
A Tulip adatszerkesztés egyszerűsítése a Fivetran integrációval
Cél
Az adattervezési csővezetékek racionalizálása a Tulip segítségével lehetővé teszi a Tulip táblák adatainak használatát az egész vállalaton belül.
Beállítás
A beállításhoz a következőkre van szükség: * Fivetran-fiók (ingyenes verzió elérhető) * AWS (vagy más felhőfiók) * Adatbázis vagy adattárház a Tulip Tables-adatok fogadásához * Python magas szintű ismerete.
Hogyan működik
Ez a fivetran automatizálási beállítás a következő lépésekkel működik:
- Fivetran-fiók beállítása
- Célállomás létrehozása (pl. Snowflake)
- Connector funkció létrehozása AWS Lambda funkcióval
- AWS Lambda-funkció létrehozása
- A csatlakozófüggvény véglegesítése
- A Fivetran-csatlakozó tesztelése és a frissítési gyakoriság beállítása
A Fivetran a lambda függvényt használja a tulipán táblák adatainak ütemezett rendszerességgel történő automatikus lehívására és a céladatbázisok vagy adattárházak frissítésére. A mellékelt példa egy egyszerű függvény, amely új, frissített adatokkal írja újra a táblázatot. További funkciókat lehet hozzáadni a továbbfejlesztett eseményalapú triggerekhez.
