
このガイドでは
- チューリップでデータを保存する2つの異なる方法
- 異なるデータ保存方法を使用するタイミング
- データモデルを採用することの重要性
データを扱うとき、整理整頓は情報の乱雑さを避け、一元化するために非常に重要です。Tulipでは、ニーズに応じた複数のオプションにより、データの保存と管理を簡単に行うことができます。
チューリップのデータはどのように貴社の業務を把握するのでしょうか?
Tulipでは、データは複数のレベルで存在します。
アプリは、ステップ上のテキスト指示のような静的データを保存します。
テーブルはTulipが構築したデータベースで、作業指示のスプレッドシートのように、複数のアプリで使用できます。
完了は、アプリの期間、ステーション名、変数への入力データなどの生産メタデータを保存します。
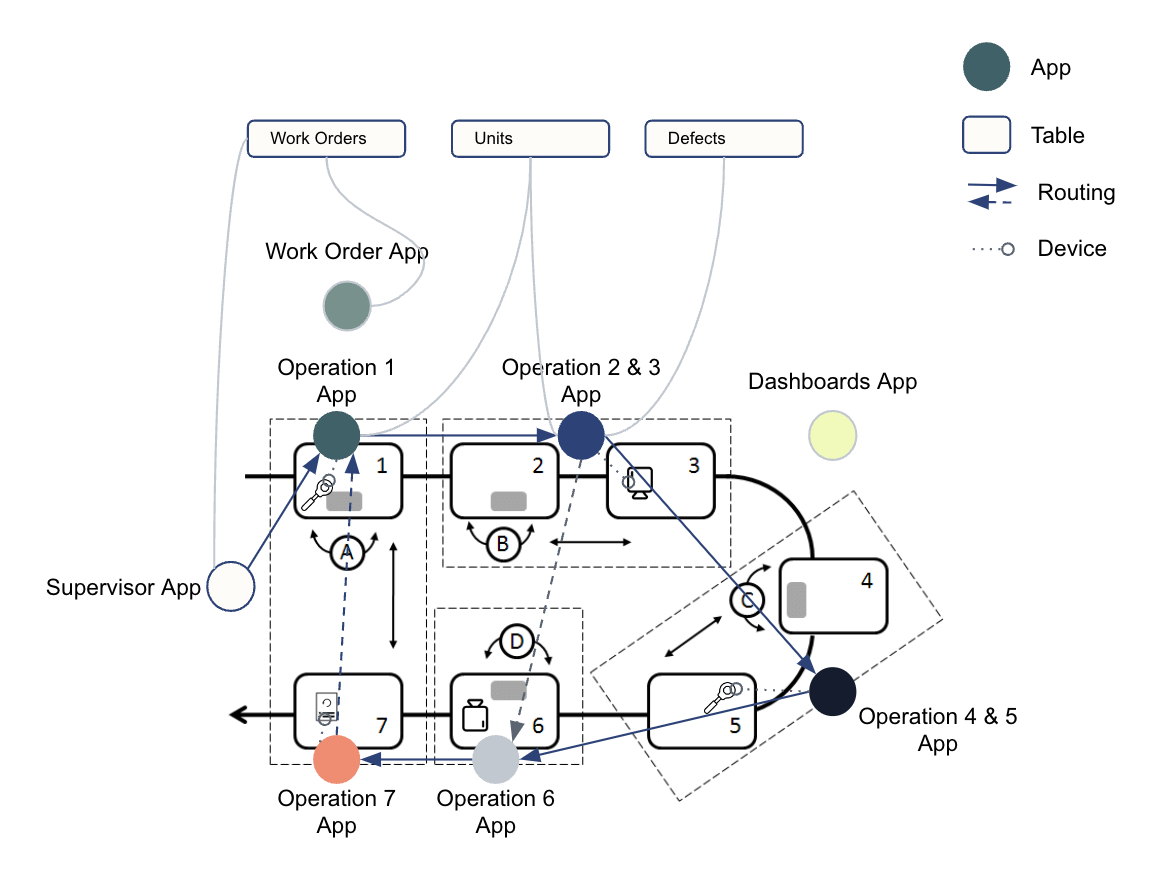 {height="" width=""} 以下の図は、製造現場全体のデータの運用フローを示しています。
{height="" width=""} 以下の図は、製造現場全体のデータの運用フローを示しています。
データ保存オプション
