

HTTP コネクタ出力の構造化方法について説明します。
概要
Tulipのコネクタファンクションエディタを使用すると、コネクタファンクションが返すデータを構造化して、アプリケーション内で有用で使用できるようにすることができます。この記事では、コネクタファンクションOutputをフォーマットする基本を説明します:
- コネクタ "出力 "の概念
- 出力をフォーマットするために使用できるツール
- さまざまな一般的な出力フォーマット
出力とは?
出力は、コネクター関数の戻り結果を定義および構造化するために使用されます。より大きなHTTPリターンボディからアプリにとって重要な情報を抽出する方法です。
 {高さ="" 幅=""}です。
{高さ="" 幅=""}です。
出力を構造化する方法
Connector Function Editorの左下にあるOutputsセクションを見つけます。
 {height="" width=""} 出力セクションを見つけます。
{height="" width=""} 出力セクションを見つけます。
出力の追加を開始するには、Add Function Outputsをクリックします。
出力には識別可能なラベルを付けるとよいでしょう。これらの名前はアプリ内で変数として表示されるため、区別できるようにすることが重要です。
 height="" width=""} {height="" width="
height="" width=""} {height="" width="
HTTPリクエストの結果を理解するためには、まずTest Resultsで返されるオブジェクトの形を理解することが重要です。下図は、結果がオブジェクトと配列のセクションに分割される様子を示しています。
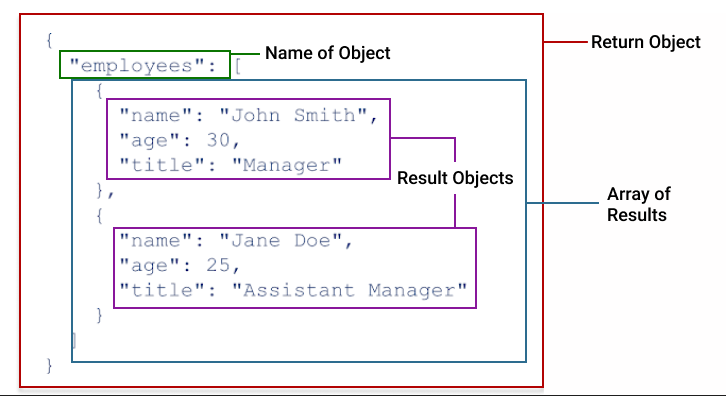
