
概要
XMLベースのAPIを使用するためのヒントとトリックのガイド
チューリップコネクターは、さまざまな種類の外部データソースとやり取りするために使用できます。この記事では、XMLを使用して情報を交換するHTTP APIに焦点を当てます。このカテゴリにはSOAPAPIも含まれます。
TulipでXMLデータを送信する
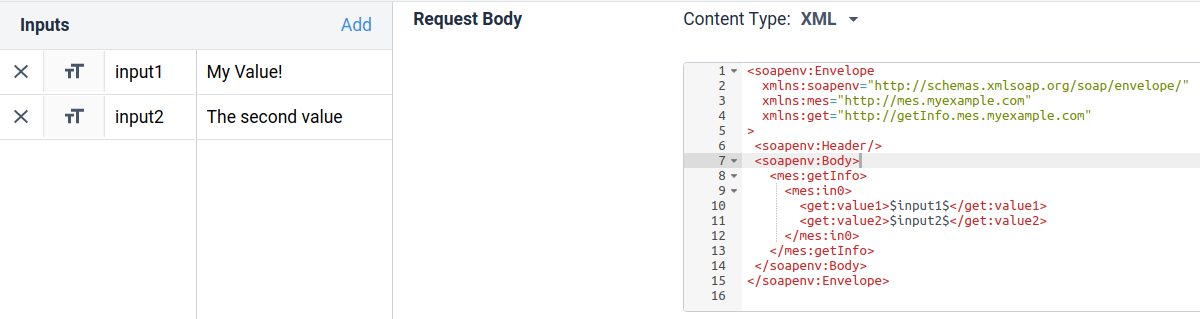
リクエストのボディにXMLコンテンツを送信するには、$value$記法を使ってパラメータを挿入する必要があることを示します。
例えば、リクエストボディフィールドに次のように記述します:
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:mes="http://mes.myexample.com"
xmlns:get="http://getInfo.mes.myexample.com"
input1$
input2$
と入力し、input1とinput2の値をConnector Functionへの入力とすると、input1とinput2の値がリクエストボディに代入されたリクエストが作成されます。
これは以下のTulip Connector Functionインターフェースに示されています:
TulipでのXMLデータの解析
簡単なAPIの例
XML APIからのシンプルなレスポンスの例から始めましょう。
xml version="1.0" encoding="UTF-8"?
日常イタリア語
Giada De Laurentiis
2005
30.00
ハリー・ポッター
J・K・ローリング
2005
29.99
XMLを学ぶ
エリック・T・レイ
2003
39.95
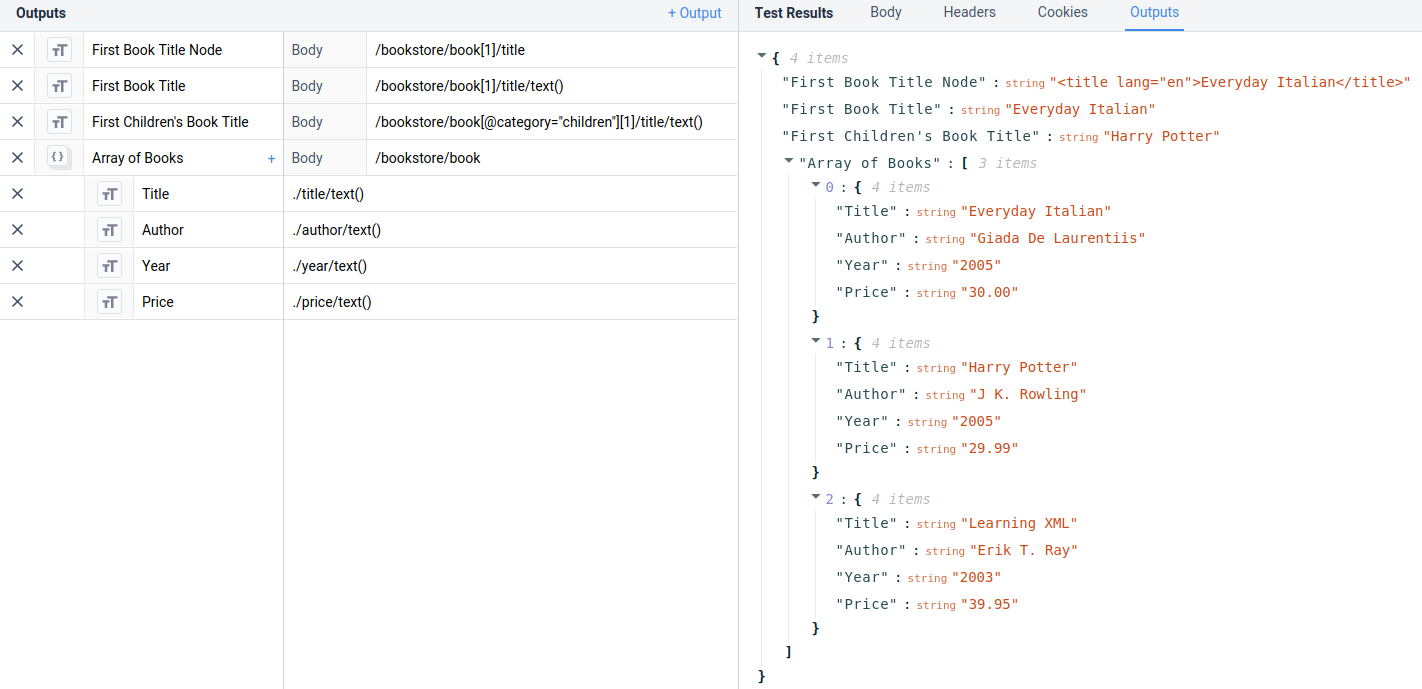
以下の例は、Tulip内の様々な情報にアクセスする方法を示しています。
のエクストラクタです:
/ブックストア/ブック[1]/タイトル
を返します:
<title lang="en">日常イタリア語</title>を返します。
glossary.JSON}}-queryが "0-indexed "であるのとは対照的に、XMLの配列は "1-indexed"、つまり最初の要素が "1 "の位置にあることに注意してください。
の抽出子:
/bookstore/book[1]/タイトル/テキスト()
を返します:
日常イタリア語
text()関数は、選択されたノードに含まれるテキスト値を抽出するために使用されることに注意してください。
の抽出子:
/bookstore/book[@category="children"][1]/タイトル/テキスト()
が返します:
ハリー・ポッター
セレクタによって、ノードのプロパティ内を検索できるようになったことに注意してください。
これらの例は、以下に示すようにTulipで直接使用できます:
SOAP API の例
では、SOAP APIの典型的な機能である名前空間を使用した、より複雑なケースを見てみましょう。
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
>
>
>
>
>
>
>
>
>
> 0
>
>
>
>
>
> 正常に取得された情報
>
>
>
>
>
>
>
> 私の操作
>
> なし
>
> 1234567-890
>
> B
