

Indicazioni per l'adesione a un Modello di dati comune ed esempi di come crearne uno.
Che cos'è un modello di dati comune?
Le applicazioni possono essere combinate per risolvere i casi d'uso, collegandosi tra i processi di produzione utilizzando le tabelle del Tulip Common Data Model for Discrete{target=_blank} o del Common Data Model for Pharma. A differenza dei modelli di dati tradizionali che si basano sulle dipendenze, il Common Data Model componibile di Tulip consente di aggiungere tabelle nel tempo, caso per caso.
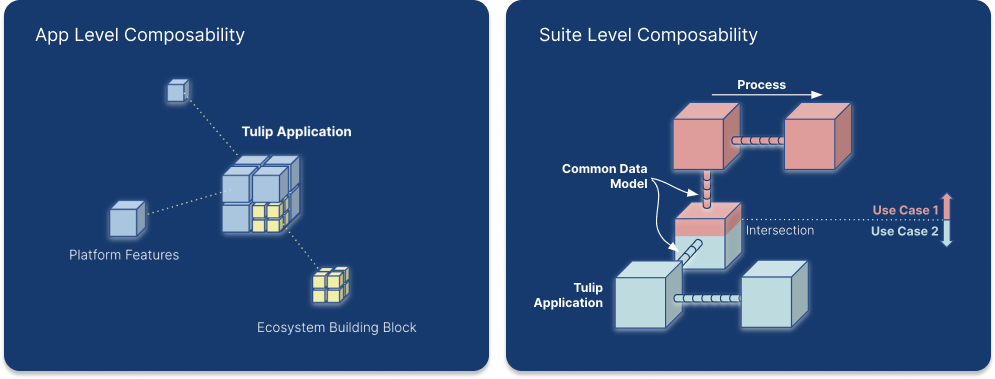
Un modello di dati comune fornisce una raccolta di schemi di dati standardizzati ed espandibili. Questi schemi predefiniti coprono vari tipi di dati, tra cui artefatti operativi, artefatti fisici, materiali di riferimento e registri di eventi. Rappresentando concetti e attività ampiamente utilizzati, come gli ordini di lavoro e le unità, questi schemi facilitano la creazione, la compilazione e l'analisi dei dati. La standardizzazione aiuta a semplificare la gestione dei dati tra i diversi sistemi.
Modello di dati comune in Composability
Le tabelle Tulip svolgono un ruolo cruciale nella gestione dei flussi di dati e nel mantenimento della connessione tra le applicazioni. Esse contengono informazioni che vengono visualizzate nelle applicazioni e le applicazioni creano, aggiornano ed eliminano i record delle tabelle. Se più applicazioni utilizzano le stesse tabelle, possono comunicare tra loro attraverso le tabelle.
Ad esempio, un manager crea un ordine di lavoro in un'applicazione e un operatore lo esegue in un'altra applicazione o in un insieme di applicazioni.
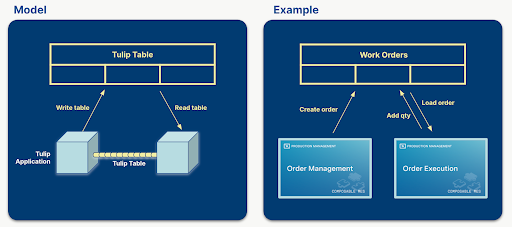
Quando si progetta una soluzione per un determinato problema, la definizione delle tabelle da utilizzare è una delle fasi più importanti. La scelta logica delle tabelle può portare a un'applicazione più semplice, riutilizzabile e componibile. Se la giusta quantità di dati viene memorizzata nelle tabelle, il costruttore di applicazioni può ridurre il numero di variabili utilizzate, rendendo l'applicazione meno complessa e facile da personalizzare. Se le applicazioni all'interno di una soluzione utilizzano lo stesso insieme di tabelle, le applicazioni diventano intercambiabili o componibili, senza dover riprogettare l'una o l'altra applicazione.
Migliori pratiche
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Le tabelle Tulip dovrebbero seguire principalmente il modello Digital Twin, ossia le tabelle dovrebbero riflettere il più rigorosamente possibile lo stabilimento fisico o l'officina. I dati storici delle applicazioni devono essere limitati ai record di completamento, assicurando che le tabelle non vengano utilizzate per memorizzare dati master o dati duplicati dai record di completamento o da record esterni.
Tipi di tabelle primarie
Idealmente, le tabelle dovrebbero rappresentare artefatti fisici e operativi.
Queste tabelle includeranno sempre un campo Stato che verrà regolarmente aggiornato dalle applicazioni.
