

ユニバーサルテンプレートのガイドと、機能体験を最適化する方法。
glossary.ユニバーサルテンプレート}}は、分析をシームレスに構築するための単一のエクスペリエンスです。データのクエリと可視化を分離することで、可視化タイプを切り替えることができます。ユニバーサルテンプレートは、すべての分析タイプとTulipデータソース(コンプリーション、テーブルデータ、マシンデータ)をサポートしています。

クエリと可視化の使用
クエリは、アプリ、マシン、またはTulipテーブルの「生」データに対して、システムに何をさせたいかを詳細に示す指示のようなものです。クエリの結果は、クエリの設定方法に基づいてTulip Analyticsが作成したデータの表形式表現です。クエリーの設定は、アナリティクス・エディターの左側のパネルで行います。
そのクエリから得られたデータを、すべて、または選択した部分のみを表示するさまざまなビジュアライゼーションで視覚化できます。ビジュアライゼーションはアナリティクス・エディターの上部で選択し、アナリティクス・エディターの右サイドパネルでさらに設定します。
テーブル」ビジュアライゼーションが選択されていない限り、「クエリ結果を表示」をクリックすると、ビジュアライゼーションの下に常にクエリ結果が表示されます。
クエリの構築
データソース
データソースは分析を構築するものです。アプリの完了データ、テーブルデータ、またはマシンデータから選択できます。
アプリの完了データの分析を構築する場合、複数のアプリを選択できます。 これにより、分析では選択したすべてのアプリの完了レコードが考慮されます。
複数のアプリを選択した場合、データは結合されず、各完了は個別の行として扱われることに注意してください。つまり、完了の「フィールド」(ユーザー、開始時間、駅など)を共同で分析できます。アプリ変数のような他のデータは、アプリごとに別々に扱われ、他のすべてのアプリの完了レコードの値は「null」になります。
