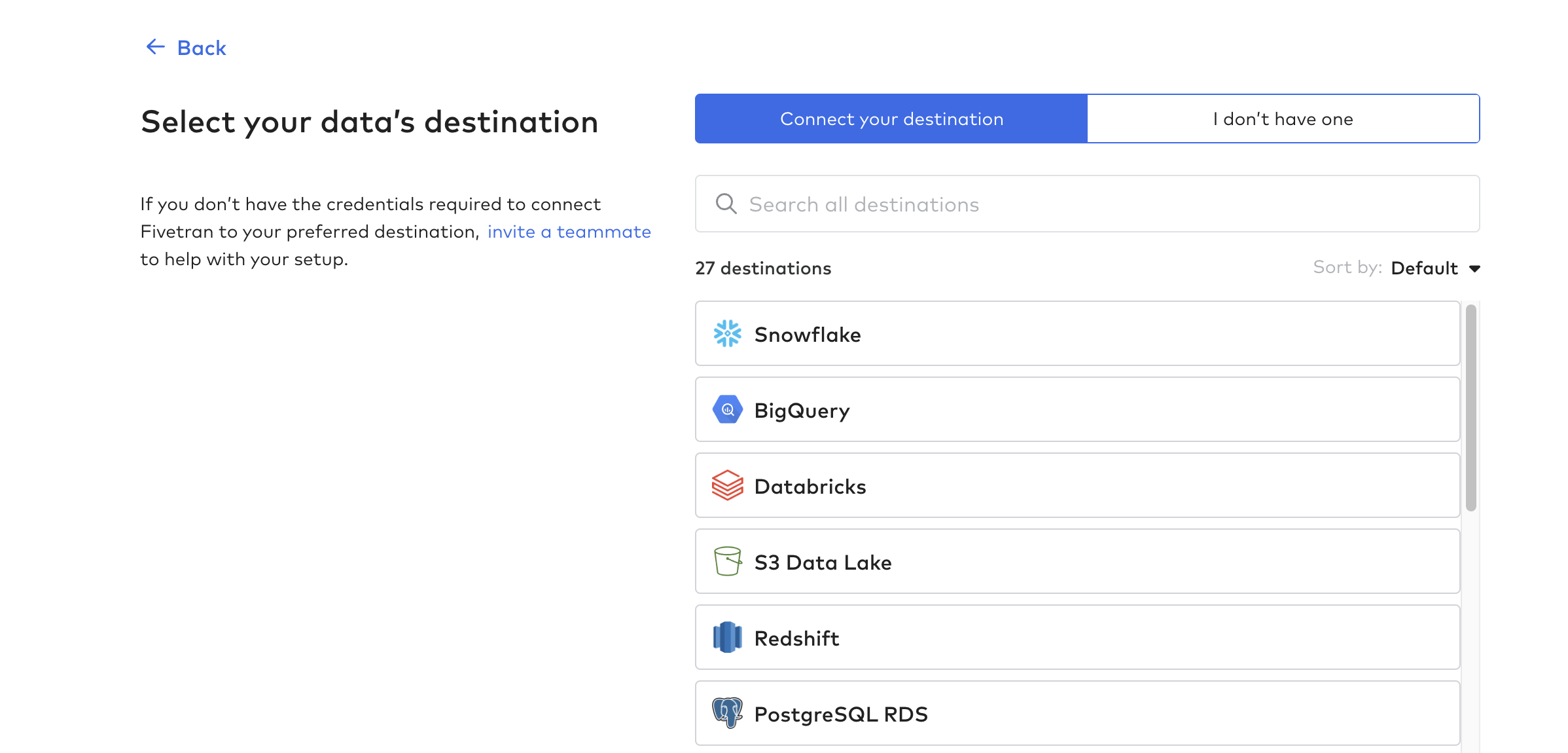
커넥터 함수 만들기
그런 다음 커넥터 함수를 생성합니다. 이것은 Tulip에서 데이터 파이프라인을 자동화하기 위한 프로세스입니다. AWS Lambda, Azure 함수 또는 GCP 클라우드 함수와 같은 모든 클라우드 함수를 사용할 수 있습니다. 이 예제에서는 AWS Lambda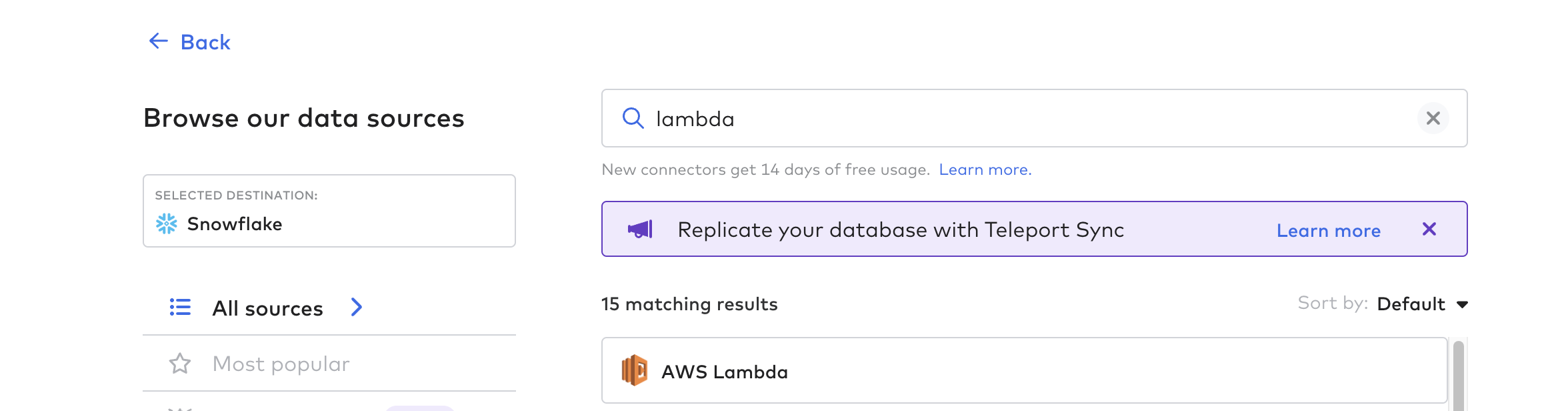 {height="" width=""}를 사용하겠습니다.