チューリップには、テーブルとコンプリートという2つのデータ保存オプションがあります。
テーブル
テーブルとは、スプレッドシートとリレーショナルデータベースの中間のようなものです。複数のアプリが利用できる共有可能なデータソースです。
テーブルを作成する際には、レコードごとにデータを保持・整理するFieldを作成します。フィールドは列として機能し、レコードは特定のデータの行で、個々のデータはテーブル・レコード・フィールドです。
テーブルをアプリに埋め込んで、タスクに関連するレコードを作成、変更、表示できます。
既存のデータをTulipテーブルにインポートすることができます。
独自のテーブルを作成したくないが、インポートする既存のデータもない場合は、インスタンスにロードされているTulipの設定済みテーブルを使用できます。これらは、テーブルで使用できるさまざまなフィールドと、ログに記録できる一般的なデータタイプを示すものです。データタイプのオプションは以下の通りです:
- テキスト
- 整数
- 数値
- ブール値
- 日付
- 間隔
- カラー
- 画像
- ビデオ
- ファイル
- マシン
- リンクレコード
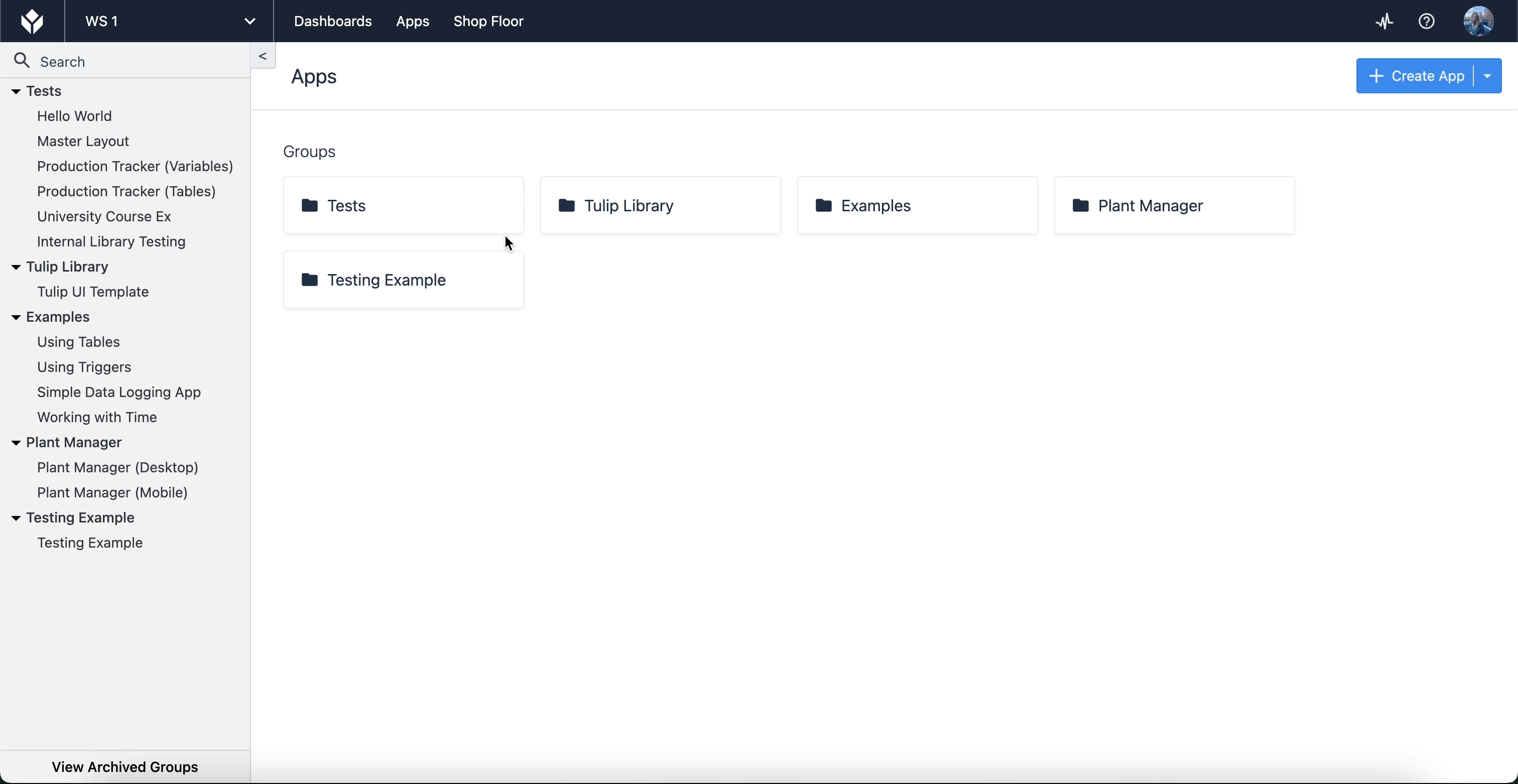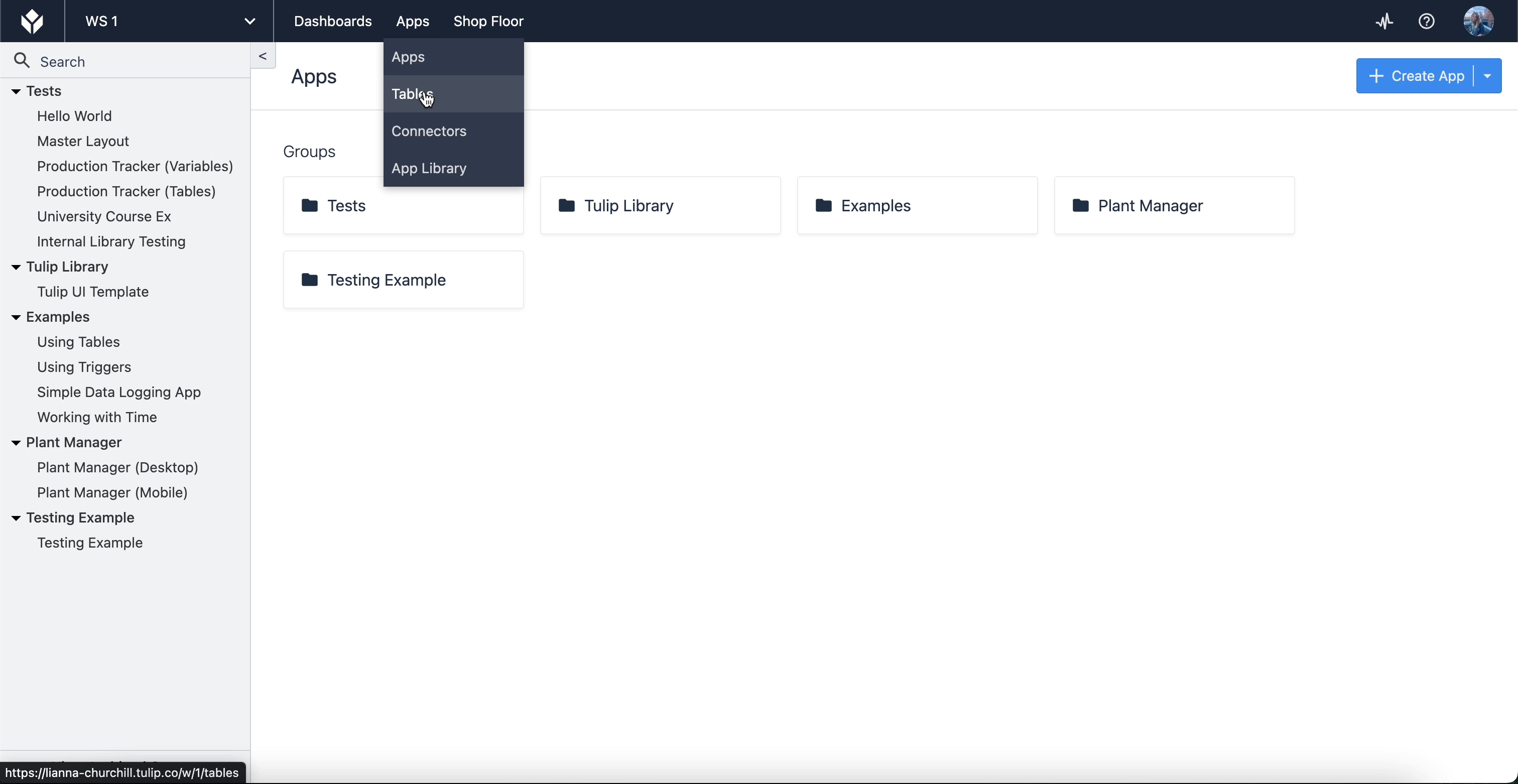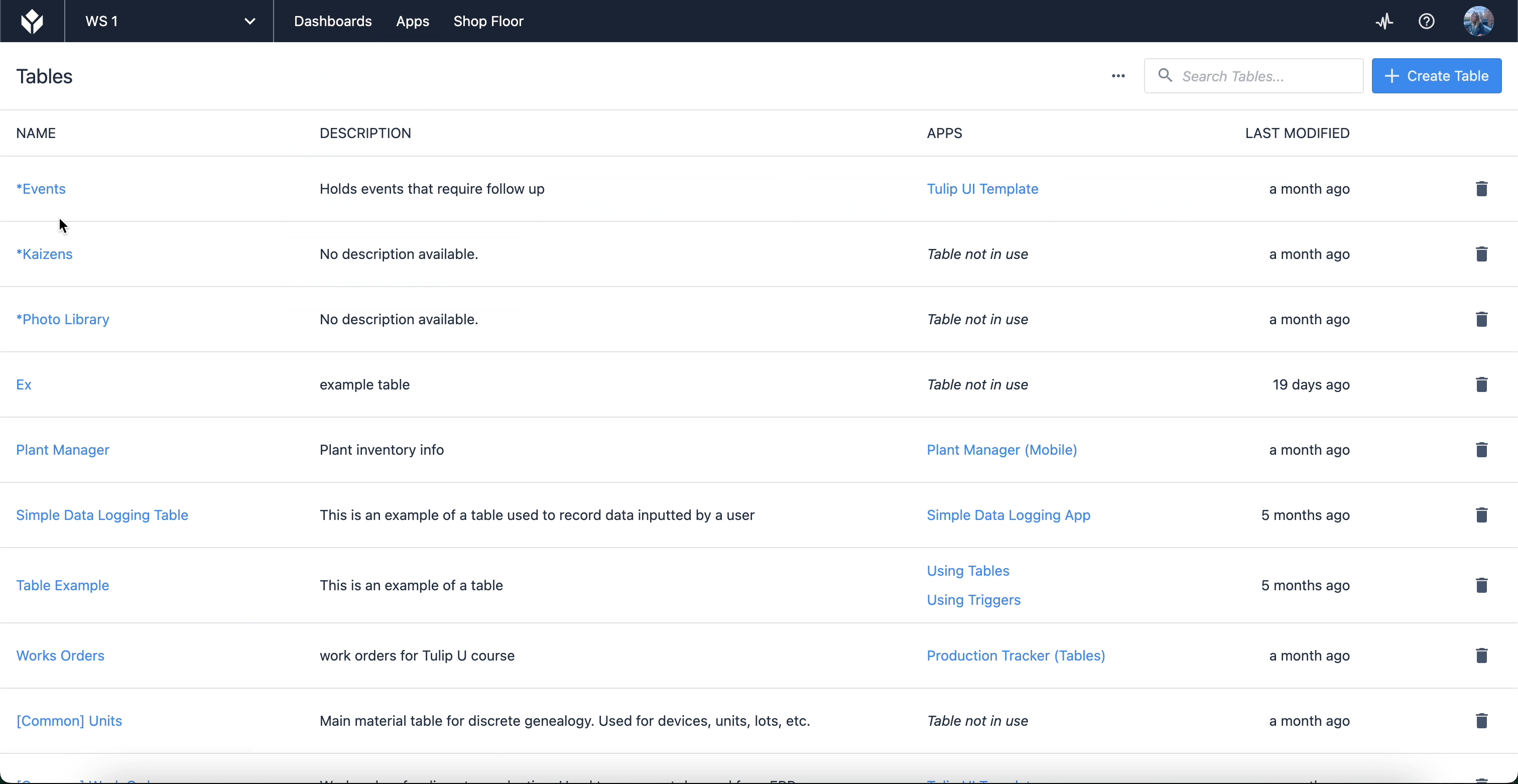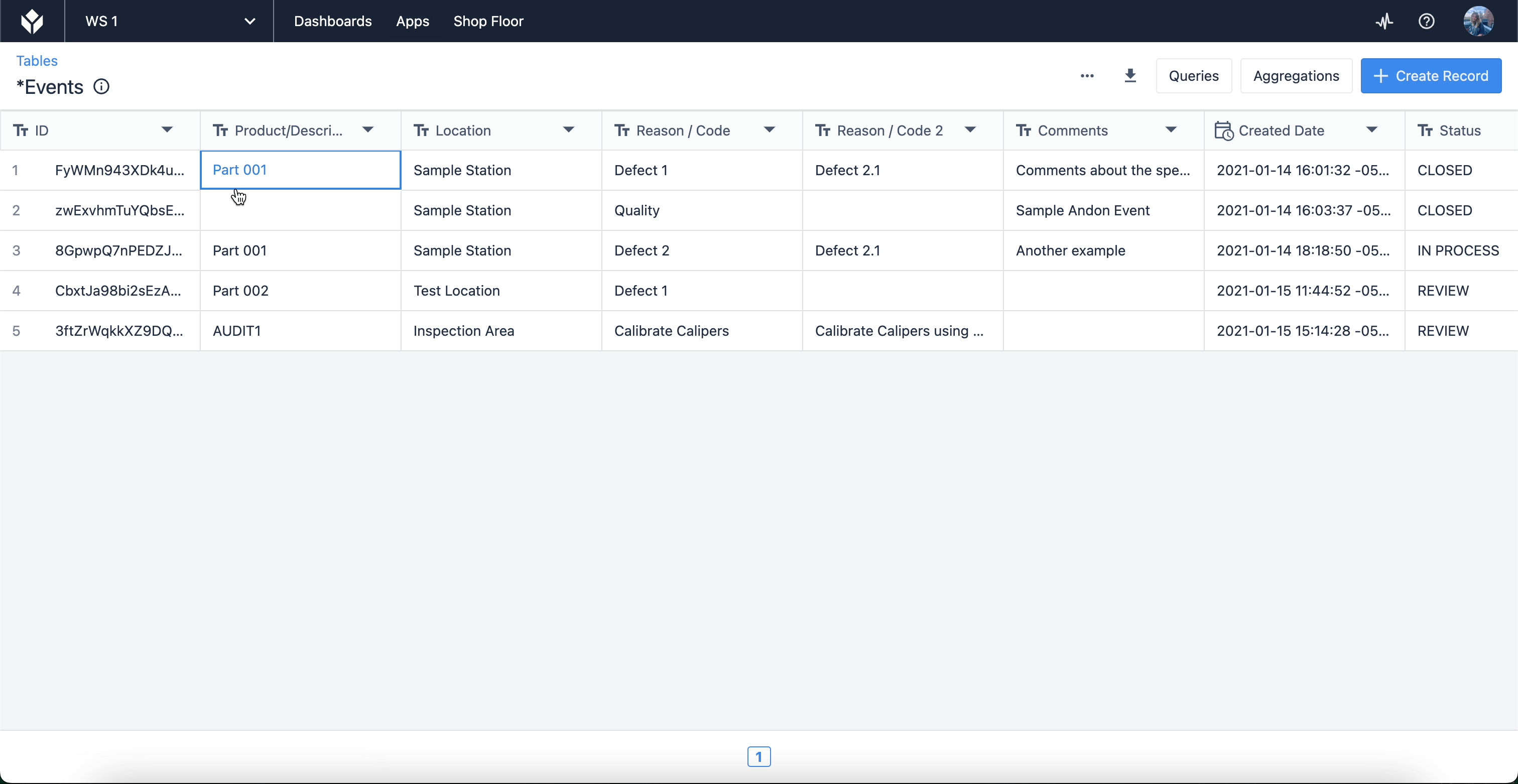
これらの各フィールドは、アプリケーションで使用されるデータ入力に対応します。テーブル内のレコードを表示するには、Tulipインスタンスページからテーブル画面に移動します。カーソルを "Apps "に合わせ、"Tables "を選択してください。
 {高さ="" 幅=""}」と表示されます。
{高さ="" 幅=""}」と表示されます。
ここには、アプリで使用するために作成した、またはアクセスできるテーブルのリストがあります。テーブルを選択すると、フィールドやレコード自体を編集したり、クエリや集計を作成したりすることができます。また、テーブル同士をリンクさせることも可能です(商品分類のような用途)。
推奨されるTulipテーブルの使い方
Tulipは、高レベルで2つの異なるタイプの成果物(物理的な成果物と運用上の成果物)を保存するためにテーブルを使用することを推奨しています。