マシンの分析を構築する場合、1つまたは複数のマシンタイプを選択できます。特定のマシンの分析を構築する場合は、追加のフィルターを追加します。
グループ化と操作
グループ化と操作は、クエリ構築の中核となる部分です。ここでは、どのデータオプションをどのような形式で表示するかを定義します。
グループ化
グループ化は、可能な限りグループを組み合わせるための指示を与えます。一般的なQLツールやBIツールのGROUP BY関数に慣れていれば、グループ化のプロセスはほぼ同じように動作します。グループ化は、類似した値を見つけるためにデータのフィールドとタイプを決定します。グループ化によって、見たいデータをより細かく表示できるようになります。
グループ化によって、どの行を結合するかをよりコントロールできるようになります。グルーピングは、どのタイプのフィールドでも可能です。どの操作を設定したかによって、1つまたは複数のグルーピングを追加した場合の結果は異なります。
いくつかのグループ化の組み合わせを見てみよう。
| 1つのグルーピング|複数のグルーピング| ---| ---| ---| ---| ---| グループ化フィールドの値とその行の個別の値を表示するソース・データの各行に対して 1 行、グループ化フィールドの値とその行の個別の値を表示するソース・データの各行に対して 1 行、グループ化フィールドの値とその行の個別の値を表示するソース・データの各行に対して 1 行。グループ化値|グループ化フィールドの区別されるエントリの各組み合わせに対して 1 行で、グループ化に対するそれぞれの値と、それぞれのグループ化値を持つソース・データからのすべての行の集約値|区別される値と集約|グループ化の値と区別される値を示すソース・データの各行に対して 1 行で、そのグループ化値を持つソース・データからのすべての行の集約値 (つまり、集約値は同じ値です)。集約された値は、同じグループ化値を持つすべての行で同じです。)| ソース・データの各行に 1 行ずつ、グループ化の値と、それぞれのグループ化値を持つソース・データからのすべての行の集計値 (つまり、同じグループ化値を持つすべての行で集計値が同じ) を表示します。
