
Usprawnij inżynierię danych Tulip dzięki integracji z Fivetran
Cel
Usprawnienie potoków inżynierii danych z Tulip umożliwia korzystanie z danych tabel Tulip w całym przedsiębiorstwie.
Konfiguracja
Do konfiguracji wymagane są następujące elementy: * Konto Fivetran (dostępna jest wersja bezpłatna) * AWS (lub inne konto w chmurze) * Baza danych lub hurtownia danych do odbierania danych z tabel Tulip * Wysoki poziom znajomości języka Python.
Jak to działa
Konfiguracja automatyzacji Fivetran obejmuje następujące kroki:
- Konfiguracja konta Fivetran
- Utwórz miejsce docelowe (np. Snowflake)
- Utworzenie funkcji Connector z funkcją AWS Lambda
- Utwórz funkcję AWS Lambda
- Sfinalizowanie funkcji Connector
- Przetestowanie konektora Fivetran i dostosowanie częstotliwości odświeżania
Fivetran używa funkcji lambda do automatycznego pobierania danych z tabel tulipanów zgodnie z harmonogramem i aktualizowania docelowych baz danych lub hurtowni danych. Dołączony przykład to prosta funkcja, która ponownie zapisuje tabelę z nowymi, odświeżonymi danymi. Dodatkowe funkcje można dodać w celu ulepszenia wyzwalaczy opartych na zdarzeniach.
