
To download the app, visit: Library
:::LandingAIのLandingLensを使用して、迅速な物体検出を行います。
目的
このウィジェットを使用すると、LandingLens内で作成したビジョン/機械学習モデルにアクセスできます。 このウィジェットを使えば、Tulipで写真を撮ってLandingLensのエンドポイントに送信し、AIモデルが見つけたオブジェクトの数を返すことができます。
セットアップ
このウィジェットを使用するには、https://landing.ai/{target="_blank"}のアカウントが必要です。 プラットフォームがどのように機能するかについての完全なドキュメントは、サポートドキュメント{target="_blank"}を参照してください。
- 新しいプロジェクトを作成する。
 {高さ="" 幅=""}。
{高さ="" 幅=""}。
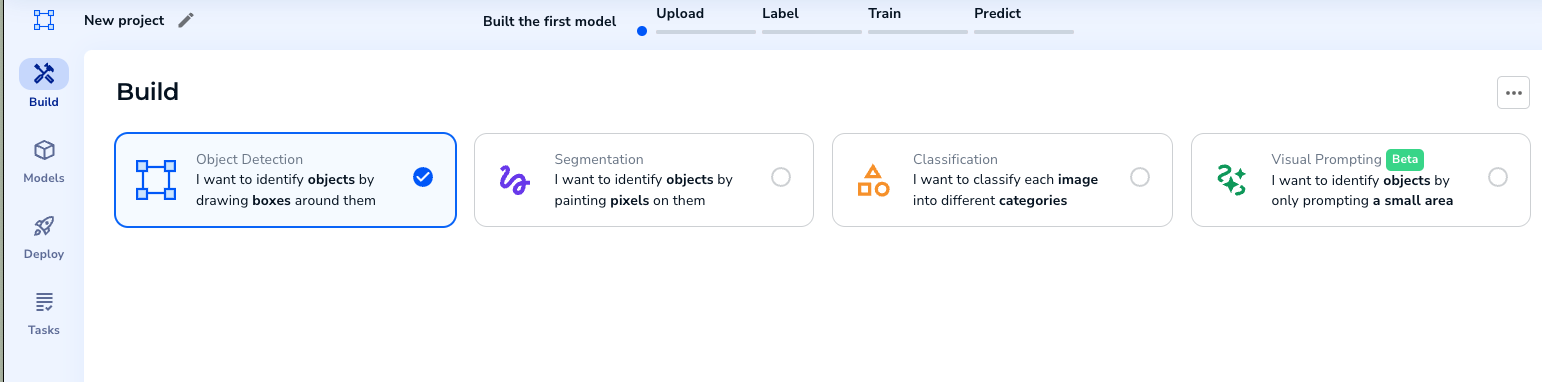 {height="" width=""} オブジェクト検出プロジェクトを選択します。