Il diagramma seguente mostra le tabelle complete del Modello comune dei dati e quali tabelle utilizzare per i casi d'uso della produzione discreta e del settore farmaceutico.
Ecco una ripartizione di tutti i tipi di tabelle del Modello comune dei dati:
Artefatti fisici
Gliartefatti fisici sono oggetti tangibili presenti nello stabilimento o componenti che vengono utilizzati o prodotti durante le operazioni. Quando lo stato di un artefatto fisico cambia o si aggiorna, questa modifica si riflette nel record (ad esempio, cambiamento di stato).
Esistono due categorie di artefatti fisici:
1. AssetGli assetriguardano componenti che equipaggiano, contengono o eseguono un processo, come ad esempio: * Attrezzature * Bilance * Luoghi
2. MaterialiI materialiriguardano gli elementi utilizzati o creati in un processo, come ad esempio: * Articoli di inventario * Unità * Lotto
Artefatti operativi
Gliartefatti operativi sono elementi o componenti tangibili o intangibili che consentono o supportano le operazioni.
Esistono tre categorie di artefatti operativi:
1. CompitiI compiticomportano un processo attivabile, come ad esempio: * Risultati delle ispezioni * Schede Kanban
2. EventiGli eventiriguardano qualcosa che è accaduto, come ad esempio: * Difetti * Correzioni
3. OrdiniGli ordiniriguardano informazioni su beni o impegni, come ad esempio: * Ordini di lavoro * Ordini di processo
Tipi di tabella secondari (avanzati)
Ci sono casi in cui è necessario prendere in considerazione la possibilità di infrangere le best practice. Per le circostanze più avanzate, e con la massima parsimonia possibile, potrebbe essere necessario utilizzare i seguenti due tipi di tabella secondaria:
- Registro
- Riferimento
I dati in queste tabelle saranno probabilmente statici e non verranno aggiornati (per questo motivo è preferibile mantenere questi tipi di dati nei record di completamento o nel sistema esterno originale).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Registri
Iregistri degli eventi sono informazioni che possono essere consultate e definiscono qualcosa nella produzione. Si trovano spesso in sistemi esterni come un ERP. Poiché i dati storici sono tradizionalmente tracciati tramite il completamento dell'applicazione e memorizzati nei record di completamento, è necessario utilizzare una tabella Log SOLO se:* È necessario separare dati specifici dai record di completamento per scopi di visualizzazione* È necessario utilizzare questi dati in calcoli, in particolare query e aggregazioni.
Esempi:
- Note e commenti
- Registri di genealogia
- Cronologia delle attività della stazione
- Risultati delle ispezioni
Non si deve ricorrere alle tabelle di registro per:* Registrazioni storiche* Rintracciabilità
Riferimenti
Iriferimenti sono registri condivisi tra le applicazioni. È simile al concetto di record di completamento, tranne per il fatto che è condiviso tra le applicazioni e rende accessibili le query di tabella, le {{glossario.Aggregazioni}} e la mutabilità delle tabelle Tulip.
Ove possibile, i dati dovrebbero essere recuperati in tempo reale direttamente dalla fonte originale, ad esempio un ERP, tramite un connettore HTTP. Potrebbe essere necessario utilizzare una tabella di riferimento in casi marginali come:* Temporaneamente, mentre si stabilisce la connessione a un ERP.* Se il sistema esterno contiene dati di riferimento limitati che devono essere aumentati con Tulip.
Il vostro approccio si evolverà nel tempo, man mano che le soluzioni matureranno e i sistemi diventeranno più integrati e strettamente accoppiati.
Esempi:
- Definizioni dei materiali
- Distinta dei materiali
Costruire il proprio modello di dati comuni
L'esempio di Modello comune di dati di Tulip è stato concepito come punto di partenza per costruire il vostro modello di dati. Tuttavia, tutti i processi e le soluzioni sono diversi e, come le applicazioni, il modello di dati può essere personalizzato secondo le necessità.
Le modifiche più piccole comprendono l'aggiunta e la rimozione di campi dalle tabelle. In alcuni casi (processi speciali, più tabelle necessarie per lo stesso caso d'uso) sono necessarie modifiche importanti. Questo può essere fatto sostituendo una o più tabelle dal modello di dati scaricato o inserendo tabelle aggiuntive.
Pianificare un modello di dati comune
- Definire gli artefatti fisici e operativi del vostro processo.
- Trovare le rispettive tabelle per ogni artefatto
- Esplorare i tipi di dati che devono essere raccolti dalle applicazioni e i riferimenti che devono essere utilizzati.