物理的な成果物とは、バッチ/ロットや設備など、業務中に使用または生産される有形オブジェクトやコンポーネントです。運用上の成果物とは、不良イベントやカンバン構成など、業務を実現またはサポートする非物理的な要素やコンポーネントです。
テーブルの使用については、以下を参照してください:
補完
App Completions は、生産データの保存と整理に最適です。ユーザーがアプリを完了またはキャンセルすると、メタデータ・フィールドが自動的に生成され、保存されます。これらのフィールドには以下が含まれます:
- アプリの継続時間
- 開始時刻と終了時刻
- ログインしたユーザー
- ステーション名
- コメント
- アプリバージョン
- 実行ID
- Canceled (アプリがキャンセルされたかどうか)
テーブルに保存されたデータとは異なり、アプリの完了に保存されたデータは編集できません。このため、操作や変更ができない絶対的な情報となり、アプリの利用状況を正確に反映します。
完了データは 1 つのアプリでしか使用できず、外部システムからアクセスすることもできません。
アプリの完了データにアクセスするには、Tulipインスタンスのアプリグループからアプリを選択します。アプリのメイン画面で「Completion」タブを選択します。
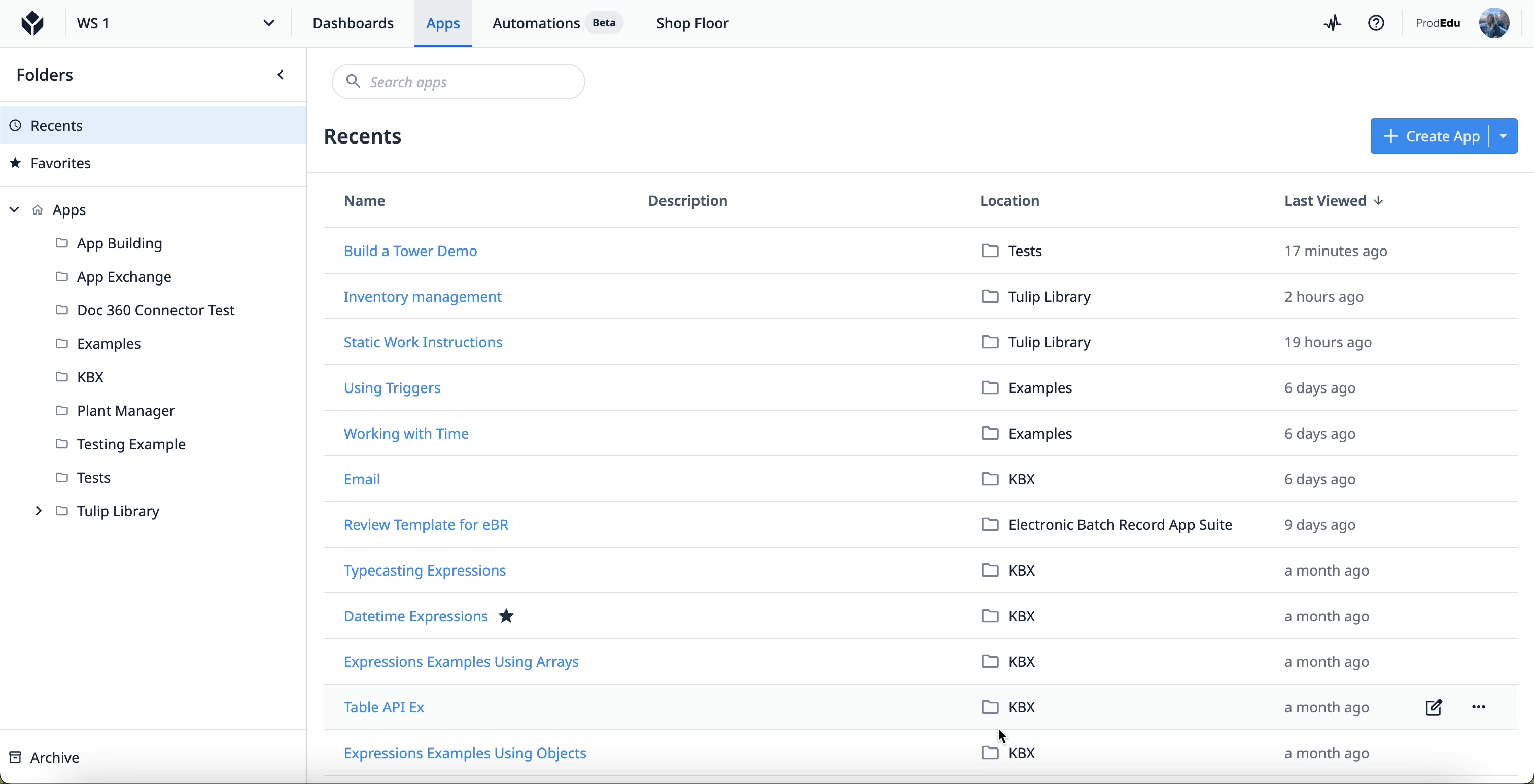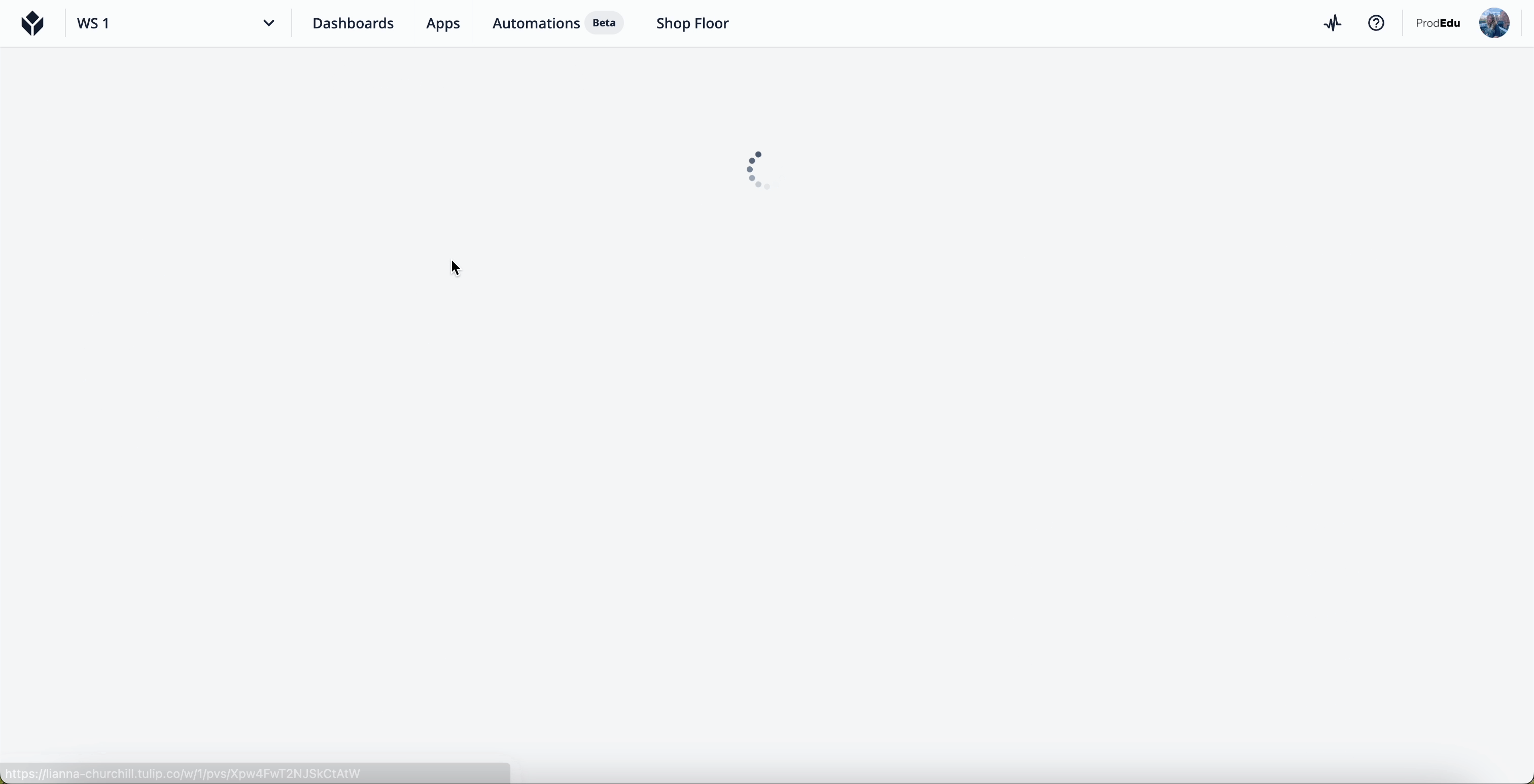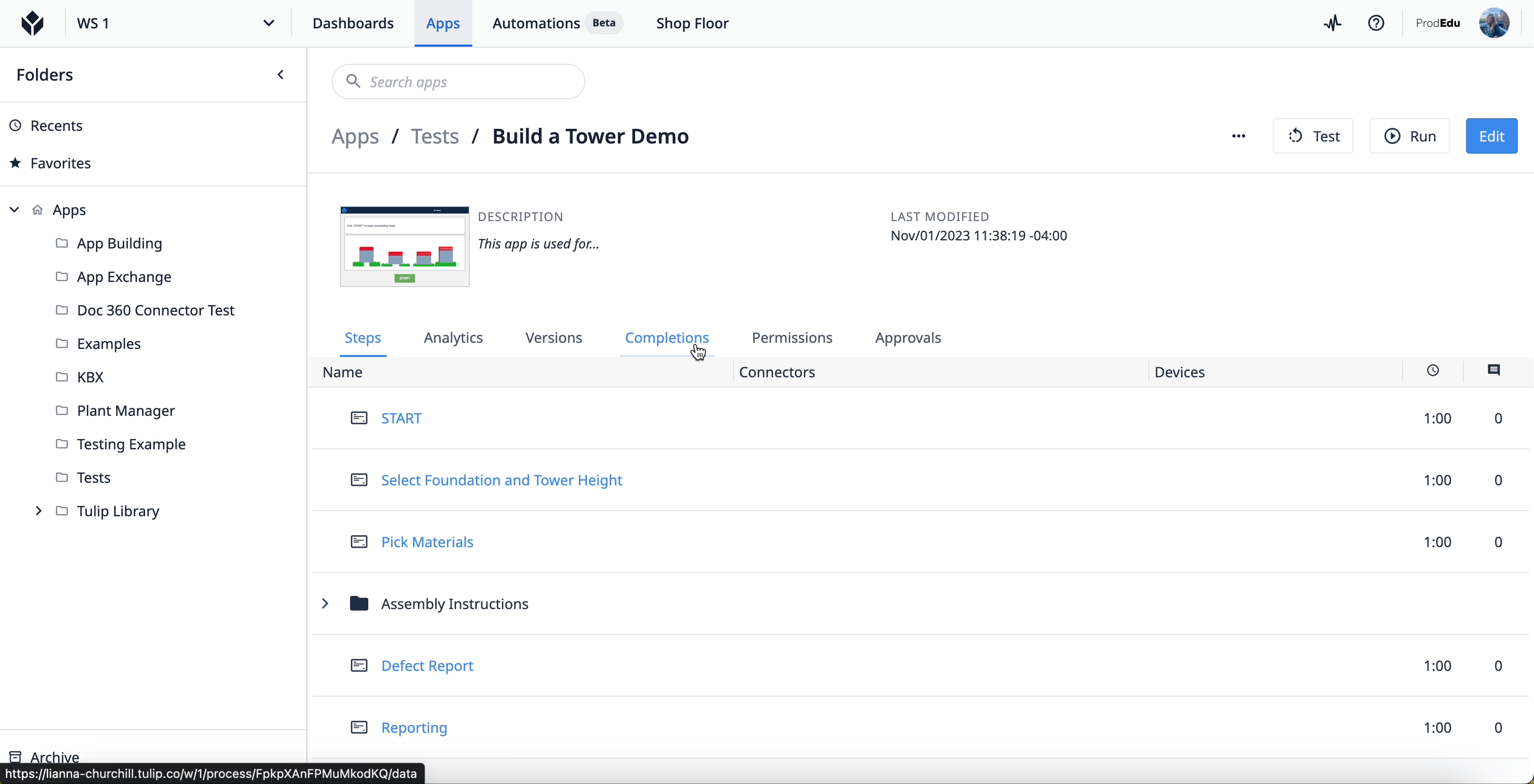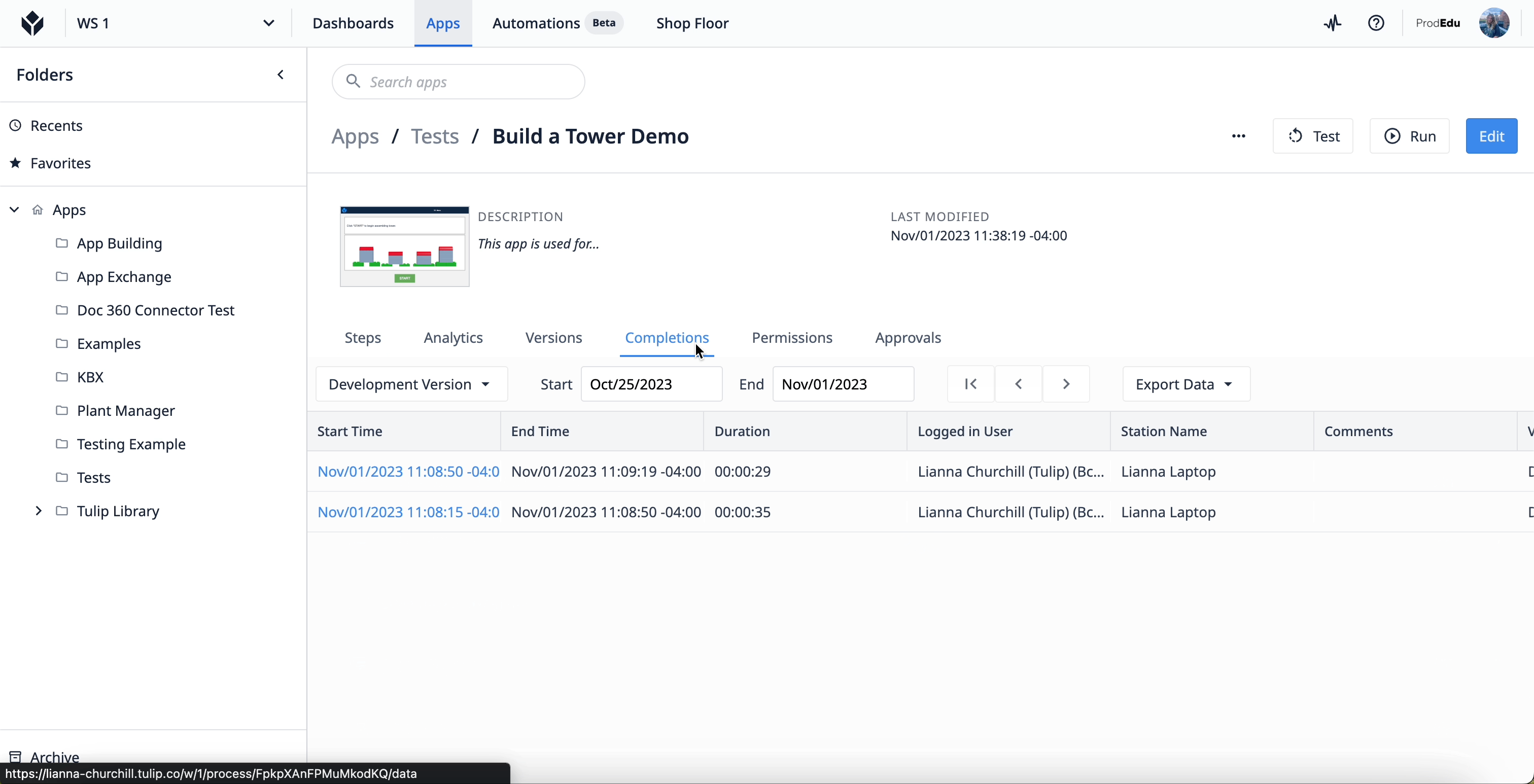 {height="" width=""}を選択します。
{height="" width=""}を選択します。
コンプリーションについて、詳しくはこちらをご覧ください。
テーブルとコンプリーション
コンプリーションはアプリのデータに自動的に保存されるため、データの代わりにテーブルを設定するのはどうかと思うかもしれません。
コンプリーションデータは不変ですが、テーブル内のフィールドは必要に応じて作成されます。また、テーブルデータは設定したトリガーや変数に基づいてアプリから書き込まれますが、完了データはユーザーがアプリを完了またはキャンセルしたときにのみ書き込まれます。完了データが簡単で即座に自動化できるのに対し、テーブルデータはアプリ独自のものにすることができ、複数のアプリでデータを使用できる柔軟性があります。
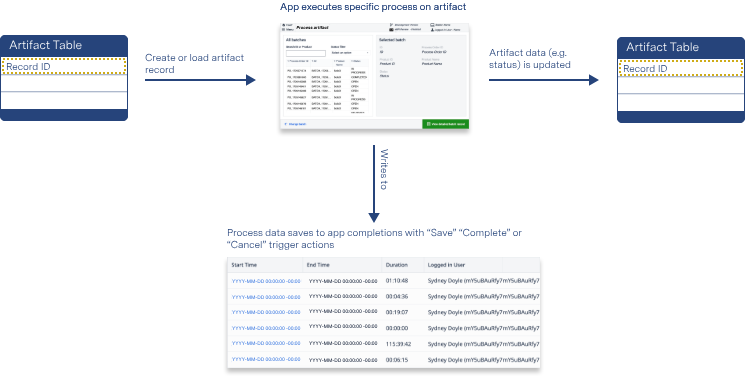 {高さ="" 幅=""}。