If you haven’t worked with JSON before, you may be unfamiliar with two critical datatypes, objects and arrays. Arrays are lists of values of the same type. For example, [1,2,3,5], or [oak, elm, alder, hickory]. Values in arrays are contained within square brackets, [ ]. Objects are a datatype for holding key:value pairs. The key:value pairs within an object can be of multiple different types, including arrays and nested objects. Objects are contained with curly brackets, { }.
オブジェクトと配列の詳細については、「コネクタ関数の出力における配列とオブジェクトの理解」を参照してください。
ドット表記
HTTP コネクタでは、出力は Dot Notation と呼ばれる形式を使用します。ドット記法を使用すると、オブジェクト内の値にアクセスできます。ドット記法は、大きな JSON レスポンスボディから必要なものだけを取り出すのに便利で、HTTP コネクタ関数をより柔軟に記述できます。簡単に言うと、互いに入れ子になっている値に基づく構造化フォーマットです。
コネクタ出力でドット記法がどのように使用されるか、例を挙げて説明します。
次の例は、"employees "と呼ばれるオブジェクトの配列で、各従業員の詳細が格納されています。各従業員の肩書きだけにアクセスしたい場合は、employees.titleという構文を使用します。Dotを使用して、興味のあるキーに関連付けられた値にアクセスします。最初の結果だけを取得したいとします。この場合、メイン・オブジェクトの名前「employees」と目的の値「title」の間にインデックスの位置を追加して指定します。employees.0.titleのような構文になります。より複雑なオブジェクトの場合、欲しい情報を引き出すために、オブジェクトの中にさらに入り込む必要があるかもしれません。
 {height="" width=""}のようになります。
{height="" width=""}のようになります。
もう一歩進んだ例を見てみましょう。この場合、ナレッジベースの記事に関連する情報を引き出すためのコネクタ関数を作成することに興味があるとします。私たちのコネクタは、特定の記事に関するデータを含む以下のJSONオブジェクト名 "data "を返します:
 {height="" width=""} です。
{height="" width=""} です。
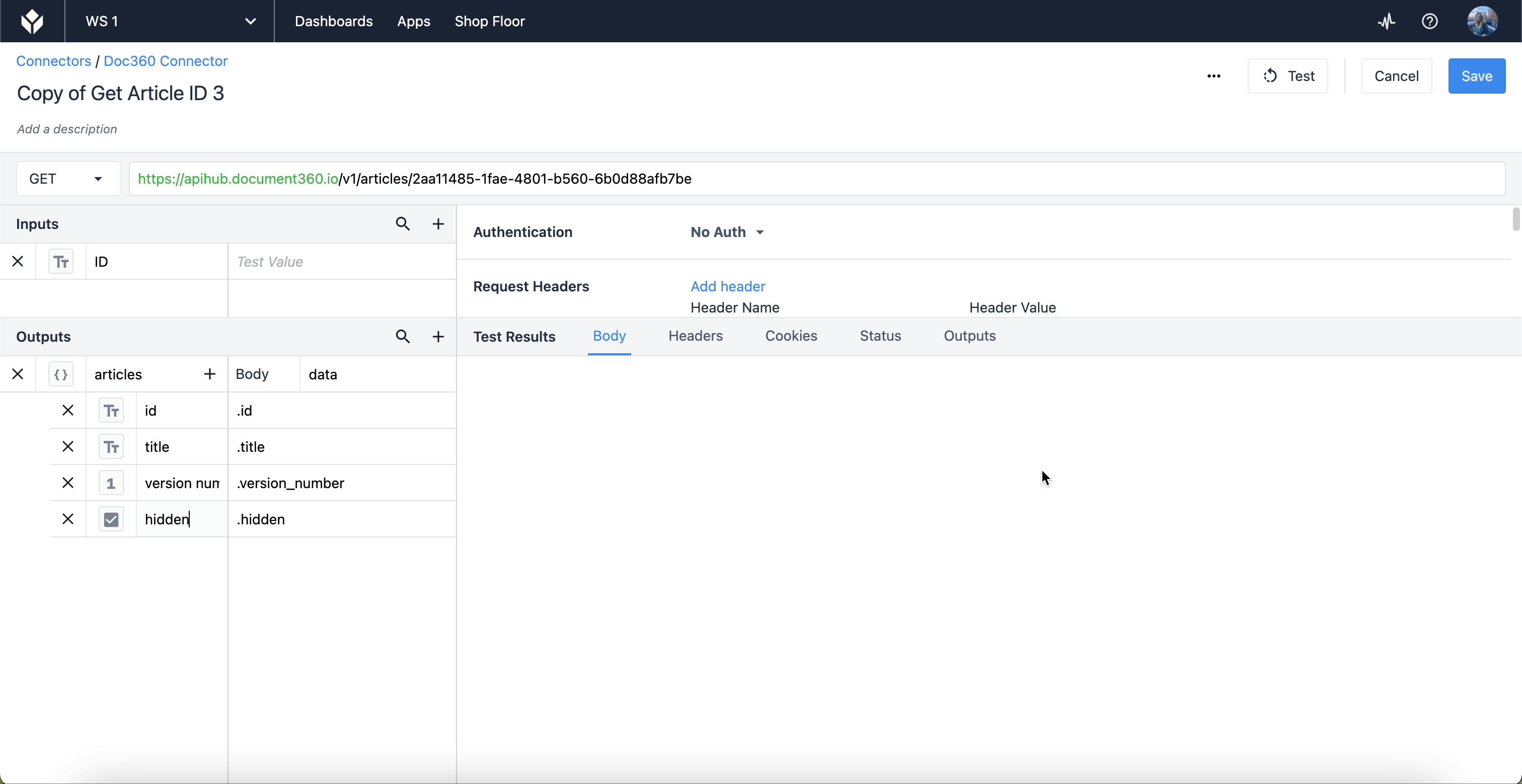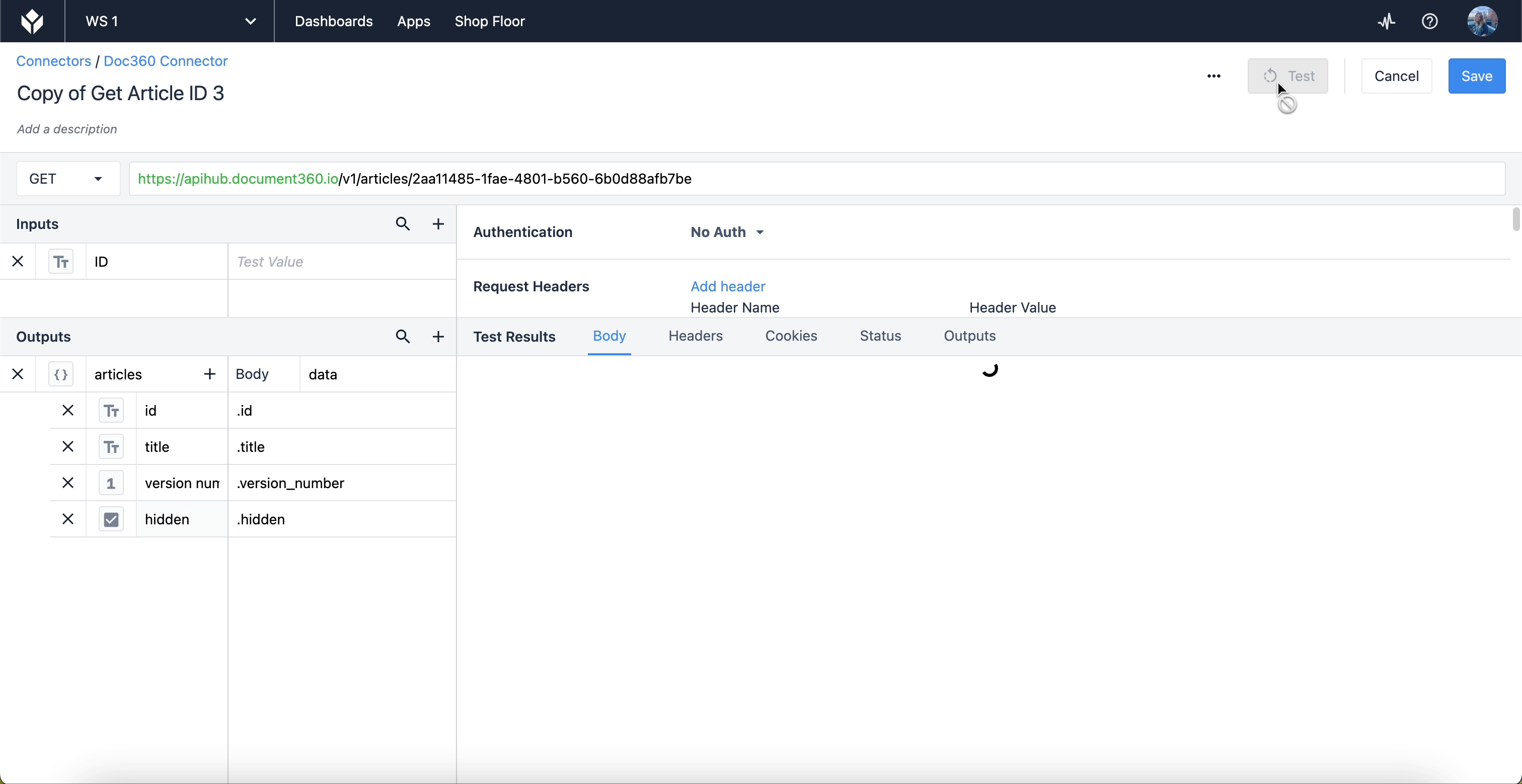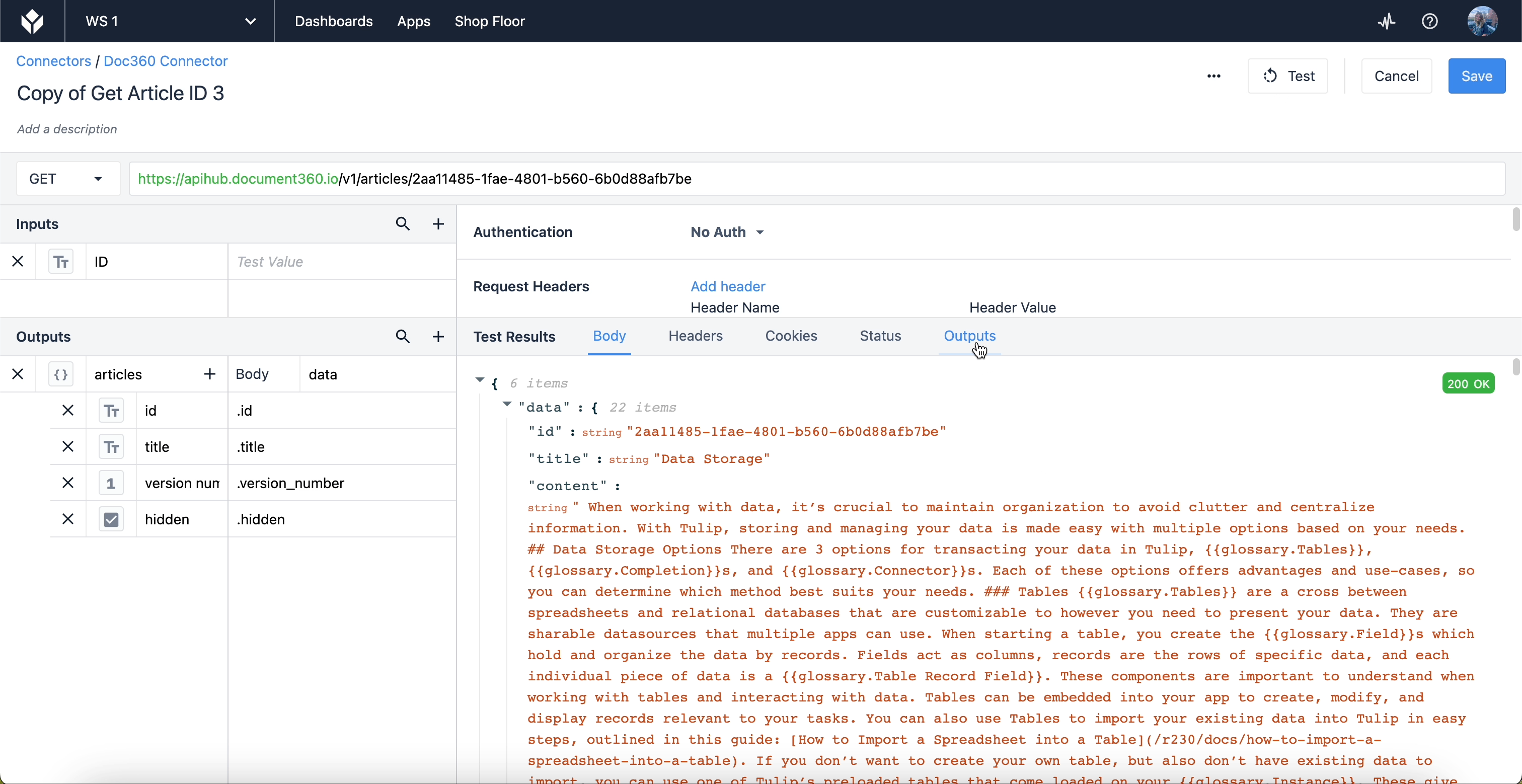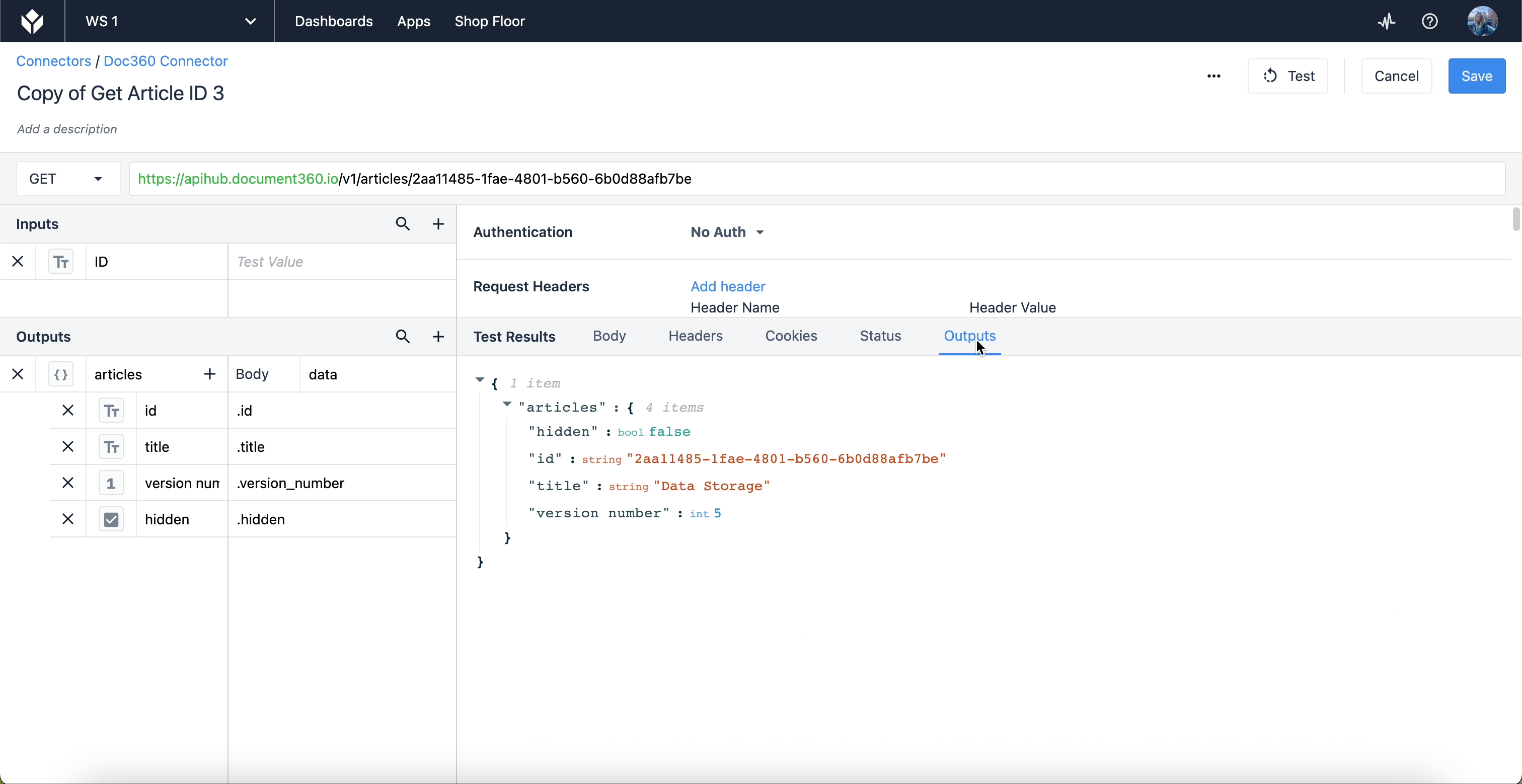
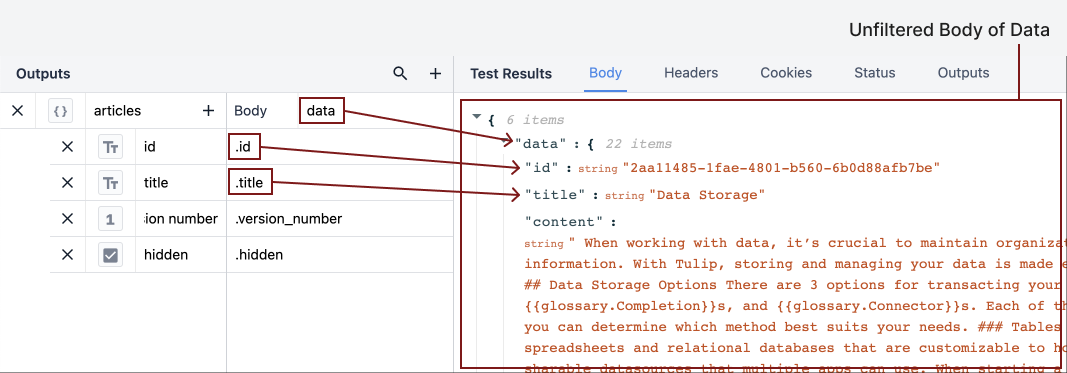
例えば、ID、タイトル、バージョン、記事が非表示かどうかだけを取り出したい場合。出力を使ってこれを指定する必要がある。エディターのoutputsセクションでドット記法がどのように見えるかを示してみよう:
 {height="" width=""}.