{height="" width=""} オブジェクト検出プロジェクトを選択します。- トレーニング画像をアップロードします。
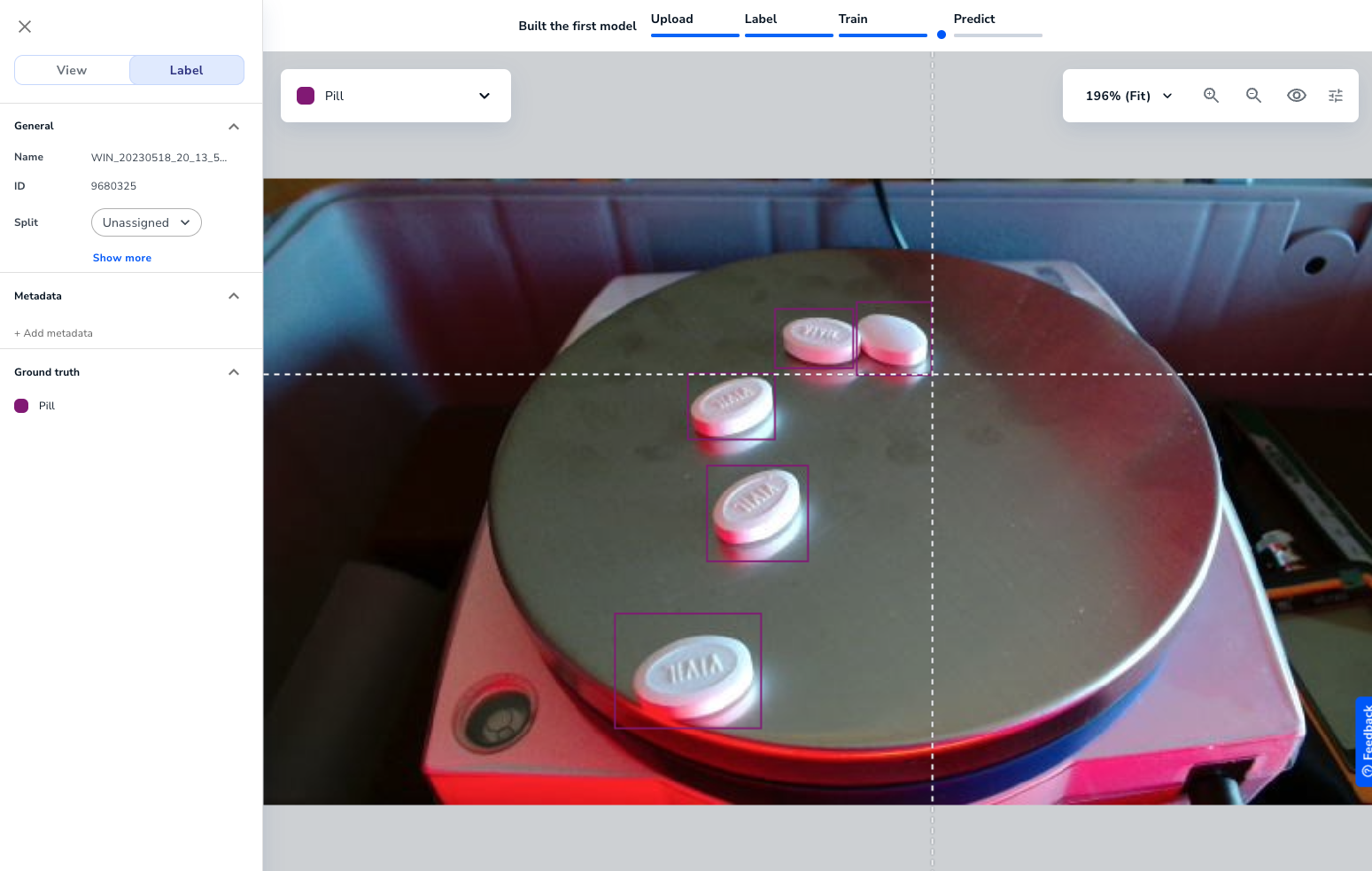 {height="" width=""} 画像にラベルを付けます。
{height="" width=""} 画像にラベルを付けます。
十分な画像がラベル付けされたら、モデルをトレーニングすることができます。
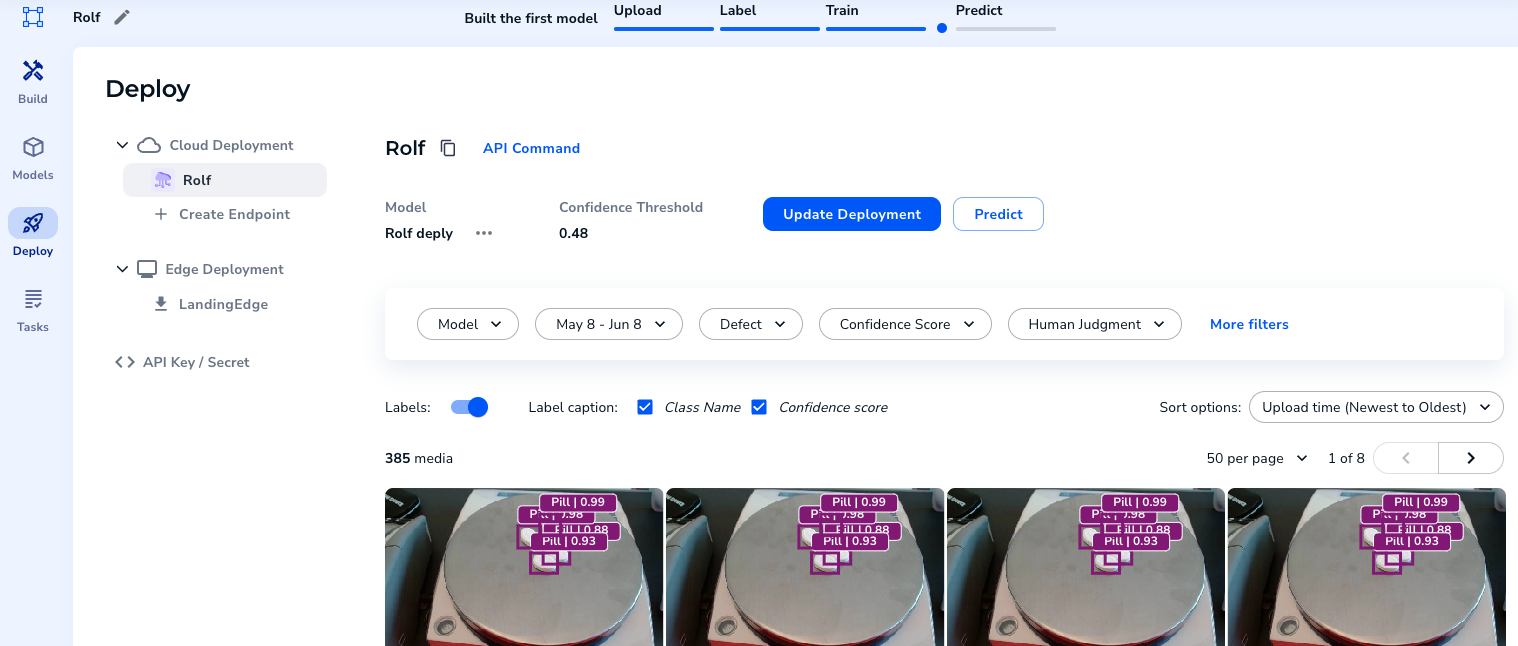 {height="" width=""}。
{height="" width=""}。- API Command "を選択すると、エンドポイントが表示される
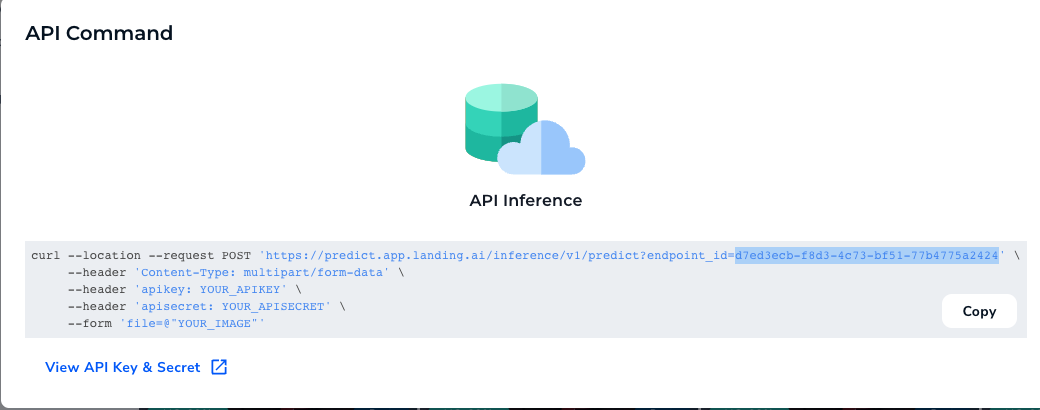 {height="" width=""}。
{height="" width=""}。
APIキーとシークレットをコピーする。