>
>
>
>
>
>
>
> 品番
>
> 1234567-890
>
>
>
>
>
> 部品改訂
>
> B
>
>
>
>
>
> 部品説明
>
> 部品例
>
>
>
>
>
>
>
> ノーマル
>
>
>
>
>
>
>
>
>
>
>
>
> ```
>
>
>
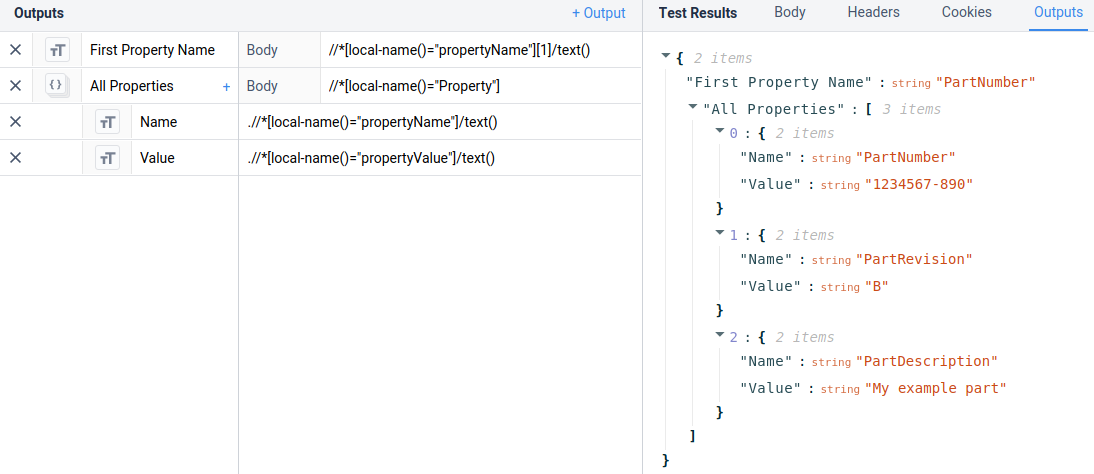
このレスポンスはXML名前空間を使用しており、複雑さを増しています。ほとんどの場合、`//*`および`.//*`演算子を使用したグローバル検索を使用すると、抽出が非常に簡単になります。
の抽出子:
`の抽出子: //*[local-name()="propertyName"][1]/text()`
を返します:
`部品番号`
XMLの配列は "1-indexed "であり、最初の要素が "1 "の位置にあることを意味し、json-queryが "0-indexed "であるのとは対照的であることに注意してください。
の抽出子:
`の抽出子: //*[local-name()="Property"]`
は以下を返します:
`<Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>PartNumber</propertyName> <propertyValue>1234567-890</propertyValue> </Property> <Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>PartRevision</propertyName> <propertyValue>B</propertyValue> </Property> <Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>PartDescription</propertyName> <propertyValue>My example part</propertyValue> </Property> </Property`
ここで、名前空間はこの結果に "降ろされる "ことに注意してください。したがって、サブクエリではグローバル名前空間を検索することになります。
オブジェクトの配列を抽出するには、前の例で示したグローバル検索を使用して配列を抽出し、次に以下のようなローカル検索エクストラクタを使用します:
`.//*[local-name()="propertyName"]/text()`
という形式のオブジェクトの配列を取得します:
`[ { "Name":"PartNumber"
"Value":"1234567-890" }, { "Name":"Name": "PartRevision"
"Value":"B"
}, { "Name":"PartDescription"
"値":"私の例の部分"
}
]`
これらの例は、以下のTulip Connectors Interfaceに示されています:
---
お探しのものは見つかりましたか?
また、[community.tulip.coに](https://community.tulip.co/?utm_source=intercom&utm_medium=article-link&utm_campaign=all)質問を投稿したり、他の人が同じような質問に直面していないか確認することもできます!