{height="" width=""}.
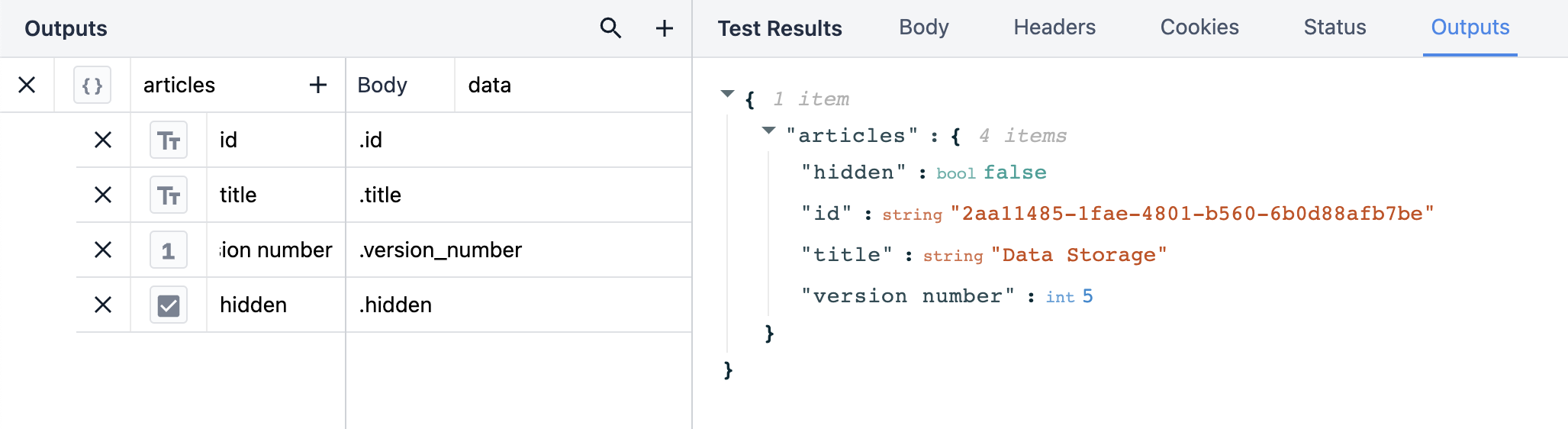
id "や "title "のような結果を引き出すには、JSON内のどこにそれらの結果があるかを指定する必要がある。出力の本体は "data "であり、Test Resultsセクションの最初のドロップダウンに対応します。data "ドロップダウン内の各結果は、そのオブジェクトの中にネストされている。Outputsセクションのピリオド/ドットは、"data "オブジェクトのレイヤーが1つ深いことを意味する。
It doesn’t matter whether the dot is placed in the body, or in front of individual properties, so long as there is a dot separating each layer of the JSON.
 {height="" width=""}.
{height="" width=""}.
テスト結果セクションのOutputsタブをクリックすると、Outputsで残りのデータがフィルタリングされ、気になる情報だけが表示されます。
