
Rationaliser l'ingénierie des données de Tulip grâce à l'intégration de Fivetran
Objectif
La rationalisation des pipelines d'ingénierie de données avec Tulip permet l'utilisation des données des tables Tulip dans l'ensemble de l'entreprise.
Configuration
L'installation nécessite les éléments suivants : * Compte Fivetran (la version gratuite est disponible) * Compte AWS (ou autre compte cloud) * Base de données ou entrepôt de données pour recevoir les données des tables Tulip * Connaissance de haut niveau de Python
Comment cela fonctionne-t-il ?
Cette configuration d'automatisation Fivetran fonctionne selon les étapes suivantes :
- Créer un compte Fivetran
- Créer une destination (par exemple, Snowflake)
- Création de la fonction Connecteur avec la fonction AWS Lambda
- Création de la fonction AWS Lambda
- Finalisation de la fonction de connecteur
- Tester le connecteur Fivetran et ajuster la fréquence de rafraîchissement
Fivetran utilise la fonction lambda pour récupérer automatiquement les données des tables tulipes sur une base programmée et mettre à jour les bases de données de destination ou les entrepôts de données. L'exemple fourni est une fonction simple qui réécrit la table avec de nouvelles données actualisées. Des fonctionnalités supplémentaires peuvent être ajoutées pour améliorer les déclencheurs basés sur les événements.