Beállítási utasítások
Fivetran fiók beállítása
Először is be kell állítania egy Fivetran-fiókot. Ingyenes verziót kínálnak korlátozott számú havi frissítéssel.
Célállomás beállítása
Ezután kattintson az Úti célok menüpontra, és hozza létre az első úti célját. Ez lényegében az az adatbázis vagy adattárház, amely megkapja a Tulip táblák adatait.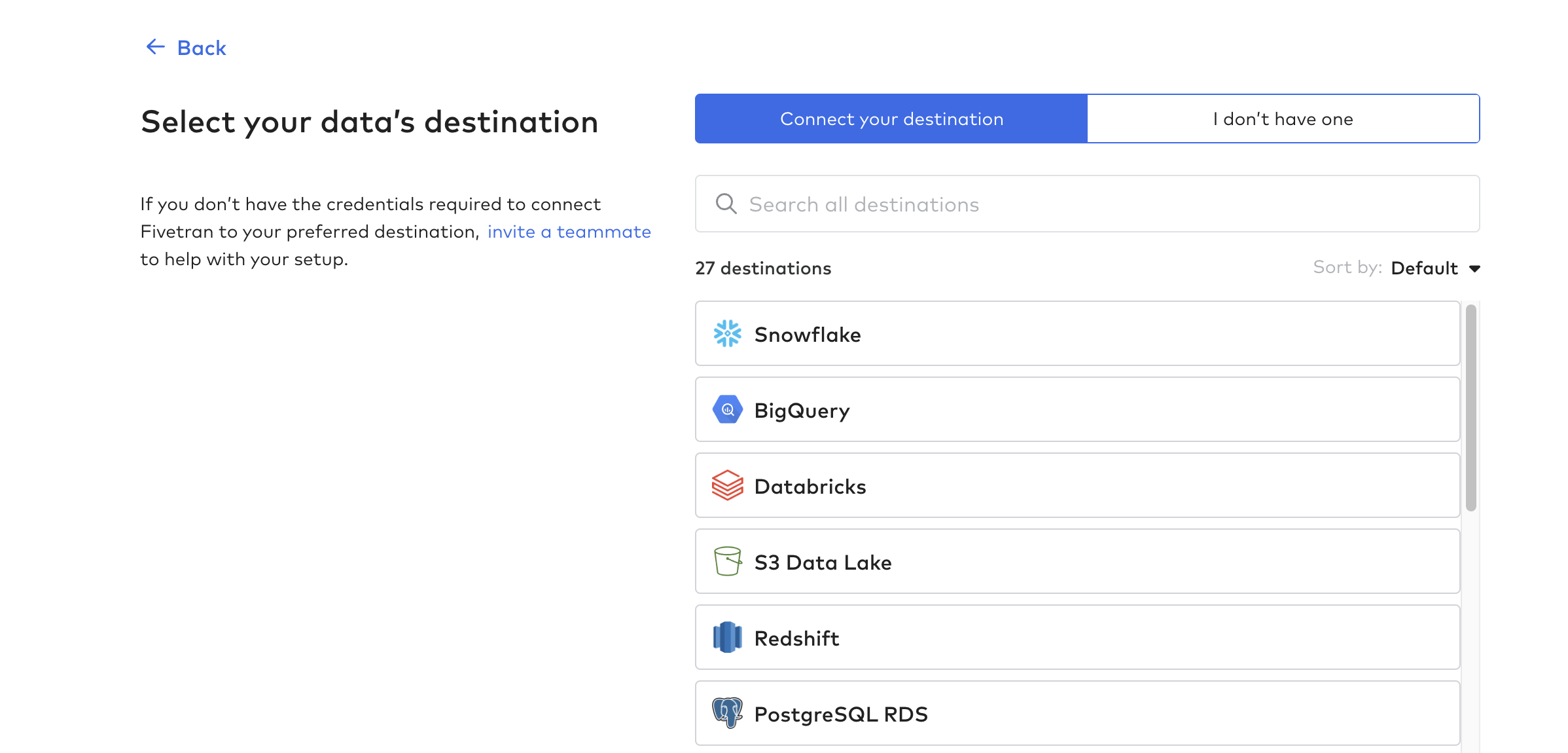
Csatlakozó funkció létrehozása
Ezután hozza létre a csatlakozófüggvényt; ez a folyamat a Tulipból származó adatvezetés automatizálására szolgál. Használhat bármilyen felhőfüggvényt, például AWS Lambda, Azure Functions vagy GCP Cloud Functions. Ehhez a példához az AWS Lambda funkciót fogjuk használni.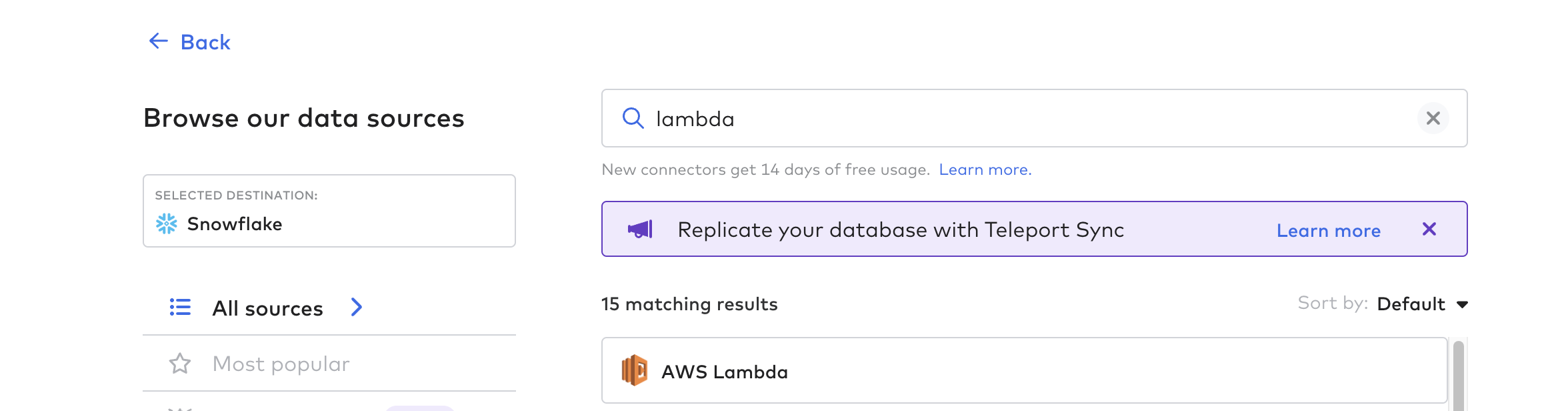
Kövesse az in-Fivetran utasításait egy Lambda-funkció létrehozásához az AWS-en a megfelelő szerepkörökkel és jogosultságokkalLásd a lambda-funkció sablon linkjét kiindulási pontkéntAz alábbiakban néhány hasznos tippet talál:
- Két réteget kell létrehoznia: az egyik a tulip könyvtárhoz, a másik a pandas könyvtárhoz.