データが表示されるのは、関連する情報を持つ行が存在する場合のみであることに注意することが重要です。特定の日のソース・データにデータがない場合、分析は空白で表示されます。
グループ化がどのように機能するかの例を見てみましょう: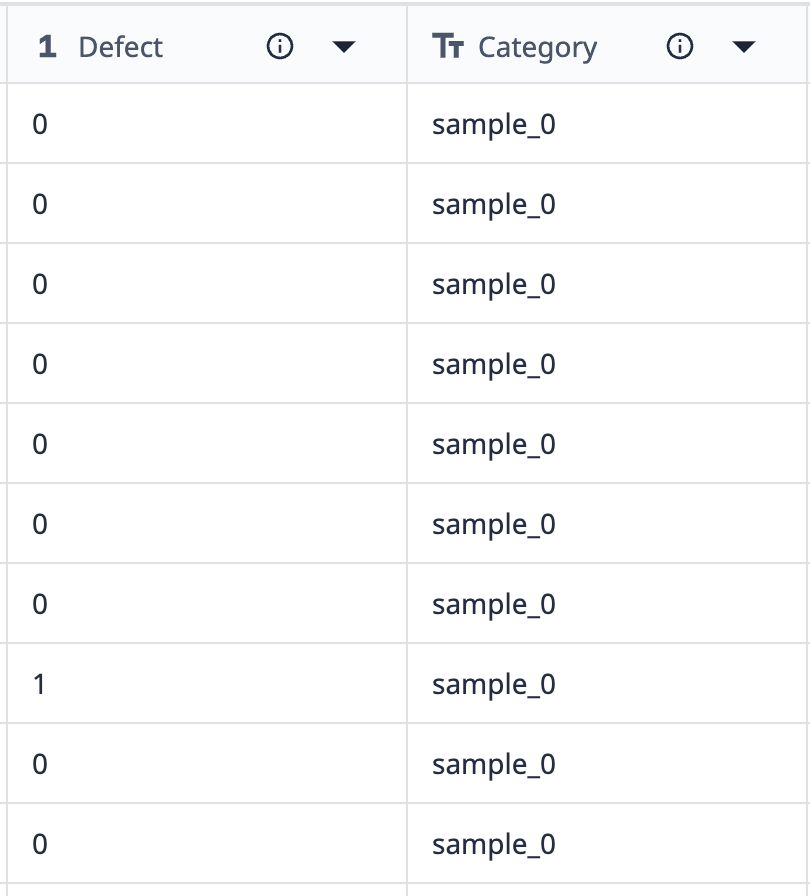
このテーブルのデータから、"sample_0 "というラベルが付いたレコードが10件あることがわかります。このデータをグループ化して、欠陥数が異なる sample_0 ポイントのみを表示するビジュアライゼーションにしたい場合、グループ化を使用して同じようなデータセットを組み合わせることができます。
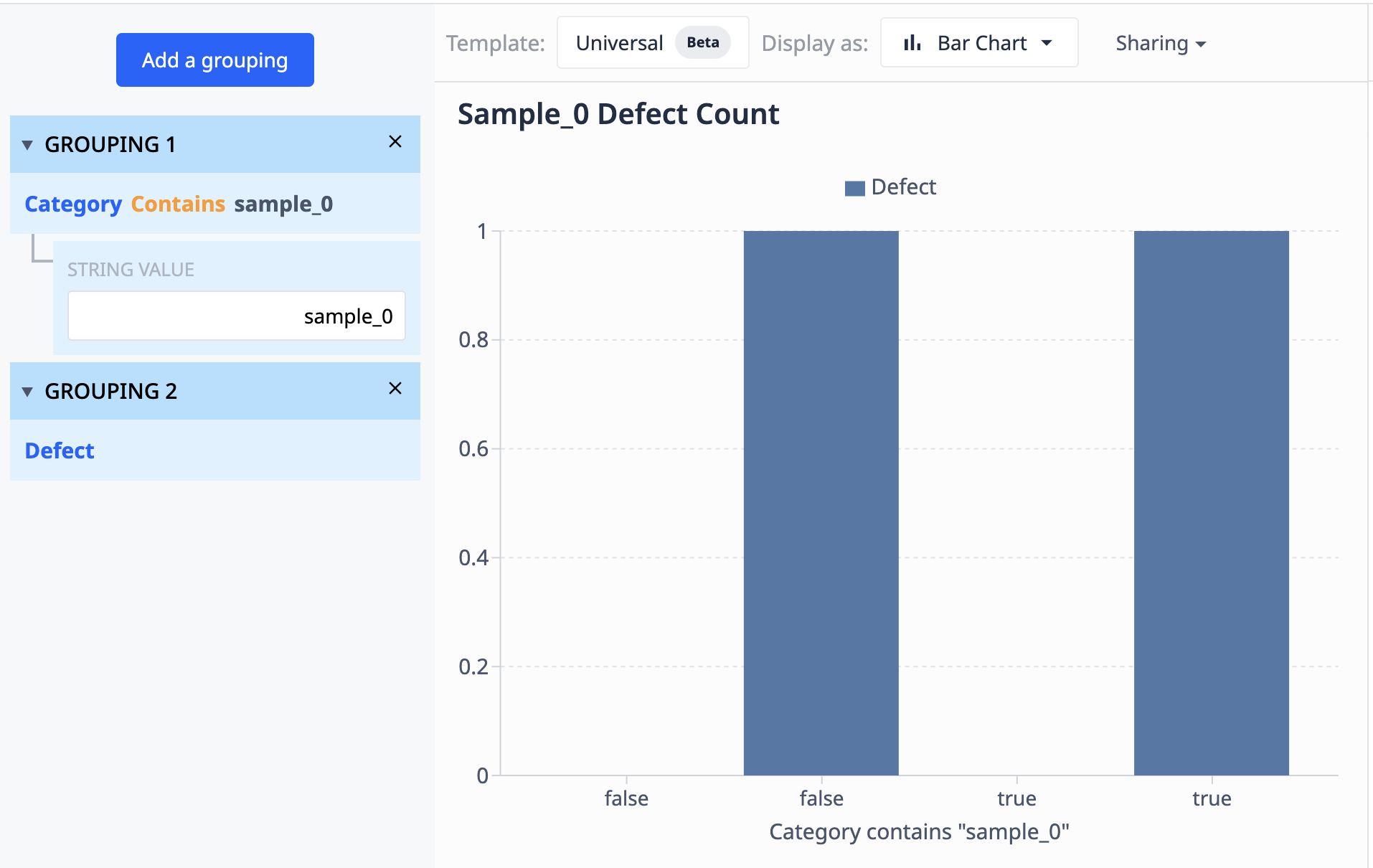
演算
演算には、複数のレコードを結合する集約と、結合しないフィールドがあります。
操作には一般的に2つのカテゴリーがあります。1.識別値 識別値は、ソース・データからの個々のデータ・ポイントを表します。最も単純なケースでは、これは完了レコードの変数、テーブルのフィールド、またはマシン属性の1つの値です。
しかし、同じレコードからの 2 つのフィールドの合計、複数の文字列の組み合わせ、または集計関数を含まない式のような、より高度なデータ ポイントである場合もあります。
値のフィールド(数値)とタイムスタンプのフィールド(datetime)を含むテーブルを使用すると、タイムスタンプによって値がこのように表示されるように視覚化することができます:
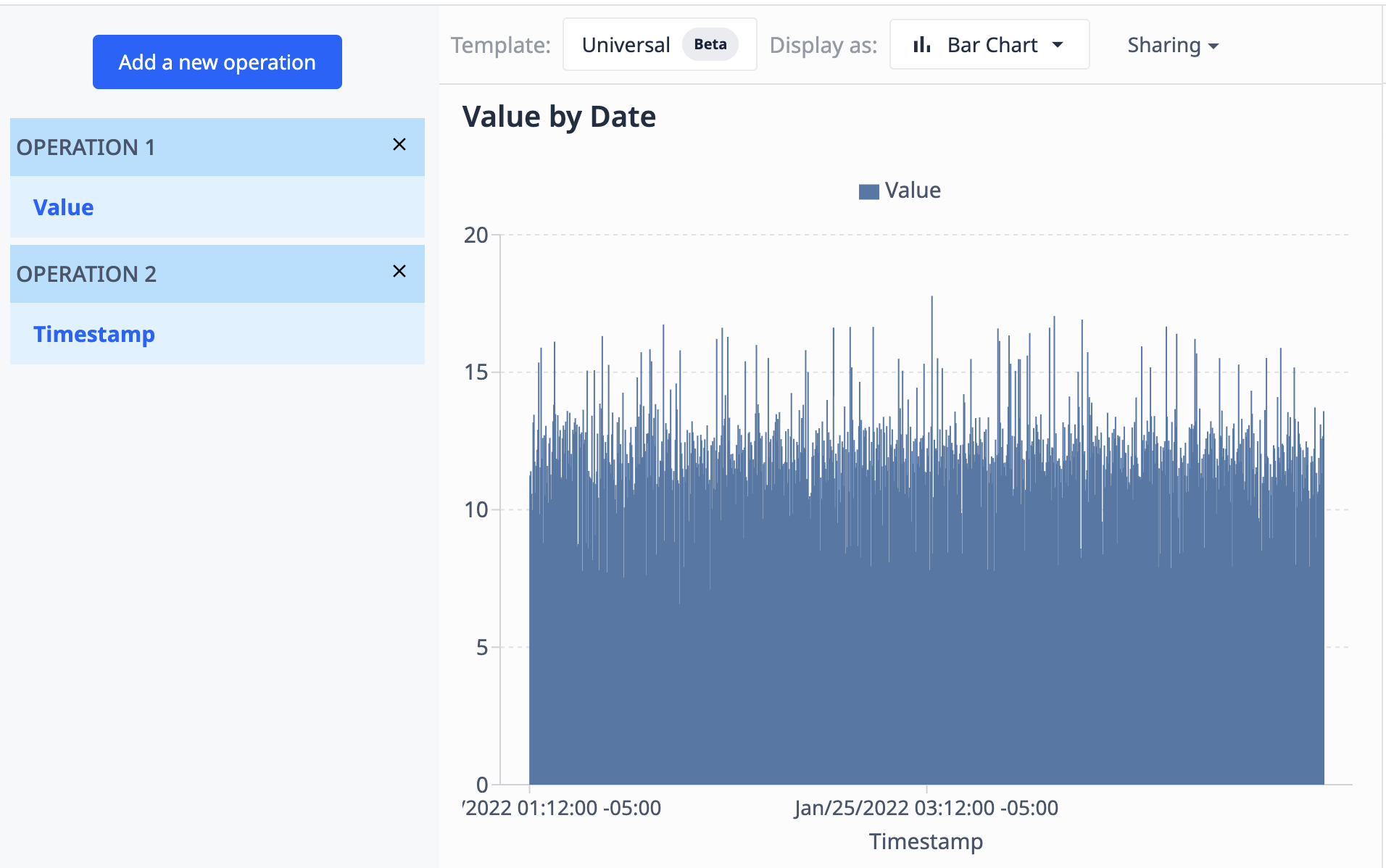
- 集計
集計は、複数の行からデータを取り出し、セットロジックに基づいてそれらを結合する関数です。あらかじめ設定された選択項目として集約関数のセットが用意されていますが、式エディタ内で集約関数を使用して独自の高度な集約を構築することもできます。異なる集約関数は、異なるデータ型に対して機能します。どの関数が利用可能で、どのデータ型をサポートしているかは、以下を参照してください。