{height="" width=""}를 사용하겠습니다.
적절한 역할과 권한으로 AWS에서 람다 함수를 생성하려면 Fivetran 내 지침을 따르세요.람다 함수 템플릿을 시작점으로 삼아 링크를참조하세요.아래는몇 가지 유용한 팁입니다:
- 하나는 튤립 라이브러리용, 다른 하나는 판다 라이브러리용 레이어를 두 개 생성해야 합니다.
- 여기에서 튤립 커뮤니티 API를 볼 수 있습니다.
- 또는 여기에서 zip 파일을 다운로드할 수 있습니다(레이어에 추가할 수 있도록 준비되어 있습니다.
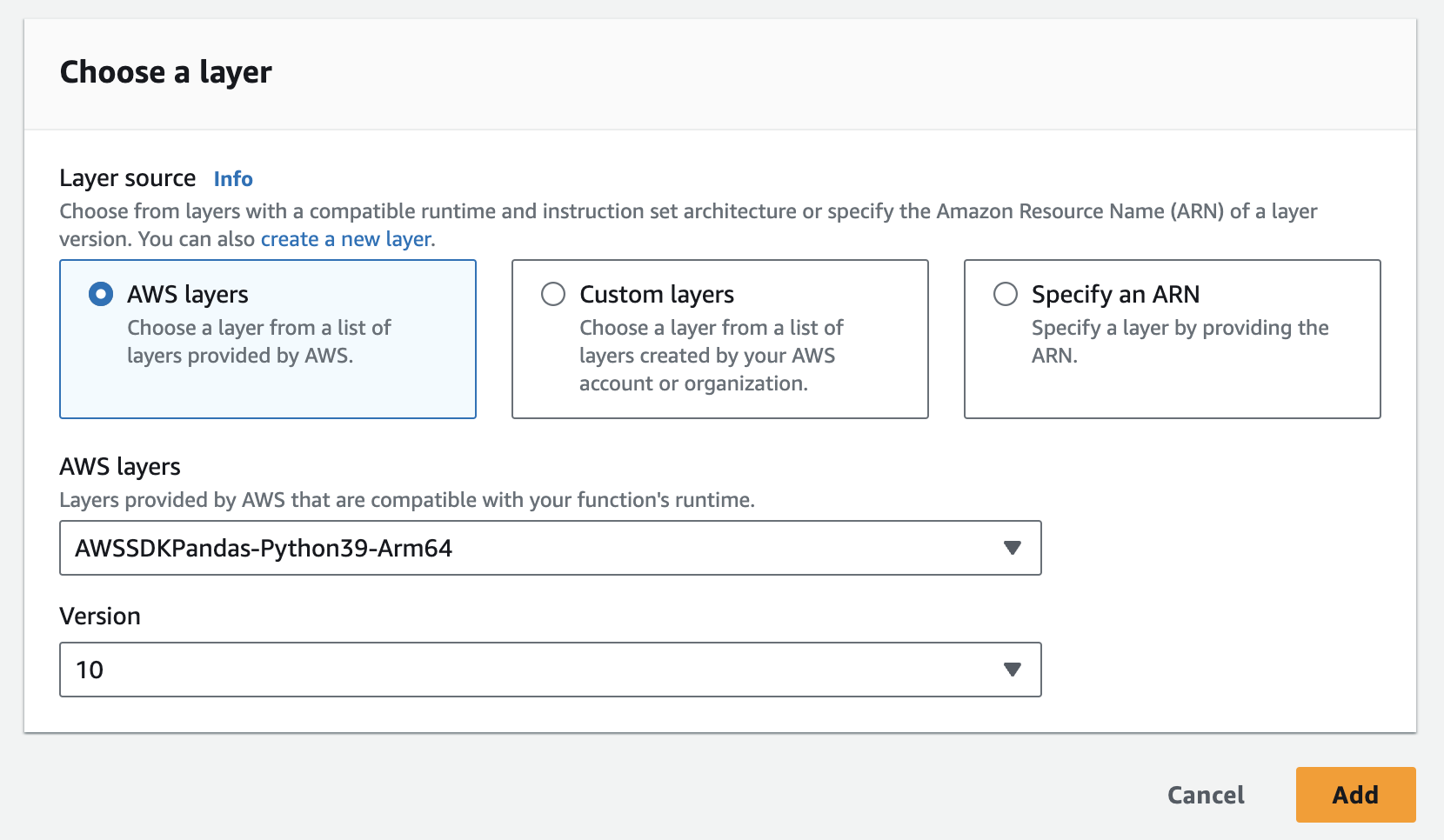 {height="" width=""} 아래에서 AWS의 pandas 레이어를 쉽게 추가할 수 있습니다.