- A Tulip közösségi API-t itt tekintheti meg
- Alternatívaként letöltheti a zip fájlt innen (Ez már elő van készítve egy réteghez való hozzáadásra
- A pandas réteget könnyen hozzáadhatja az AWS-ben az alábbiakban
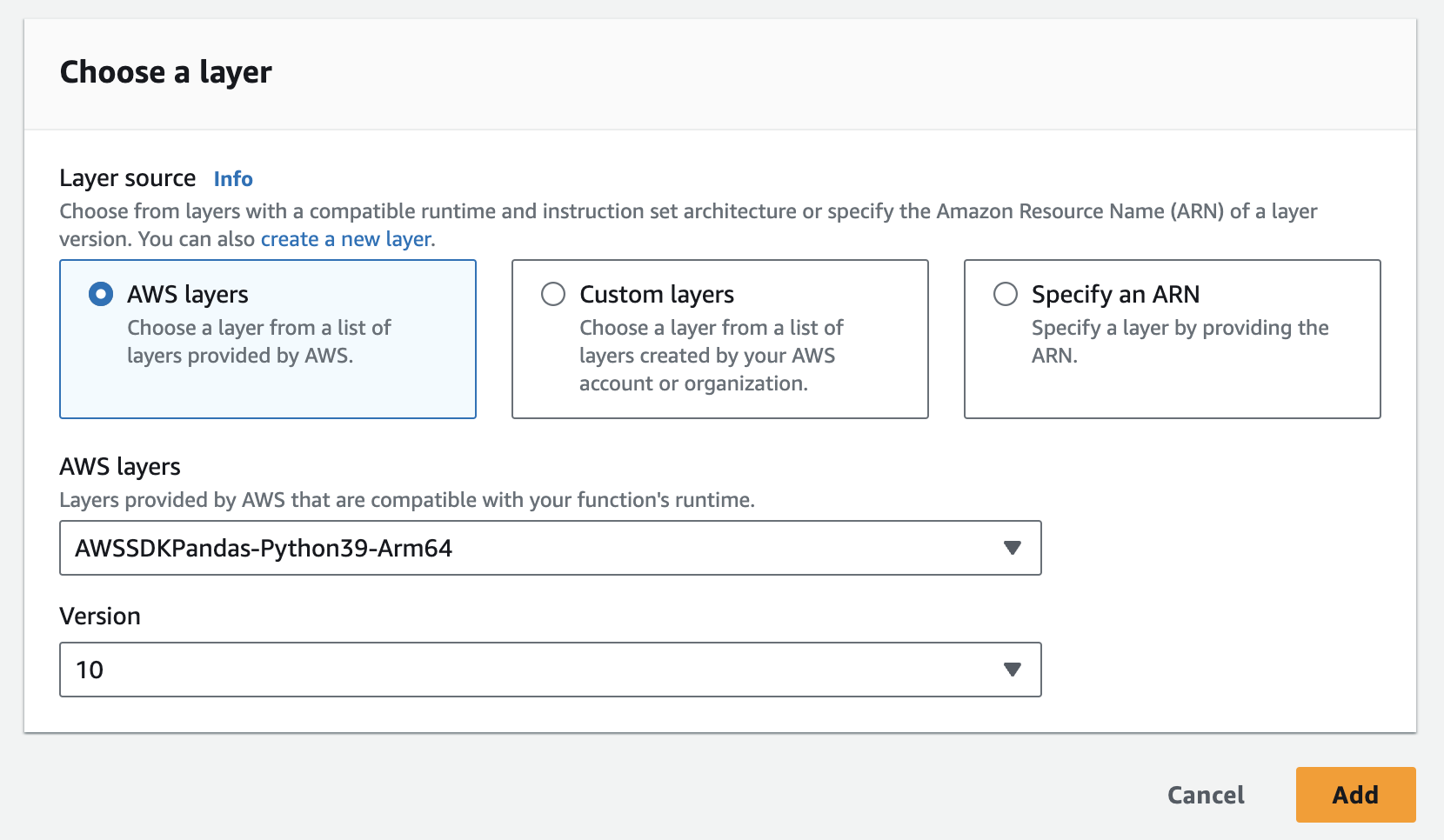
- A lambda függvényhez környezeti változóként hozzá kell adnod a példányt, az API kulcsot és az API titkot. Lehet, hogy frissítenie kell a futásidejű beállításokat, hogy növelje az időkorlátozási időt és a felhasznált memóriát. Az alábbi képernyőkép a konfiguráció frissítéséhez
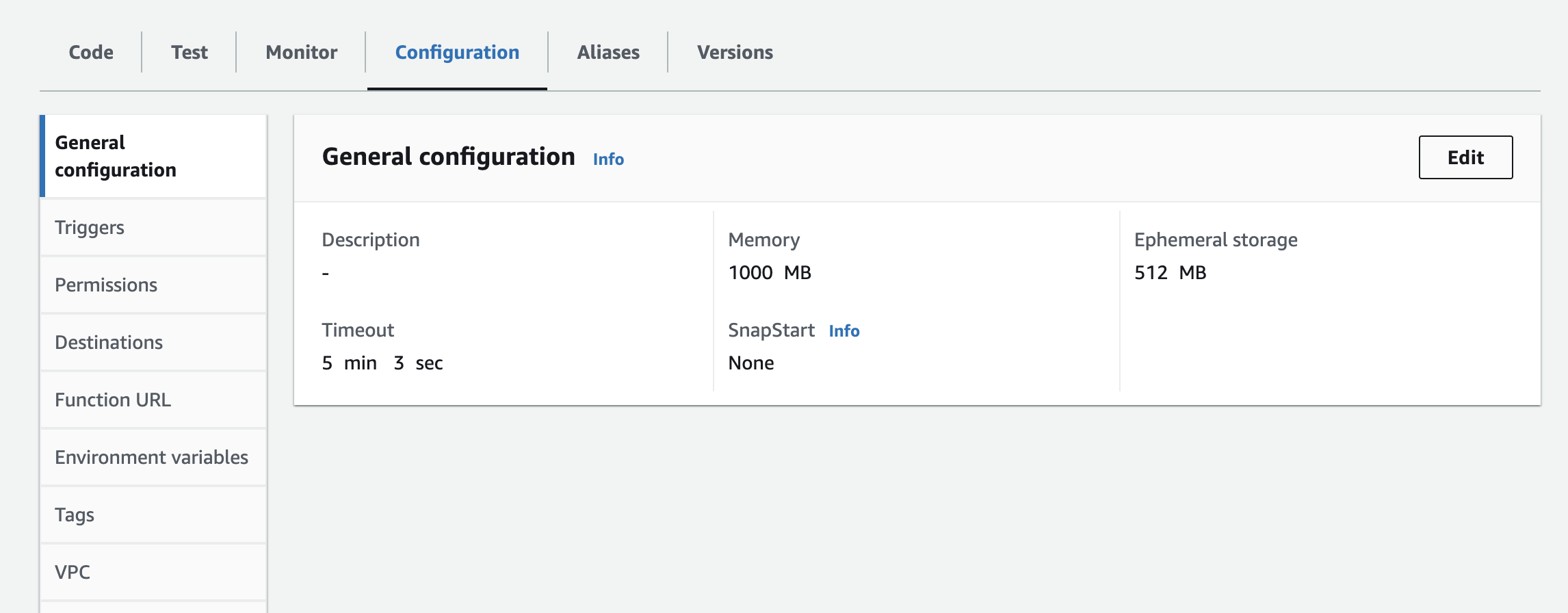
Következő lépések
Ha a csatlakozó funkció működik, beállíthatja a frissítési gyakoriságot, megtekintheti a Tulip táblák információit a céladatbázisban vagy az adattárházban, és további további funkciókat biztosíthat
Néhány konkrét felhasználási eset erre az adatvezetékre: * Vállalati szintű analitika és a Tulip adatok feldolgozása * Kötegautomatizálás vállalati rendszerekkel * Kontextualizálás adattárházakkal és adattavakkal.
További erőforrások
További támogatásért forduljon a Fivetranhoz ittKérjea Fivetran további támogatását itt * Ezenkívül egy űrlapot is biztosítottak az egyszerűsített Tulip-táblák integrációjához szükséges módosítások és kérések elvégzéséhez. Adjon visszajelzést és kérést itt