出力を1行で書く方法もある。これは、1つのクエリでフルパスを表示します。
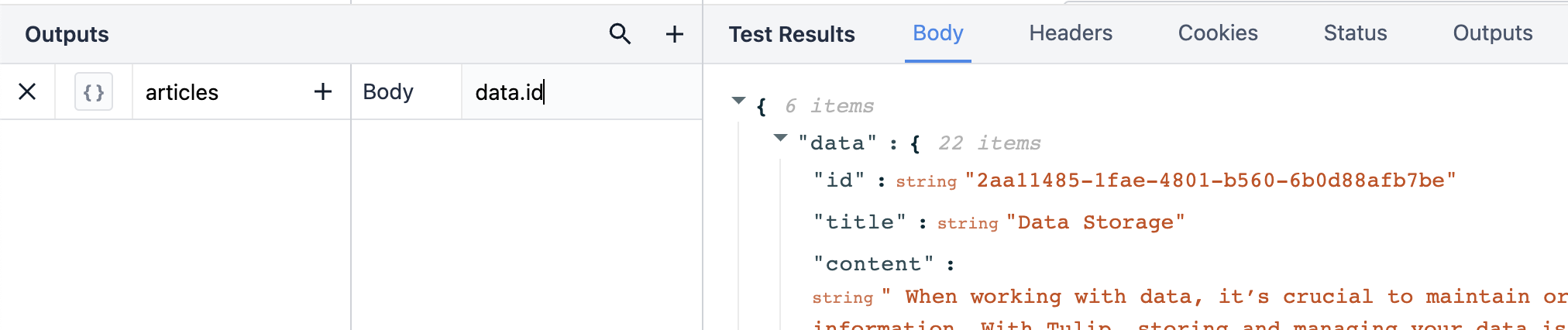 {高さ="" 幅=""}。
{高さ="" 幅=""}。
出力パスを簡単に書くには、データの行をクリックして新しい出力として追加することもできます。
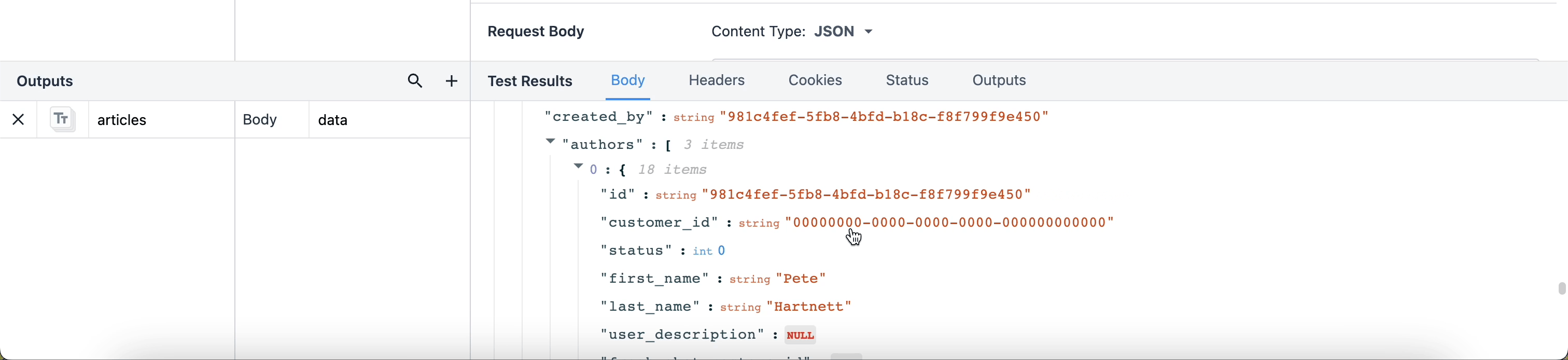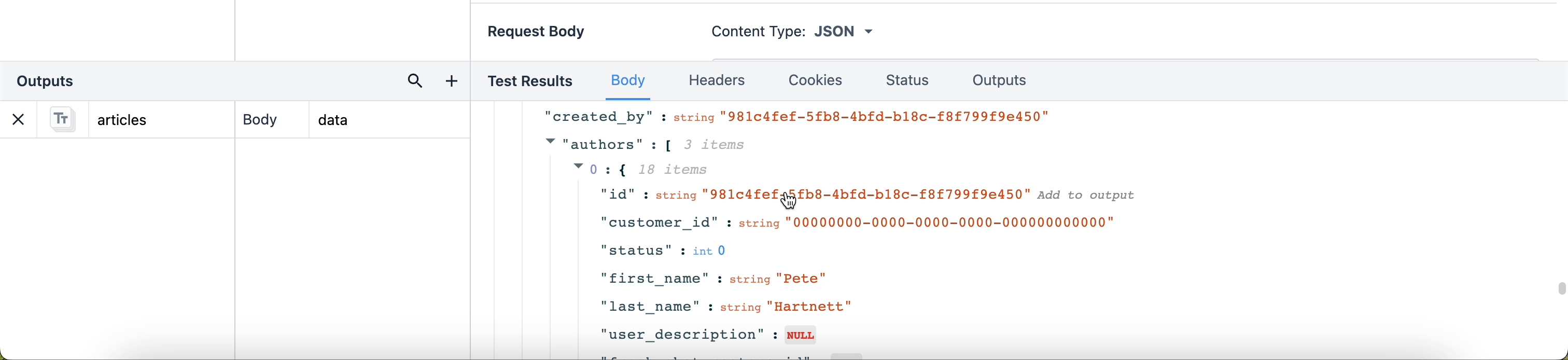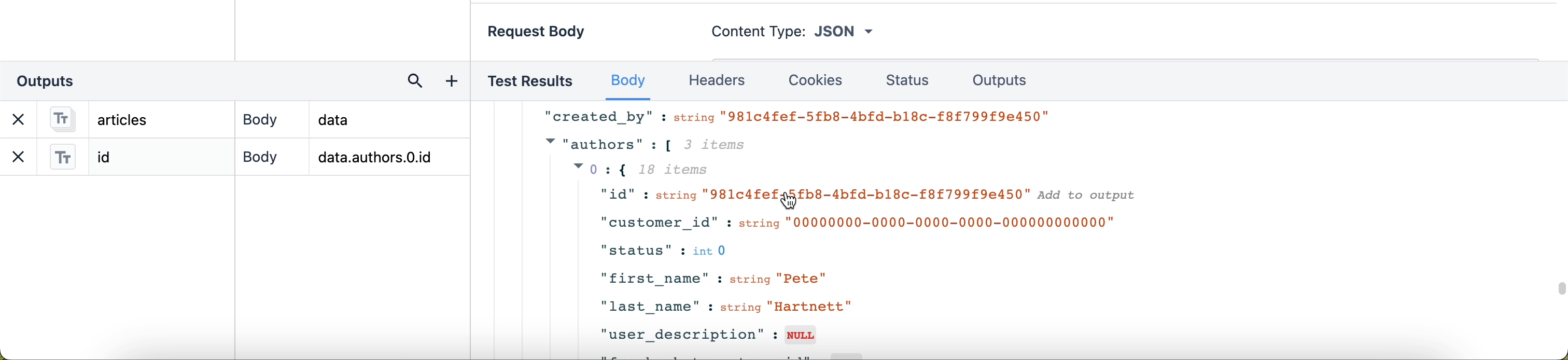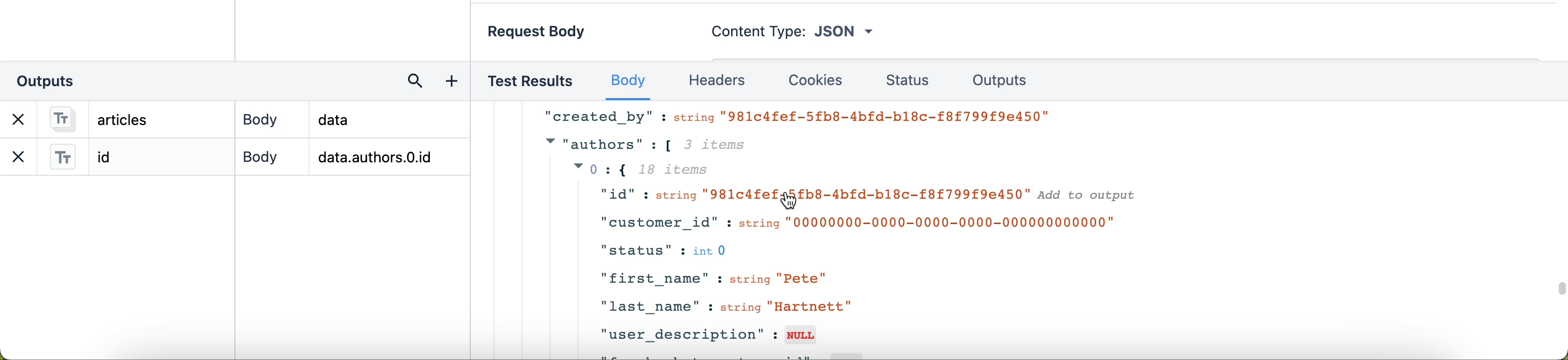 {高さ="" 幅=""}。
{高さ="" 幅=""}。
ドット記法の使い方については、こちらのリソースを参照:Processmakerを参照してください:JSONドット記法を参照してください。
出力結果
出力を構造化する方法は複数ありますが、それをどのように行うかは、アプリケーションでデータを使って何をしたいかに完全に依存します。出力の構造化を始める前に、最終的な目標について考えてみよう。個々の変数に複数のデータタイプを表示したいのですか?それとも、同じデータ型を1つの配列にまとめて、関連する情報を解析したいのでしょうか?