{高さ="" 幅=""}。
データ保存のベストプラクティス
データストレージは運用に合わせてカスタマイズできるため、データ構造を設定する方法はたくさんあります。チューリップでは、以下のような目的でテーブルを構築し、データを保存できるように、いくつかのプラクティスを推奨しています:
- データに簡単にアクセスできる
- データは必要な人やシステムから見えるようにする
- データは一元管理され、他と重複しない
チューリップのデータ保存のベストプラクティスについては、こちらをご覧ください。
データモデルの適用
チューリップには、複数のユースケースに対応する共通のデータモデルがあらかじめ用意されています:
Tulipでは、共通データモデルは、アプリのソリューション全体でデータを共有するのに十分な柔軟性を持つ、定義されたテーブルのコレクションです。
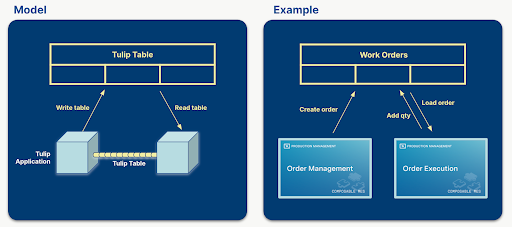 {height="" width=""} 以下の図は、アプリを通じてテーブルがどのように共通データを共有するかを示しています。
{height="" width=""} 以下の図は、アプリを通じてテーブルがどのように共通データを共有するかを示しています。