Instructions de configuration
Création d'un compte Fivetran
Vous devez tout d'abord créer un compte Fivetran. Fivetran propose une version gratuite avec un nombre limité de rafraîchissements par mois.
Création d'une destination
Cliquez ensuite sur Destinations et créez votre première destination. Il s'agit essentiellement de la base de données ou de l'entrepôt de données qui recevra les données des tables Tulip.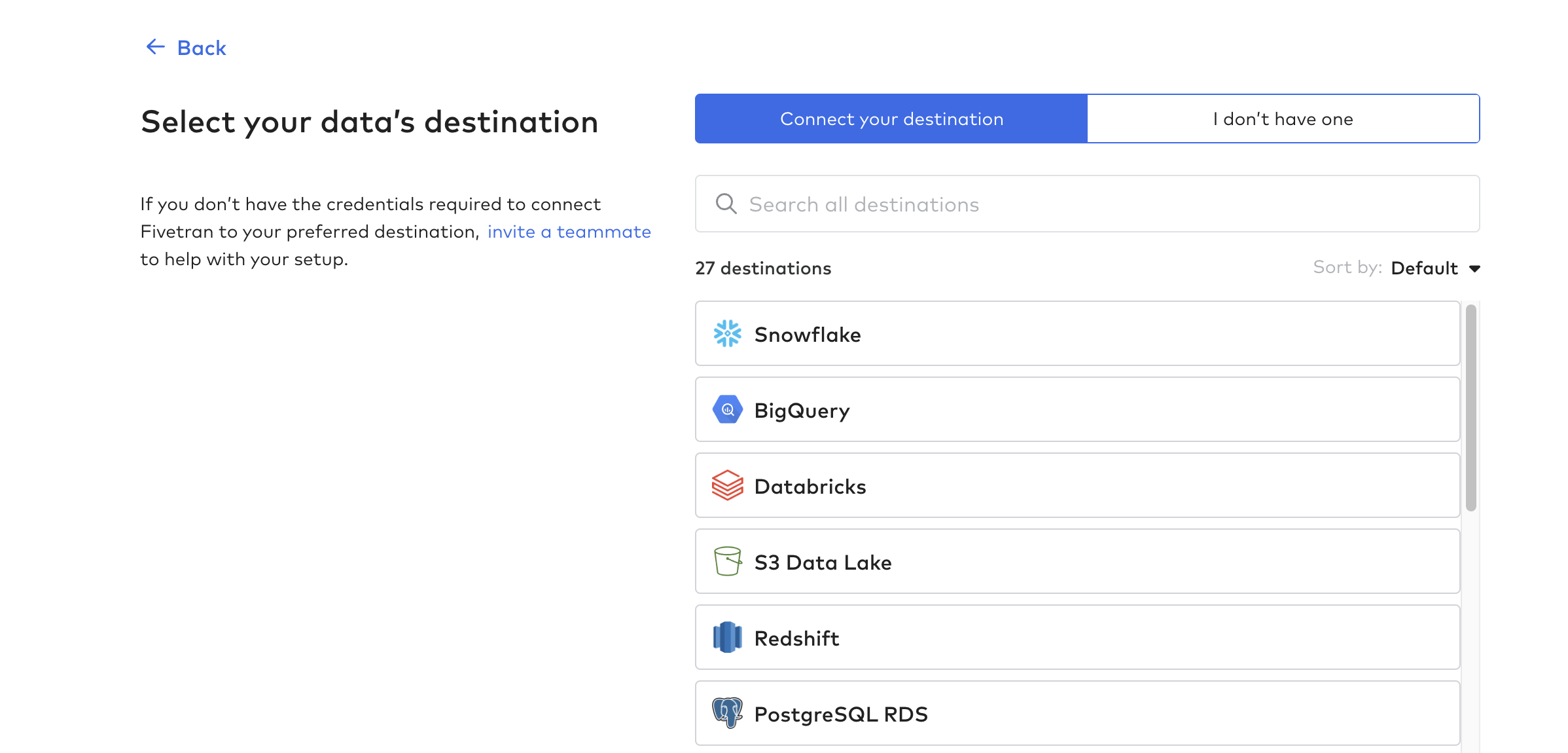
Créer une fonction de connexion
Ensuite, créez la fonction de connecteur ; c'est le processus d'automatisation du pipeline de données de Tulip. Vous pouvez utiliser n'importe quelle fonction cloud telle que AWS Lambda, Azure Functions, ou GCP Cloud Functions. Pour cet exemple, nous utiliserons AWS Lambda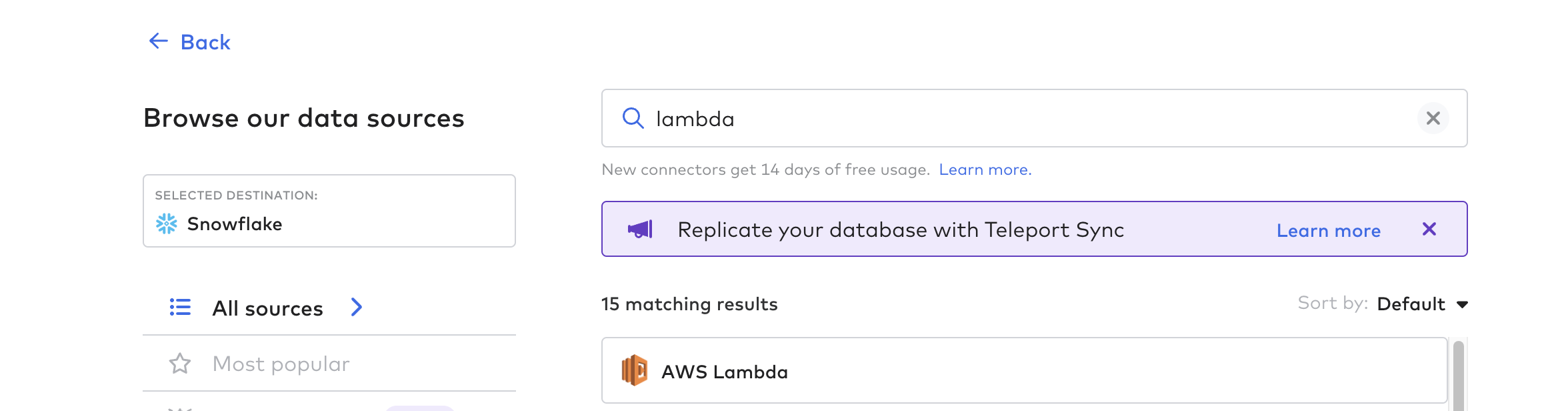
Suivez les instructions in-Fivetran pour créer une fonction Lambda sur AWS avec les rôles et autorisations appropriésVoir le lien pour le modèle de fonction Lambda comme point de départVoici quelques conseils utiles :
- Vous devrez créer deux couches : l'une pour la bibliothèque tulip ; l'autre pour la bibliothèque pandas.