以下の例はすべて同じコネクタ関数に基づいており、いずれの場合もテスト結果の本体は同じです。しかし、出力は、どのように構造化されているかによって異なります。
次の例は、JSONパスdata.hits.slug.に対してコネクタがどのように出力するかを示しています。この出力が構造化されている方法では、コネクタはナレッジベース記事のすべてのURLスラッグの大きな配列を返します。私たちのアプリケーションでは、このコネクタは配列変数内でアクセスできます。
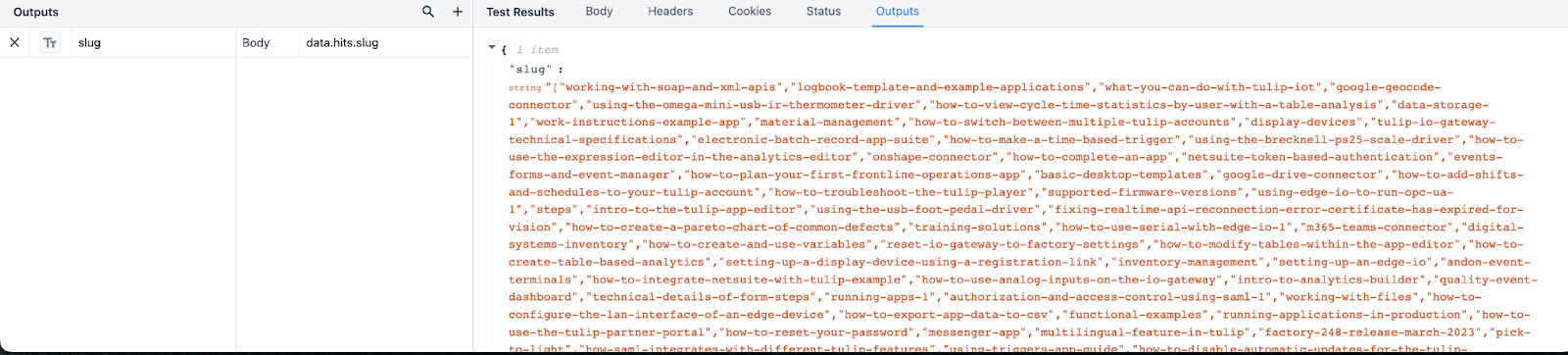 {height="" width=""} です。
{height="" width=""} です。
出力をオブジェクトのリストとして構造化し、結果から個々のデータタイプを取り出し、アプリケーションで個別に表示できる複数のデータオブジェクトを作成することができます。