{height="" width=""} 아래에서 AWS의 pandas 레이어를 쉽게 추가할 수 있습니다.
- 람다 함수에 인스턴스, API 키, API 시크릿을 환경 변수로 추가해야 합니다. 런타임 설정을 업데이트하여 타임아웃 시간 및 사용 메모리를 늘려야 할 수도 있습니다. 설정 업데이트를 위한 아래 스크린샷
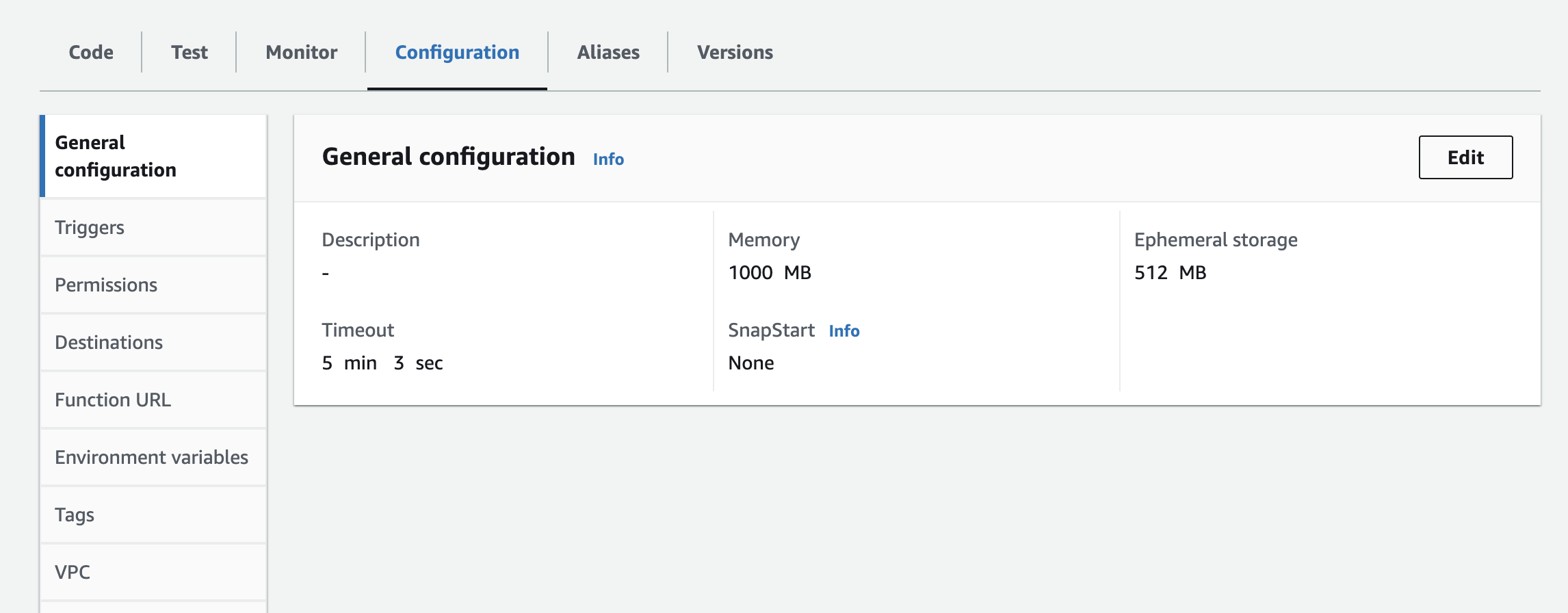
다음 단계
커넥터 기능이 작동하면 새로 고침 빈도를 조정하고, 대상 데이터베이스 또는 데이터 웨어하우스에서 튤립 테이블 정보를 보고, 추가 기능을 사용할 수 있습니다.
이 데이터 파이프라인의 구체적인 사용 사례: * 엔터프라이즈 수준의 분석 및 Tulip 데이터의 데이터 처리* 엔터프라이즈 시스템을 통한 배치 자동화* 데이터 웨어하우스 및 데이터 레이크를 통한 컨텍스트화
추가 리소스
추가 지원 문의는여기에서 추가 지원 문의는 여기에서 *추가 지원 문의는 여기에서* 또한, 간소화된 Tulip 테이블 통합을 위한 조정 및 요청 양식을 제공했습니다. 여기에서 피드백 및 요청을 제공하세요.