- Vous pouvez consulter l'API de la communauté Tulip ici
- Vous pouvez télécharger le fichier zip ici (il a été préparé pour être ajouté à un calque).
- Vous pouvez facilement ajouter la couche pandas dans AWS ci-dessous
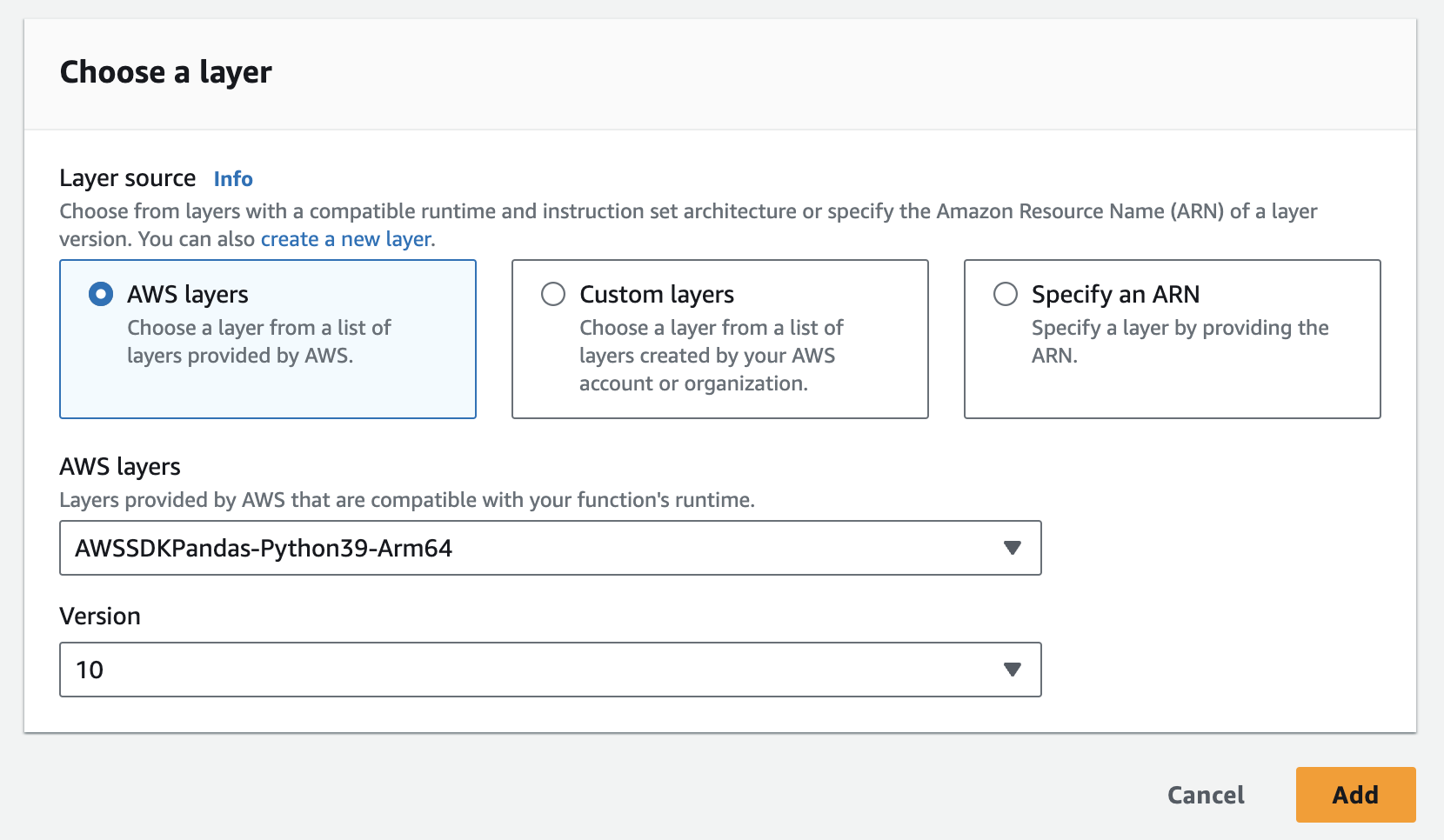
- Vous devrez ajouter l'instance, la clé API et le secret API comme variables d'environnement à la fonction lambda. Vous devrez peut-être mettre à jour les paramètres d'exécution pour augmenter le délai d'attente et la mémoire utilisée. Capture d'écran ci-dessous pour la mise à jour de la configuration
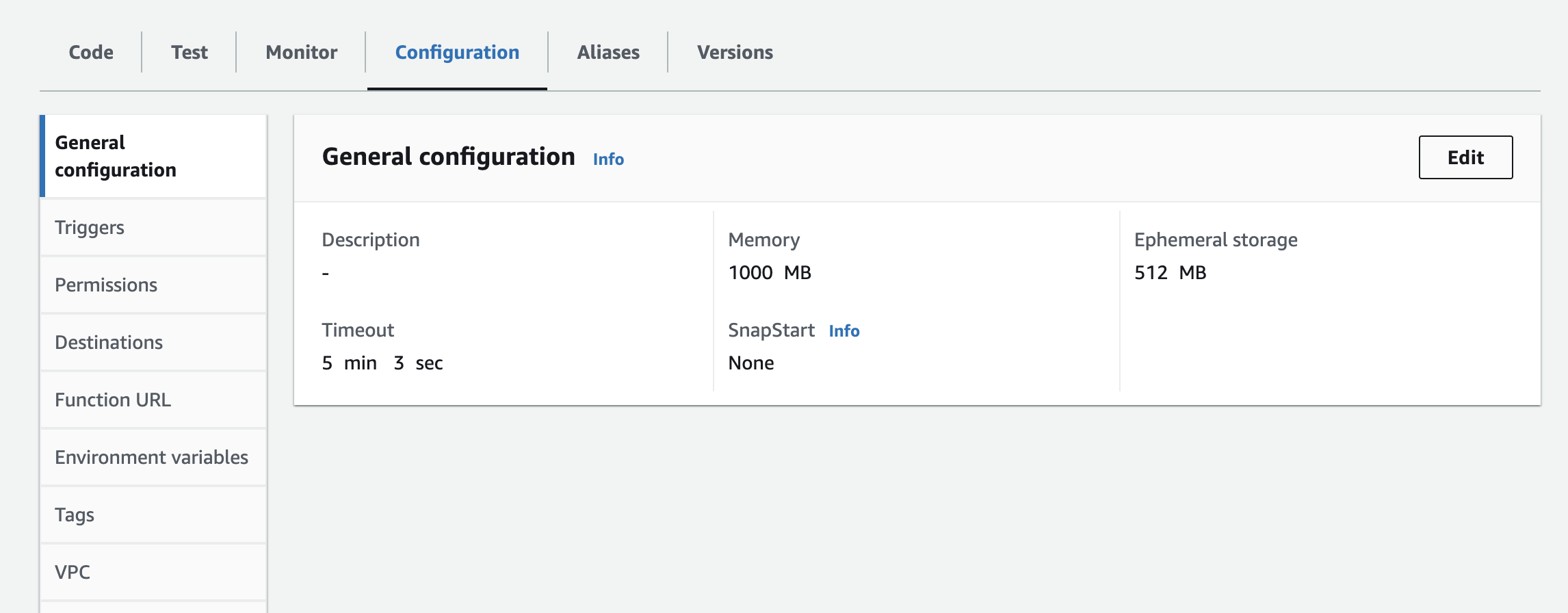
Étapes suivantes
Une fois que la fonction connecteur fonctionne, vous pouvez ajuster la fréquence de rafraîchissement, voir les informations des tables Tulip dans la base de données de destination ou dans l'entrepôt de données et d'autres fonctionnalités supplémentaires.
Quelques cas d'utilisation spécifiques pour ce pipeline de données : * Analyse au niveau de l'entreprise et traitement des données de Tulip * Automatisation des lots avec les systèmes d'entreprise * Contextualisation avec les entrepôts de données et les lacs de données
Ressources supplémentaires
Contactez Fivetran pour obtenir de l'aide supplémentaire ici ContactezFivetran pour obtenir de l'aide supplémentaire ici * De plus, Fivetran a mis à disposition un formulaire pour effectuer des ajustements et des demandes d'intégration simplifiée des tables Tulip. Fournissez vos commentaires et vos demandes ici