直接アクセス可能な集計関数これらは行の結合を可能にします:
- 平均
- 中央値
- 合計
- 最小値
- 最大値
- 最頻値
- 標準偏差
- 95パーセンタイル
- 第5パーセンタイル
- 比率
- 比率の補完
式エディタで使用可能な集計関数
式エディタの集計関数は、特定の要件に基づいてより詳細なデータを提供できます。分析で使用できるすべての式の完全ガイドについては、「Analytics Editorの式の完全リスト」を参照してください。
制限と並べ替え
制限を追加することで、クエリ結果に含まれる行の最大数を定義できます。制限を使用すると、特定のデータに焦点を絞ったり、グラフに表示されるデータ量に上限を設定したりできます。例えば、制限を追加して、過去 1 ヶ月間に最も欠陥の多かった 3 つの生産ラインを表示できます。
ソート・データは、制限を評価する際にどの行を含めるかを定義します。クエリ結果の一部である任意のフィールドに対して、昇順または降順の並べ替えを追加できます。ソート用に複数のフィールドを追加した場合、データは最初のものからソートされます。最初のフィールドの各値に対する結果のグループは、次に2番目などでソートされます。
並べ替えを明示的に定義しない場合、クエリ結果の並べ替えは利用可能なデータによって異なる可能性があることに注意してください。順序軸を持つ制限やチャートを使用する場合、これはさまざまなビジュアライゼーションにつながる可能性があります。このような場合は、適切なソートを追加することをお勧めします。
以下の例では、Operationsを使用したグラフを使用しています。ここでは、結果を100個のデータ・ポイントに制限し、日付の降順でソートしています。
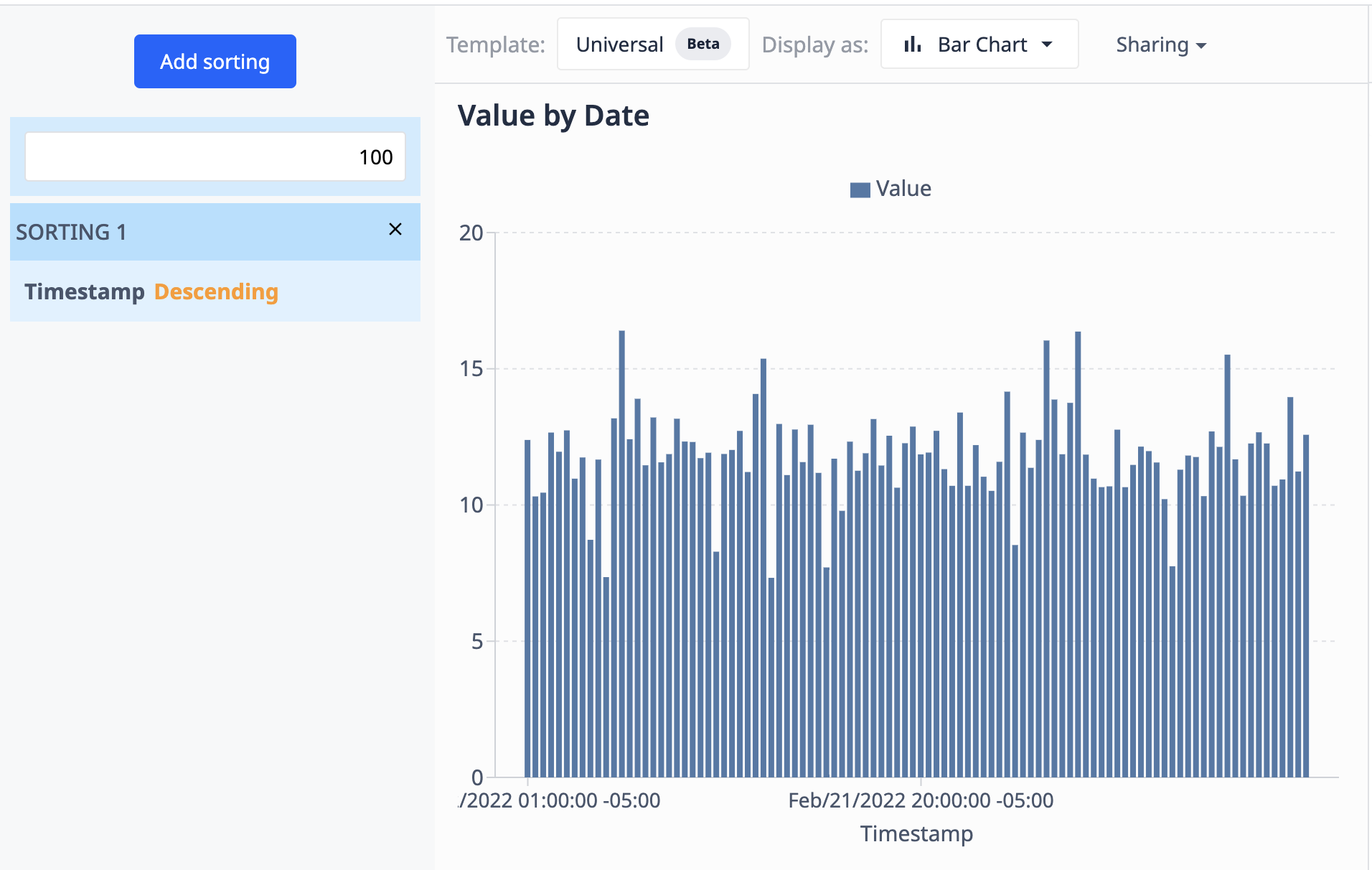
データソース(テーブル)が新しいレコードで更新されると、ビジュアライゼーションでは最新の100件のみが表示されます。
日付範囲