どのように動作するか
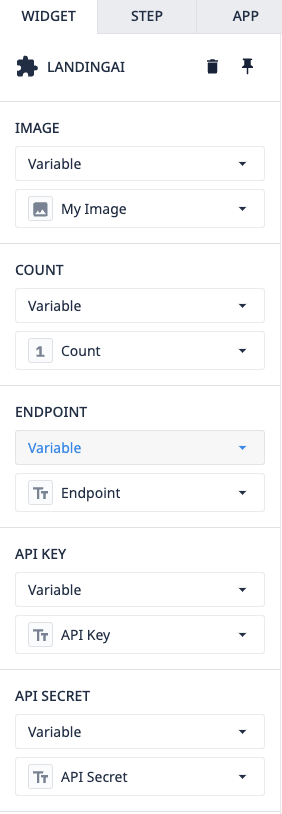
アプリケーションとウィジェット自体の使い方は簡単です。ウィジェットには、いくつかの小道具があらかじめ用意されています。
 {高さ="" 幅=""}
{高さ="" 幅=""}
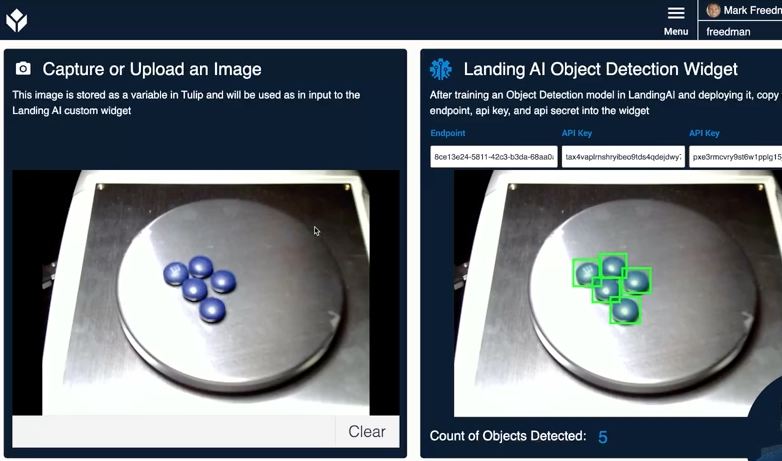
Image- これはTulipCountから LandingLens に送信される画像です - この変数はウィジェットによって書き込まれ、モデルによって検出されたオブジェクトの数を表しますEndpoint- これはプロジェクトからコピー/ペーストされますAPIKey & Secret- これらはデプロイされたプロジェクトからコピー/ペーストされます
これらのプロップがすべて入力されると、ウィジェットはLandingAIのAPIにリクエストを送信し、オブジェクトがハイライトされた画像を返します。
 {高さ="" 幅=""}
{高さ="" 幅=""}