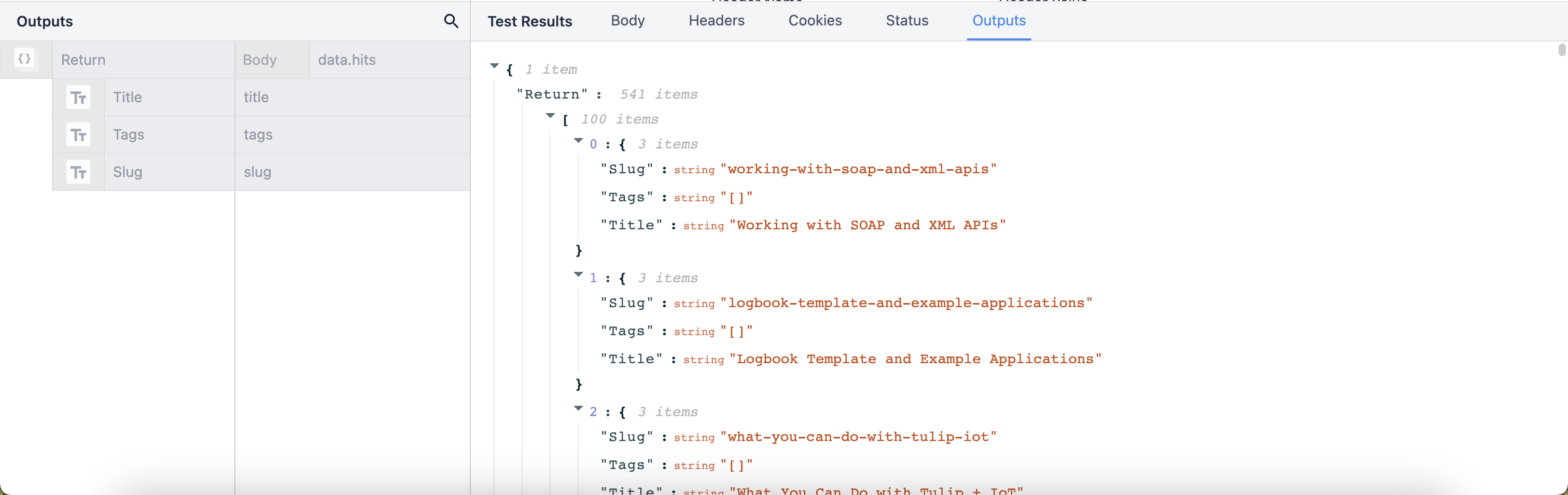 {高さ="" 幅=""}。
{高さ="" 幅=""}。
オブジェクトのリストは、その中に入れ子になった複数のデータ型を含むオブジェクトです。オブジェクトのリストを使用するには、出力タイプをクリックし、右隅のリストスイッチを切り替えます。
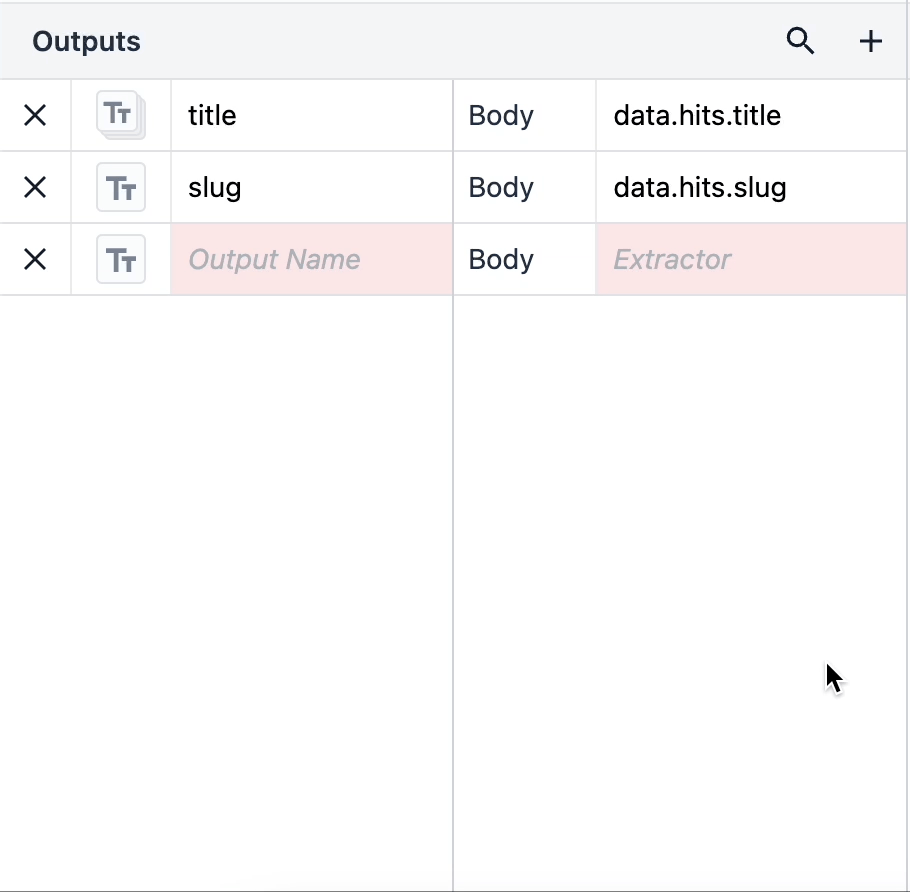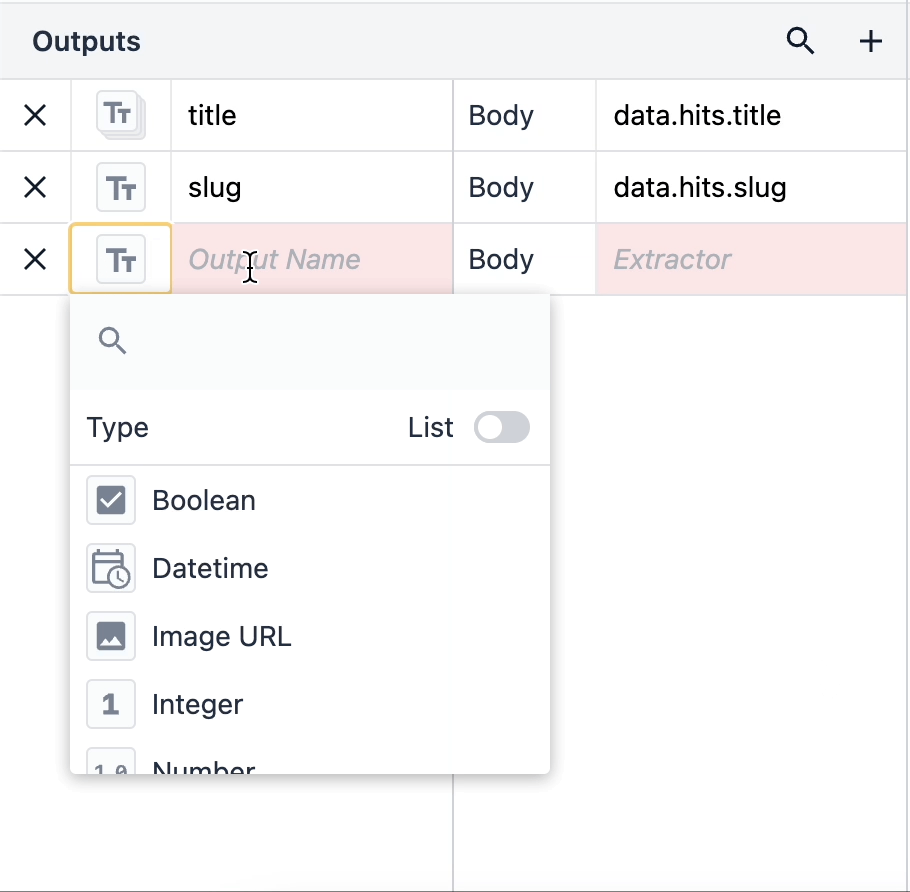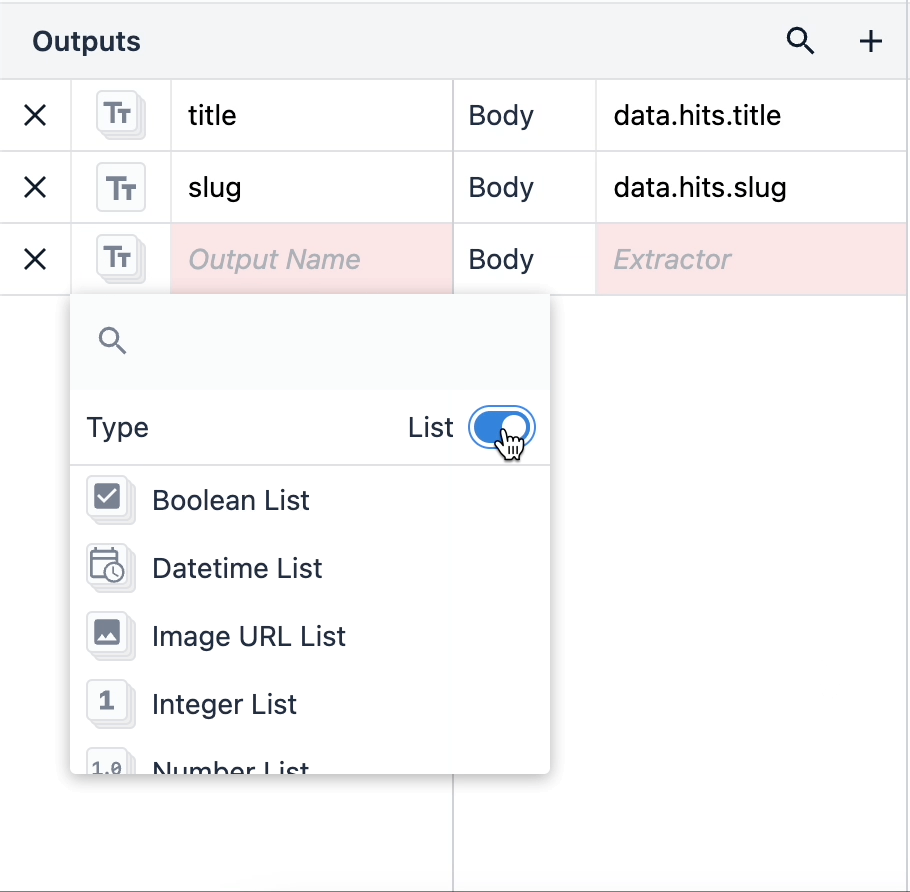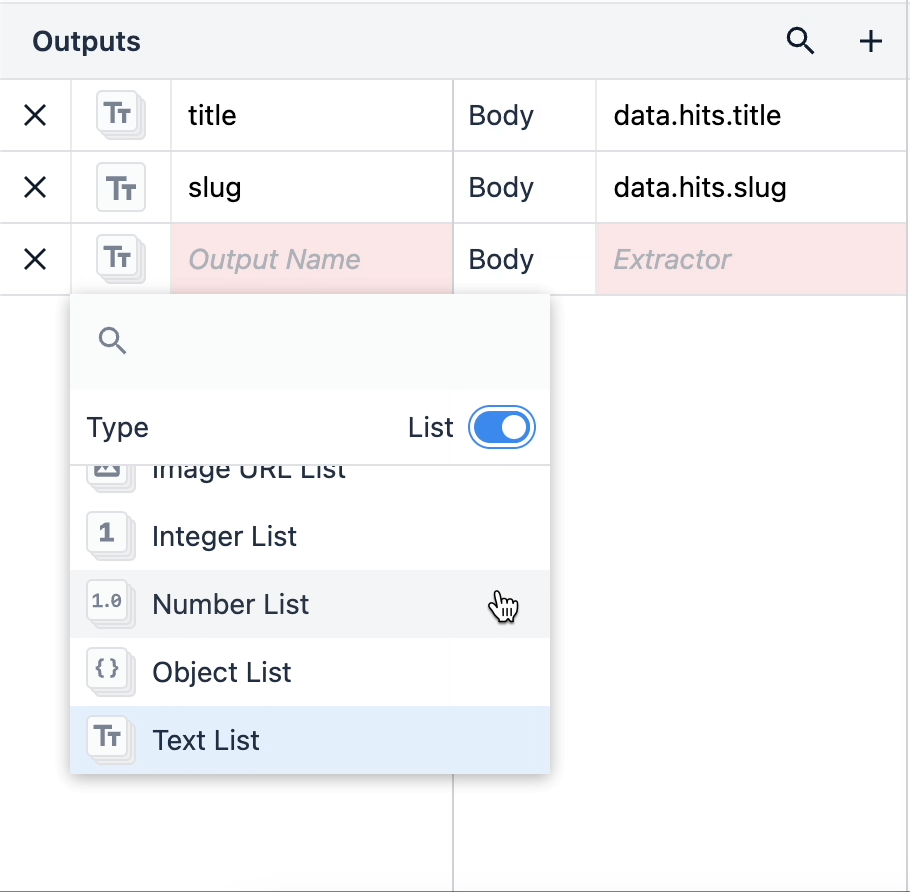 {height="" width=""} オブジェクトのリストがある場合、そのオブジェクトのデータ型がネストされます。
{height="" width=""} オブジェクトのリストがある場合、そのオブジェクトのデータ型がネストされます。
