
TulipからRedshift(または他のデータクラウド)へのデータ移行を簡素化するためのGlue ETLスクリプトでTulipのテーブルを照会する
目的
このスクリプトは、Tulipテーブル上のデータをクエリし、Redshiftまたは他のデータウェアハウスに移動するための簡単な出発点を提供します。
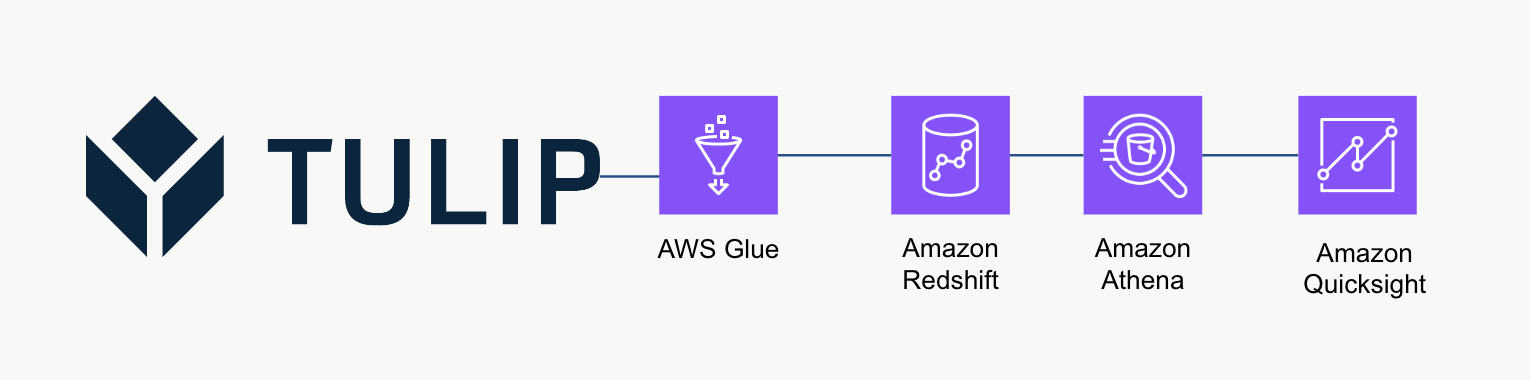
ハイレベル・アーキテクチャ
この高レベルのアーキテクチャは、TulipのテーブルAPIからデータをクエリし、さらなる分析や処理のためにRedshiftに保存するために使用することができます。
スクリプト例
以下のスクリプト例は、Glue ETL (Python Powershell)を使用して単一のTulpテーブルにクエリを実行し、Redshiftに書き込む方法を示しています。注:スケーリングされた本番ユースケースの場合、代わりに一時的なS3バケットに書き込み、バケットの内容をS3にコピーすることを推奨します。さらに、認証情報は AWS Secrets Manager 経由で保存されます。
python
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table_id = 'aKzvoscgHCyd2CRu3_DEFAULT' def get_secret(secret_name, region_name): # シークレットマネージャークライアントの作成 session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name=region_name ) try: get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: # throw された例外のリストについては # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html raise e を参照 return json.loads(get_secret_value_response['SecretString'])
redshift_credentials = get_secret(secret_name='tulip_redshift', region_name='us-east-1') api_credentials = get_secret(secret_name='[INSTANCE].tulip.co-API-KEY', region_name='us-east-1')
# SQLエンジンを構築する
url = URL.create( drivername='postgresql', host=redshift_credentials['host'], port=redshift_credentials['port'], database=redshift_credentials['dbname'], username=redshift_credentials['username'], password=redshift_credentials['password'] ) engine = sa.create_engine(url)
header = {'Authorization' : api_credentials['auth_header']} base_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0)
# 日時スタンプの取得
now = datetime.now() df['datetime_updated'] = now
# Redshiftに書き込む
df.to_sql('station_activity_from_glue', engine, schema='product_growth', index=False,if_exists='replace')
## スケールに関する考察
Redshiftに直接データを書き込むのではなく、S3からRedshiftにデータをコピーする中間的な一時ストレージとしてS3を使用することを検討してください。この方が計算効率が良くなります。
さらに、メタデータを使用して、単発のチューリップテーブルではなく、すべてのチューリップテーブルをデータウェアハウスに書き込むこともできます。
最後に、この例のスクリプトは毎回テーブル全体を上書きします。より効率的な方法は、最後の更新またはクエリ以降に変更された行を更新することです。
## 次のステップ
さらに読むには、[*Amazon Well-Architected Frameworkを*](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/index.en.html)チェックしてください。これは、データフローと統合の最適な方法を理解するための素晴らしいリソースです。