日付範囲は、分析の評価に含まれるデータを定義します。これは、データセット内の日時値に対するフィルタのようなものです。パフォーマンス上の理由から、後でフィルタを追加して時間を絞り込むのではなく、ユースケースに応じて可能な限り短い日付範囲を使用することをお勧めします。
アプリ完了データ * アプリ完了の「開始時間」 * テーブルの日付(ユーザーが選択可能) * 作成日 * 更新日 * マシンデータ * マシンアクティビティエントリーの開始時間
フィルター
フィルタは、クエリ結果にどのデータを含めるかを定義します。 典型的な使用例: * 特定の生産ラインのみのデータを表示 * 分析から特定のマシンを除外 * 特定のしきい値より高い値を持つデータポイントのみを表示
フィルターは条件のように構成されます。条件を満たすすべてのデータが分析に含まれます。いくつかの例を見てみましょう:
- 生産ラインがAに等しい
- Production Line "フィールドに "A "を持つすべてのレコードが含まれます。
- マシンIDが "マシン1 "と等しくない
- Machine 1 "と等しくないすべての機械が含まれる。
- 試験時間 > 55
- 試験時間が55秒を超えたすべてのレコードを含める。
フィルターは2つの異なる方法で定義できます: 1.設定済みのフィルター関数をソースデータのフィールドと組み合わせて使用する 2.ブール値として評価される式を設定する。
可視化
ユニバーサルテンプレートを使用して新しい分析を作成すると、デフォルトで表の可視化が選択されます。画面上部のDisplay As設定を使用して、いつでも別の可視化タイプに切り替えることができます。Table "のほかに、以下のオプションがあります:
- バー
- 線
- 散布図
- ヒストグラム
- ドーナツ
- ゲージ
- ボックス
- 単一値
- スライドショー
- パレート
可視化の設定