Instrukcje konfiguracji
Konfiguracja konta Fivetran
Najpierw należy skonfigurować konto Fivetran. Oferują oni darmową wersję z ograniczoną liczbą odświeżeń miesięcznie
Konfiguracja miejsca docelowego
Następnie kliknij Destinations i utwórz pierwsze miejsce docelowe. Jest to zasadniczo baza danych lub hurtownia danych, która będzie odbierać dane z tabel Tulip.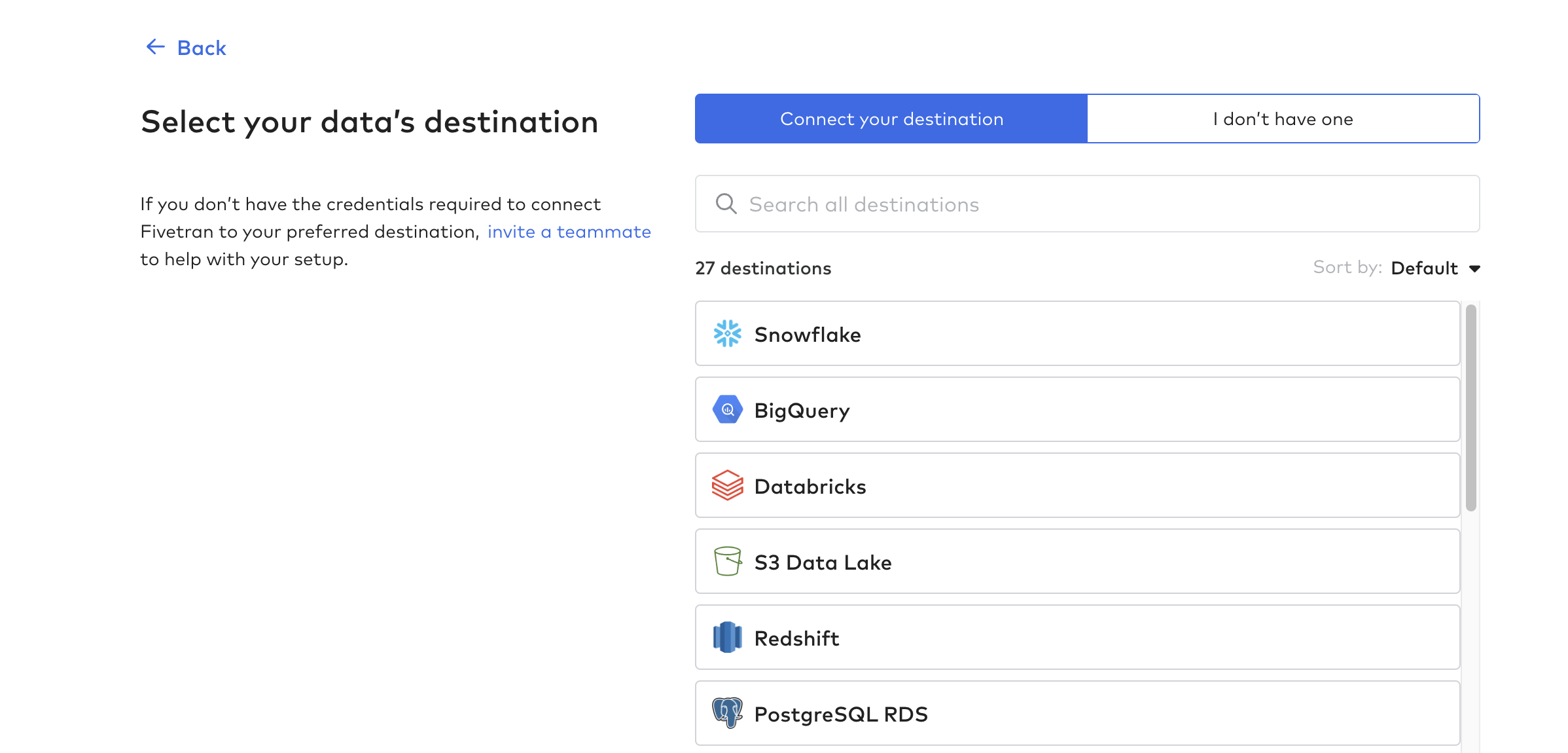
Utwórz funkcję łącznika
Następnie utwórz funkcję łącznika; jest to proces automatyzacji potoku danych z Tulip. Możesz użyć dowolnej funkcji w chmurze, takiej jak AWS Lambda, Azure Functions lub GCP Cloud Functions. W tym przykładzie użyjemy AWS Lambda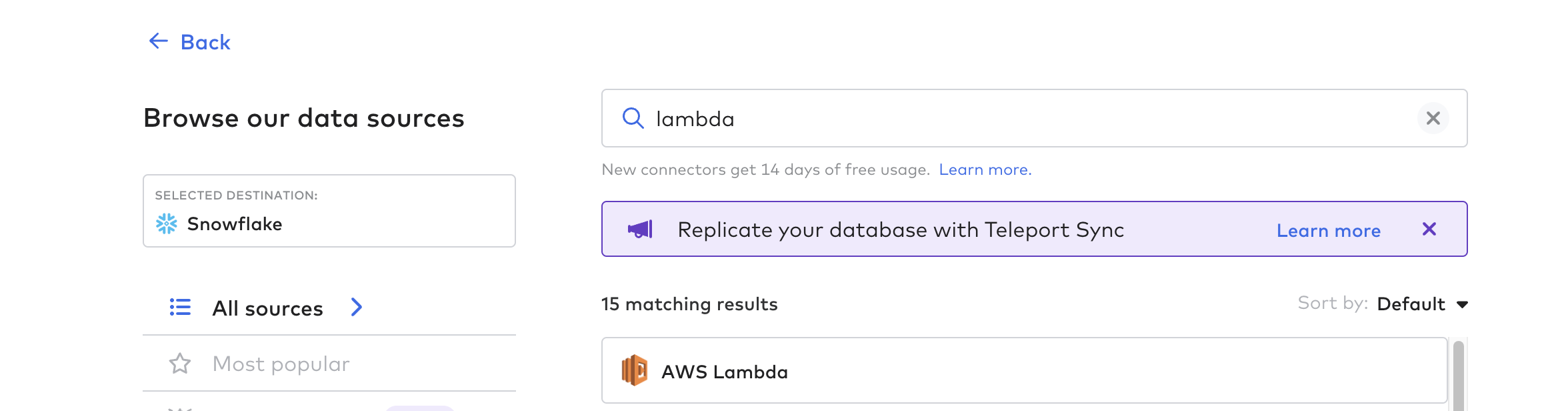
Postępuj zgodnie z instrukcjami in-Fivetran, aby utworzyć funkcję Lambda na AWS z odpowiednimi rolami i uprawnieniamiZobacz link do szablonu funkcji lambda jako punkt wyjściaPoniżej znajduje się kilka pomocnych wskazówek:
- Będziesz musiał utworzyć dwie warstwy: jedną dla biblioteki tulip, drugą dla biblioteki pandas.