オブジェクトのリストがあれば、アプリケーションで異なるデータ型を個々のデータとして簡単に使用することができます。
上の例に戻って、出力パスdata.hits.slugをリストにしてみましょう。下の結果を見ると、Tulipがこのコネクタの戻り値をスラッグの配列として構造化しており、各インデックスの位置が各値の横にリストされていることがわかります。
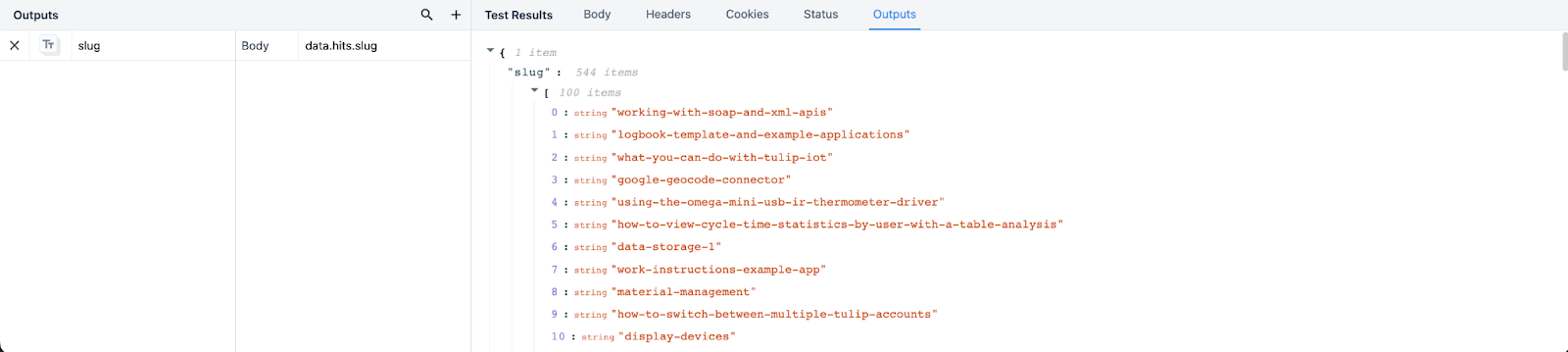 {height="" width=""} です。
{height="" width=""} です。
このように出力を理解した上で、独自のコネクタ関数に出力をマッピングし、コネクタから返される結果を最適化することができます!
さらに読む
お探しのものは見つかりましたか?
community.tulip.coで質問を投稿したり、他の人が同じような質問に直面していないか確認することもできます!