ほとんどの可視化タイプでは、クエリ結果のどのフィールドをどのように可視化するかを自由に選択できます。これは、アナリティクス・エディタの右側にあるデータ・パネルで行います。初めて別の可視化に切り替える場合、設定は空です。ビジュアライゼーションの設定は、データパネルで手動で行うか、画面中央のStart with suggestionボタンをクリックしてサジェストから開始します。
可視化を設定するための前提条件は以下のとおりです:
- クエリ結果にデータがある
- ビジュアライゼーションに適したフィールドがあること。例えば、棒グラフには少なくとも 1 つの数値フィールドが必要です。
これらの両方の要件が満たされていない場合、Analytics Editorに警告メッセージが表示されます。
データパネルのオプション
以下のリストでは、さまざまな可視化タイプの設定オプションの概要を示します:
棒グラフ、折れ線グラフ、散布図
- X軸
- X軸に値を表示するフィールド。
- Y軸
- Y軸に値を表示する1つまたは複数の数値フィールド。
- 比較方法
- チャート上に同じ系列として値を表示するために使用されるフィールド。
複数の系列を表示したい場合は、Y軸に複数のフィールドを選択するか、Y軸に1つのフィールドとCompare Byのフィールドを選択する。Y軸とCompare Byに複数のフィールドを組み合わせることはできない。
これらの可視化タイプには、X軸設定の"... "メニューで "フィールド値の比較 "モードが利用できる。これにより、複数のフィールドの数値を並べて表示することができます。このオプションをオンにすると、以下のオプションが使用可能になる:
- X軸
- 比較する数値フィールド
- 比較対象
- チャート内で同じ系列として値を表示するために使用されるフィールド。
- デフォルトはデータの行インデックス。
ヒストグラム
- 値
- ヒストグラムを表示する値を含む数値フィールド。
- このフィールドには、すべての値を集約せずに格納します。ヒストグラム値の計算は可視化が行います。
- 比較対象
- Values "を複数の系列に分割し、それぞれを別々のヒストグラムとして可視化するために使用するフィールド。
ドーナツ
- 値
