

API ドキュメントに従って、HTTP Connector Functions でクエリパラメータを使用するための基礎を学んでください。
{API ドキュメントへのリンク}}。
クエリパラメータにより、Connector Function の結果を絞り込み、調整することができます。パラメータを使用して、並べ替え、フィルタリング、制限の設定、インデックスのオフセットなどを行います。この記事では Tulip Table API パラメータを使用していますが、他の API ではパラメータ要件が異なる場合があります。ドキュメントを確認して、正しい構文と仕様を使用していることを確認してください。
フィルタを使ったクエリ
フィルターは、興味のあるデータだけを抽出するのに非常に便利です。これらのフィルターは、構文が少し難しいことがあります。以下では、レコードの GET リクエストの例で、それぞれがどのように形成されるかを概説し、その後に完全な例を示します。
カスタムフィールドのフィールド名には、常に5桁の文字列識別子が先頭に付きます。これらは、GET allリクエストでフィールドの本当の名前を確認した後に最も簡単に見つけることができます。
- 例"field"="maytq_scrap_count"
引数値は多くの場合、単純明快である。テキスト値の場合は、必ず引用符で囲んでください。
- 例"arg":15
使用したい関数型に合わせる。
- 例"functionType": "greaterThan"
完全なリクエストは以下のようになる:
https://brian.tulip.co/api/v3/tables/W2HPvyCZrjMMHTiip/records?limit=100&sortBy=_sequenceNumber&sortDir=asc&filters=[{"field": "maytq_scrap_count", "arg": 15, "functionType": "greaterThan"}]&filterAggregator=any
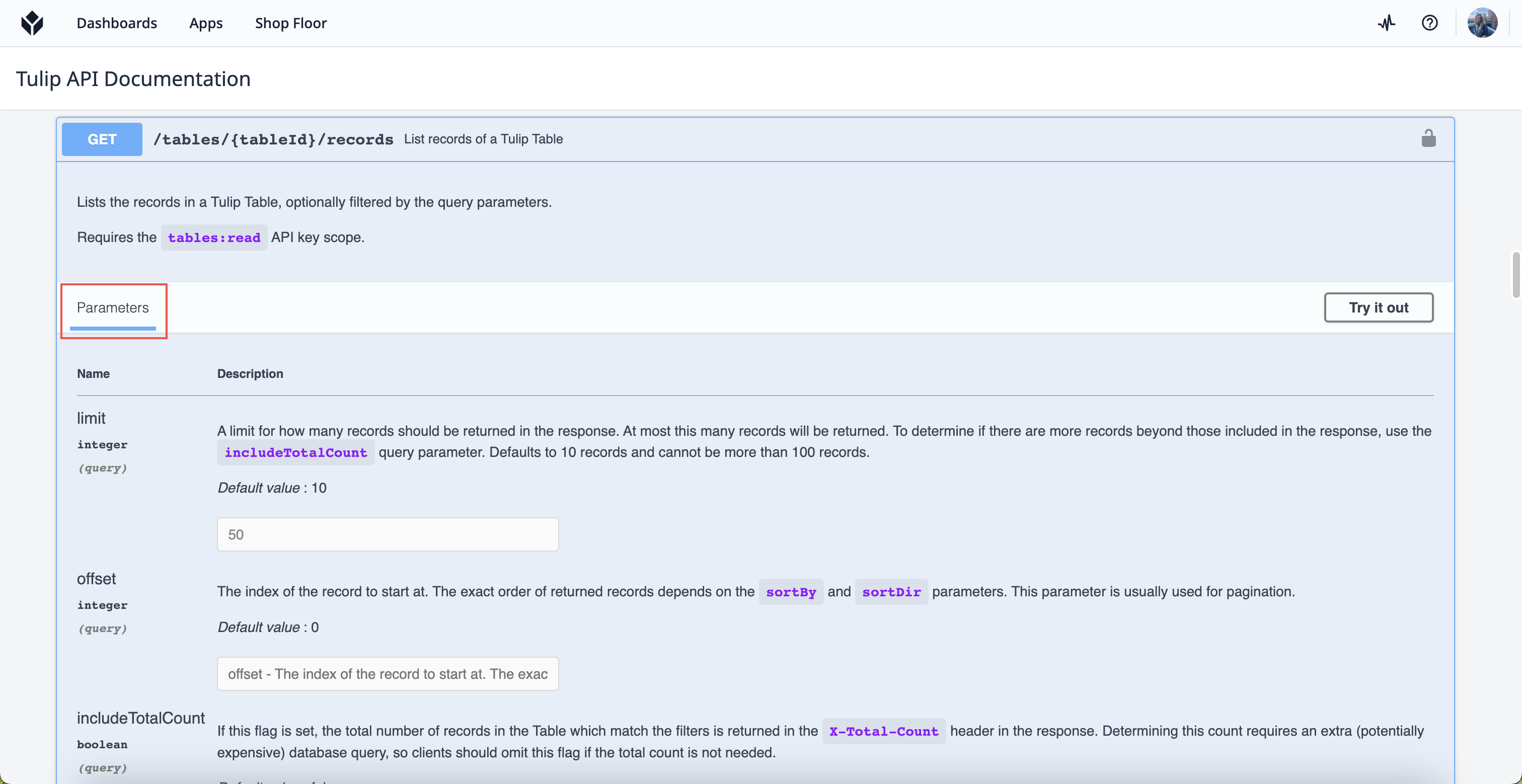
ドキュメントのクエリ・パラメータを見つける方法
リクエストで使用可能なクエリパラメータを見つけるには、APIドキュメントに移動します。Tulip Table APIを使用している場合は、次の場所でドキュメントを見つけることができます:your-instance.tulip.co/apiDocs.使用したいリクエストを選択し、Parametersタブまでスクロールダウンします。
 {height="" width=""} です。
{height="" width=""} です。
各メソッドにはパラメータが設定されていますが、すべてのリクエストにパラメータが設定されているわけではありません。事前にドキュメントで何が利用できるかを確認してください。
クエリパラメータの構文
パラメータ構文のクエリは、クエリストリングフォーマットに依存しています。この形式は、クエリ文字列自体を URL の一部として、指定されたパラメータに値を割り当てます。
Connector Function Editor で、Add Parameterをクリックして新しいクエリパラメータを作成します。
 {高さ="" 幅=""}。
{高さ="" 幅=""}。
クエリパラメータには、キーと 値の 2 つの部分があります。キーはパラメータの名前で、値は結果のパラメータを設定する情報です。
クエリパラメータの構文にはDot Notationを使用し、パラメータの正確な型を指定します。大文字と小文字が相手システムの API 標準と一致していることを確認してください。
コネクタ関数への共通パラメータの適用
コネクタ関数にパラメータを設定するには、まず API ドキュメントで使用するパラメータを特定します。パラメータはそれぞれ要件が異なるので、どのようなものかを確認しよう。
For continuity purposes, we’ll use the same request API Call in each of the examples below. This is the GET request that retrieves a list of records in a tulip Table via the Tulip Table API. Other APIs you use will have different specifications for parameters, be sure to look at the API documentation requirements.
