
Tulip から AWS S3 へのデータ取得を合理化し、より広範な分析と統合の機会を提供
目的
このガイドでは、Lambda関数を介してすべてのTulip Tablesデータをフェッチし、S3バケットに書き込む方法をステップバイステップで説明します。
これは、基本的なフェッチクエリを超えて、指定されたインスタンス内のすべてのテーブルを介して反復します。これは、毎週のETLジョブ(抽出、変換、ロード)に最適です。
ラムダ関数は、Event Bridge タイマーや API Gateway のような様々なリソースを介してトリガーすることができる。
アーキテクチャの例を以下に示す: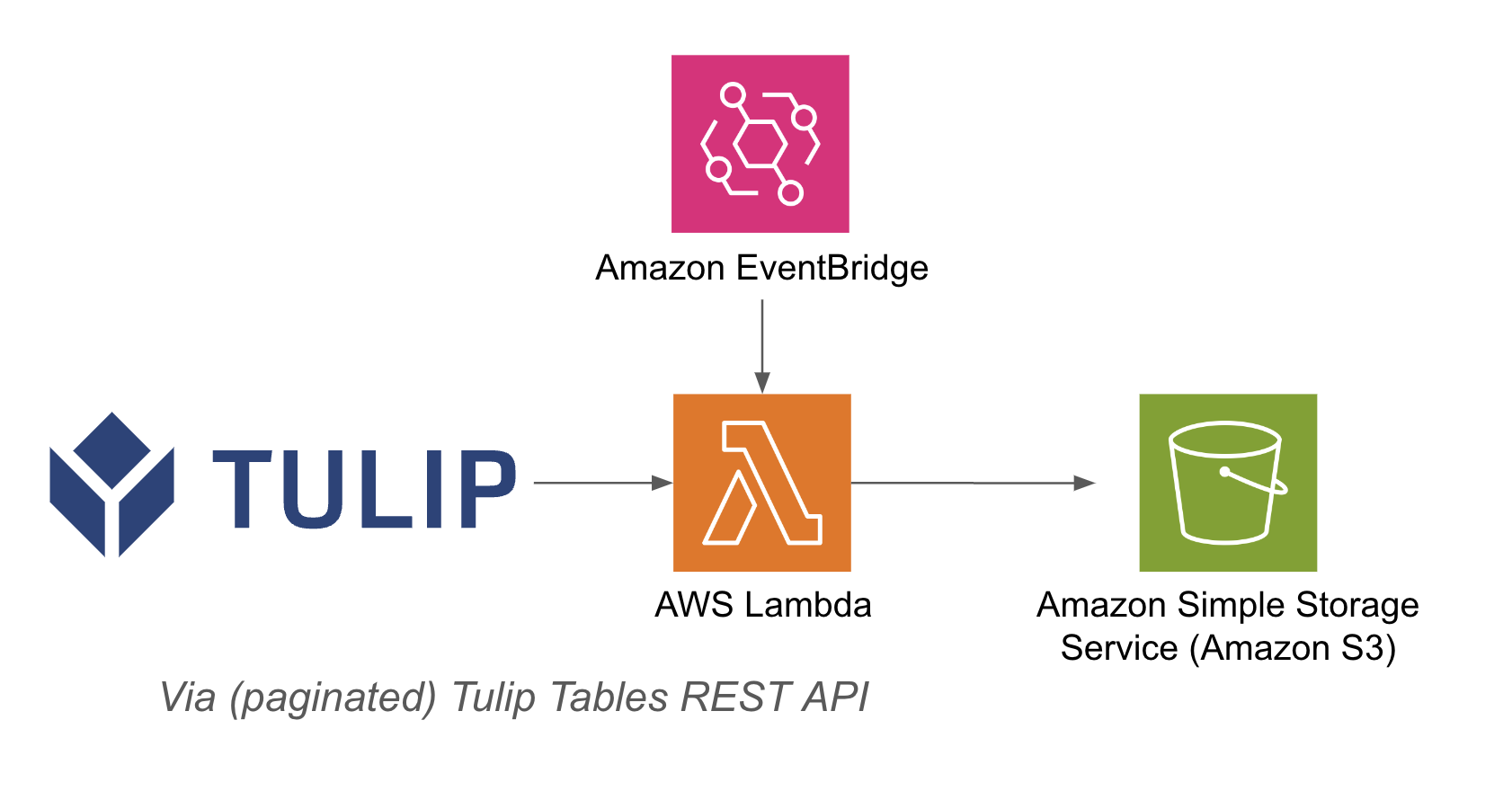
セットアップ
この統合例では、以下のものが必要です:
- Tulip Tables APIの使用 (アカウント設定でAPIキーとシークレットを取得)
- チューリップ・テーブル(テーブル固有IDの取得
1.関連するトリガー(API Gateway、Event Bridge Timerなど)でAWS Lambda関数を作成する。 3.以下の例でチューリップテーブルのデータを取得する。
# 一意なファイル名の現在のタイムスタンプを取得
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
バケット = os.getenv('bucket_name')
# 辞書を文字列に変換する関数
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+関数, headers=api_header) length = len(r. json()) df_id={table_id}/records?json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# 関数を作成
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row[ id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# DataFrameをCSVとしてS3に書き込むwr.s3.to_csv( df=df, path=path, index=False)print(f"{table}を{path}に書き込んだ")return f"{table}を{path}に書き込んだ"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# クエリテーブル functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('s3に書き込みました!')}.
## 使用例と次のステップ
lambda との統合が完了したら、sagemaker notebook、QuickSight、その他様々なツールを使って簡単にデータを分析することができます。
**1.不具合予知 -** 生産工程で発生する不具合を事前に特定し、初回出荷率を向上させます。
**2.品質コストの最適化-**顧客満足度に影響を与えずに製品設計を最適化する機会を特定する。
**3.生産エネルギーの最適化-** エネルギー消費を最適化するための生産レバーを特定する。
**4.納期とプランニングの予測と最適化-** 顧客の需要とリアルタイムのオーダースケジュールに基づいて生産スケジュールを最適化する**。**
**5.グローバルな機械/ラインのベンチマーキング -** 類似の機械や設備を正規化してベンチマーキングする。
**6.グローバル/リージョナルデジタルパフォーマンス管理 -** リアルタイムダッシュボードを作成するための統合データ