- 可視化される値を含む数値フィールド
- ラベル
- 異なるドーナツ・セグメントのラベルに使用されるフィールド。これらはツールチップと凡例に表示されます。
- デフォルトは可視化されたデータの行インデックスです。
単一値、ゲージ
- 値
- 可視化される値を含む数値フィールド
注意: クエリ結果の最初の行の値が視覚化されます。クエリが複数の行を返す場合は、ソートを追加して、どの値を表示するかを変更できます。ビジュアライゼーションで期待した値が表示されない場合は、下部の "Show query result" ボタンを使用してデータを確認することをお勧めします。
ボックス
- X軸
- X軸に値を表示するフィールド。
- このフィールドの各値に対して個別の「ボックス」が視覚化されます。
- Y軸
- ボックス・プロットで可視化される値を含む数値フィールドが表示されます。
- このフィールドは、集計されない方法ですべての値を含むべきです。可視化がボックス値の計算を行います。
パレート
- X軸
- X軸に値を表示するフィールド。
- Y軸
- Y 軸に値を表示する数値フィールド。
累積パーセンテージ線は、可視化で自動的に計算されます。
可視化タイプの切り替え
データパネルで設定された可視化タイプを切り替えると、互換性のある設定はすべて引き継がれます。これにより、切り替えの手間を最小限に抑え、データのさまざまな可視化オプションを簡単に試すことができます。
表とスライドショー
表とスライドショーの可視化にはデータパネルがなく、自動的に構成されます。
この表には、クエリで設定されたすべてのグループ化と操作が表示されます。これらは、左側のクエリ・ビルダーに表示される順序で並んでいます。
スライドショーは、クエリ結果の画像フィールドにあるすべての画像を個別のスライドとして表示します。クエリで設定された追加フィールドは、画像の下の表に表示されます。
お探しのものは見つかりましたか?
community.tulip.coに質問を投稿したり、他の人が同じような質問に直面していないか確認することもできます!