リミット
リミットは、返される結果の上限を設定します。制限値にはデフォルト設定があるものもあるので、APIドキュメントをチェックして初期値を把握しておきましょう。
例コネクター関数の実行時に 70 レコードを超えないようにしたい。幸運なことに、このリクエストにおける制限のデフォルト値は 10 で、最高値は 100 です。クエリパラメータの構文は以下のようになります:
 {height="" width=""} のようにします。
{height="" width=""} のようにします。
フィルター
フィルターはパラメーターの与えられた情報に基づいて結果を分離し、絞り込みます。
フィルターには3つの部分があり、個々のパラメーターに記述する必要があります:
- フィールド - テーブルのカラム名。
- Function Type - 比較関数のタイプ。
- 引数 - 結果を比較する値
各フィルターは3つの部分を持ち、各フィルターはオブジェクトです。ドット記法を使用して各キーを記述し、パラメータのタイプ('filter')、フィルタ番号(0からn)、フィルタの部分('field'、'functionType'、'arg')を指定します。フィルタの3つの部分すべてにパラメータが必要です。
例コネクタ関数の結果が、関数の指定された入力値(consumable)に等しい特定のフィールド(eubmc_value)の値のみを表示するようにしたい。これは関数のパラメータの最初のフィルタなので、フィルタ番号は 0 です。つまり、このフィルタのすべてのキーは 'filter.0' で始まります。このフィルターの構文は以下のようになります:
 {height="" width=""} となります。
{height="" width=""} となります。
ソート
結果の並べ替えは、パラメータの情報に基づいてビューに優先順位を付けます。ソートされた結果は、集計に含まれるものを決定します。複数のソート関数を使用できますが、オプションの順序によってソートの優先順位が決まります。
ソート関数には2つの部分があります:
- sortBy - 結果を並べ替えたいフィールド。
- sortDir - 昇順(asc)または降順(desc)のソート方向。
各ソート関数には3つの部分があります。ドット記法を使ってそれぞれのキーを記述し、パラメータの種類('sortOptions')、ソート番号(0からn)、ソートの引数('sortBy'または'sortDir')を指定します。ソート関数が動作するためには、3つの部分すべてにパラメータが必要です。
例コネクタ関数の結果を、最新の更新フィールドで昇順にソートしたい。これは最初のソート関数なので、ソート番号は0です。これは、このソートのキーが両方とも'sortOptions.0'で始まることを意味します。sortByキーには、更新されたフィールドをソートするためにAPIドキュメントから派生した特別な値('_updatedAt')を指定します。これらのパラメータの構文は以下のようになります:
 {height="" width=""}のようになります。
{height="" width=""}のようになります。
オフセット
Offsetsは、返される結果のインデックスを決定します。このパラメータはページネーションに使用され、ソートパラメータで決定されるレコードの順序には使用されません。パラメータの値は 0 以上の整数でなければなりません。
例5位以降のレコードだけを表示したい。クエリーパラメーターの構文は以下のようになります:
 {height="" width=""} のようにします。
{height="" width=""} のようにします。
フィルタアグリゲータ
フィルター・アグリゲーターは、パラメーター内のフィルターをどのように組み合わせるかを決定します。any'と'all'の2つの値から選ぶことができます。値'all'は、レコードが結果に含まれるために、すべてのフィルタがレコードを持っている必要があることを意味します。any'の値は、少なくとも1つのフィルターがレコードにマッチしなければ結果に含まれないことを意味します。パラメータを設定するかどうかにかかわらず、デフォルト値は 'all' です。
例クエリパラメータに一連のフィルタがありますが、 リクエストにマッチするレコードを取得するためには、 そのうちのひとつだけが真である必要があります。クエリパラメータの構文は次のようになります:
 {height="" width=""} のようにします。
{height="" width=""} のようにします。
複数のフィルター
場合によっては、テーブルでチェックするフィルタが複数あることがあります。この場合、filtersオブジェクトに複数のフィルタを追加することができます。次のようになります:
filters=[{"field": "maytq_scrap_count", "arg": "15, "functionType": "greaterThan"},{"field": "maytq_scrap_reason", "arg": "scratch", "functionType": "equal"}].