- Interfejs API społeczności Tulip można wyświetlić tutaj
- Plik zip można pobrać alternatywnie tutaj (został on przygotowany do dodania do warstwy).
- Możesz łatwo dodać warstwę pandas w AWS poniżej
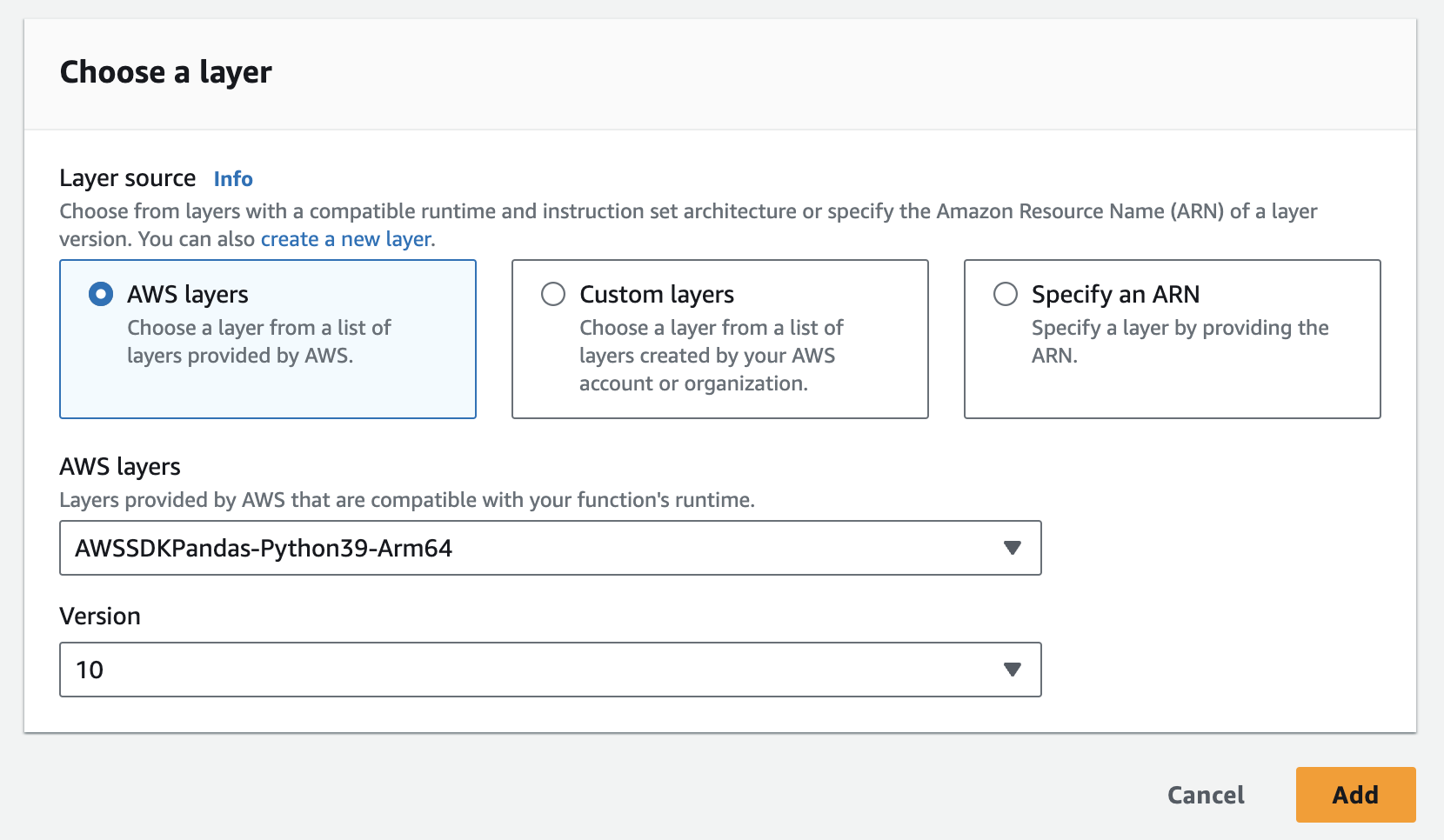
- Będziesz musiał dodać instancję, klucz API i sekret API jako zmienne środowiskowe do funkcji lambda. Może być konieczne zaktualizowanie ustawień uruchamiania, aby zwiększyć czas oczekiwania i używaną pamięć. Poniższy zrzut ekranu przedstawia aktualizację konfiguracji
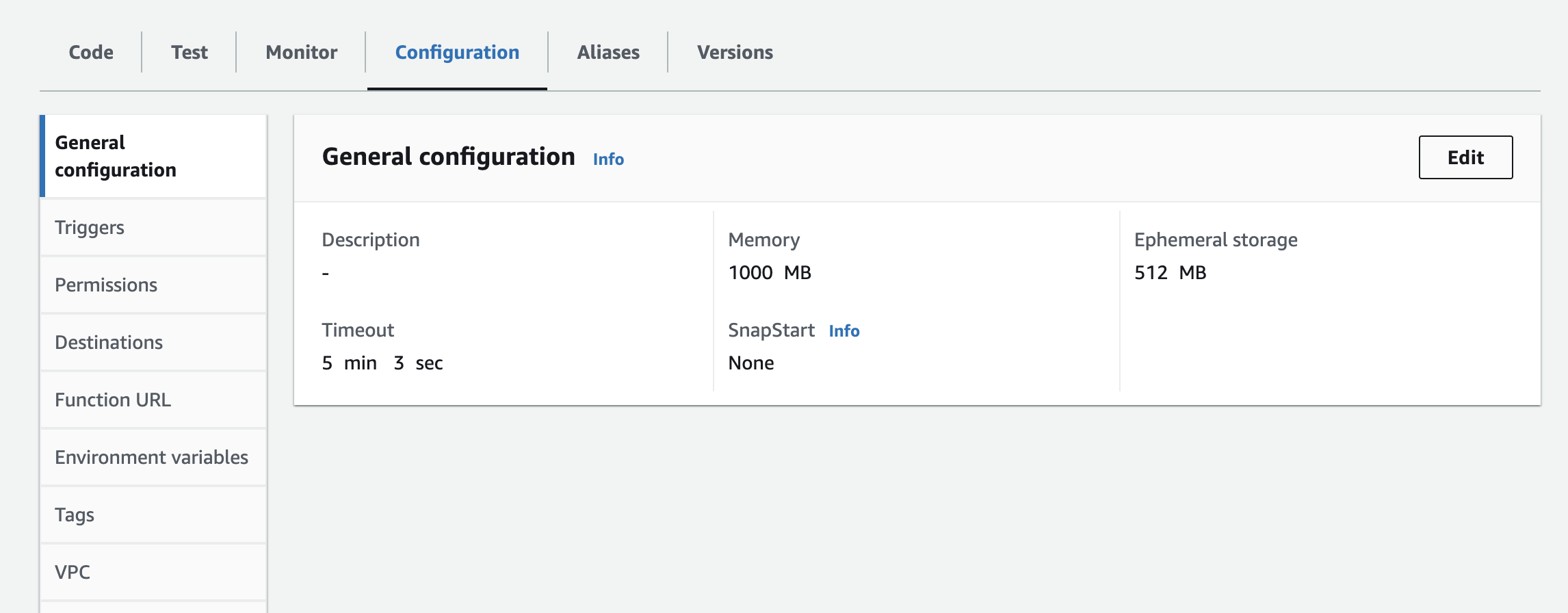
Następne kroki
Po uruchomieniu funkcji konektora można dostosować częstotliwość odświeżania, wyświetlić informacje o tabelach Tulip w docelowej bazie danych lub hurtowni danych i uzyskać dodatkowe funkcje
Niektóre konkretne przypadki użycia tego potoku danych: * Analityka na poziomie przedsiębiorstwa i przetwarzanie danych Tulip * Automatyzacja wsadowa z systemami korporacyjnymi * Kontekstualizacja z hurtowniami danych i jeziorami danych
Dodatkowe zasoby
Skontaktuj się z firmą Fivetran, aby uzyskaćdodatkowe wsparcie tutajSkontaktuj sięz firmą Fivetran, aby uzyskać dodatkowe wsparcie tutaj * Dodatkowo udostępniono formularz do wprowadzania korekt i żądań uproszczonej integracji tabel Tulip. Prześlij opinię i prośbę tutaj