共通のデータモデルは、標準化された拡張可能なデータスキーマを提供し、広く使用されている概念(作業指示、単位など)を表現することで、システム間でのデータ処理を合理化します。これにより、データの作成、編集、分析が簡素化され、データ管理を改善する大きな機会がもたらされる。
チューリップテーブルは、主にデジタルツインモデルに従うべきです。つまり、テーブルは物理的な工場や現場をできるだけ厳密に反映する必要があります。テーブルがマスターデータを保存したり、完成記録や外部レコードのデータと重複したりしないように、履歴データは完成記録に限定する必要があります。
共通データモデルの使用方法については、こちらをご覧ください。
チューリップ大学の共通データモデルコースは こちら。
アプリでデータを使用する
アプリでテーブルデータを表示、編集、入力するには、まずウィジェットに慣れる必要があります。{glossary.入力ウィジェット}}では、テーブルに反映されるデータを編集・入力できます。埋め込みウィジェットは情報を表示し、テーブルと対話できるように設定できます。テーブルデータの組み込みに関する完全なチュートリアルについては、以下を参照してください:
完成したデータは、Analyticsを通じてアプリに表示できます。まず、完了データを使用して分析を作成し、その分析をアプリに組み込む必要があります。
完了データを使って分析を作成する方法については、こちらをご覧ください。
チューリップがデータを保存する方法
チューリップはセルフサービス型のプラットフォームなので、どのデータを送信・保存するかはお客様が決定できます。チューリップクラウドは、MongoDBまたはPostgreSQLデータベースを使用して、AWS上にデータを保存します。チューリップは、すべての画像、動画、PDFをAmazonのS3ストレージに自動的にアップロードするので、ストレージの管理や収集したデータの追跡を心配する必要はありません。
次のステップ
Tulipのエキスパートによるガイダンスでデータ操作を開始:*チュートリアル:最初のテーブルを作成する* データとテーブルを扱うUniversityコース* アプリの完了とテーブルを理解するUniversityガイド* 外部システムとの統合
お探しのものは見つかりましたか?
community.tulip.coで質問を投稿したり、他の人が同じような質問に直面していないか確認することもできます!
.gif)