Learn how to optimally store and manage data within Tulip.
Much like apps, data in Tulip should work together as a system. Keeping data easily accessible to inform people and other systems increases visibility and avoids duplicating data in multiple places.
Best Practices
Here are a few principles you should follow when planning out a data structure for your applications:
Adopt a Digital Twin Structure for Tables
A digital twin is a dynamic, virtual representation or model of a part, object, machine, or even an entire production process. It consists of the physical item itself, the virtual representation of the item, and the connective functionality that allows data to pass back and forth between the physical and virtual object.
Tulip Tables should mirror what’s on your shop floor as 1:1 as possible.
Organize Tables by Information
It’s best to identify types of tables and define them. Understanding what information goes into which tables is especially crucial when designing a solution.
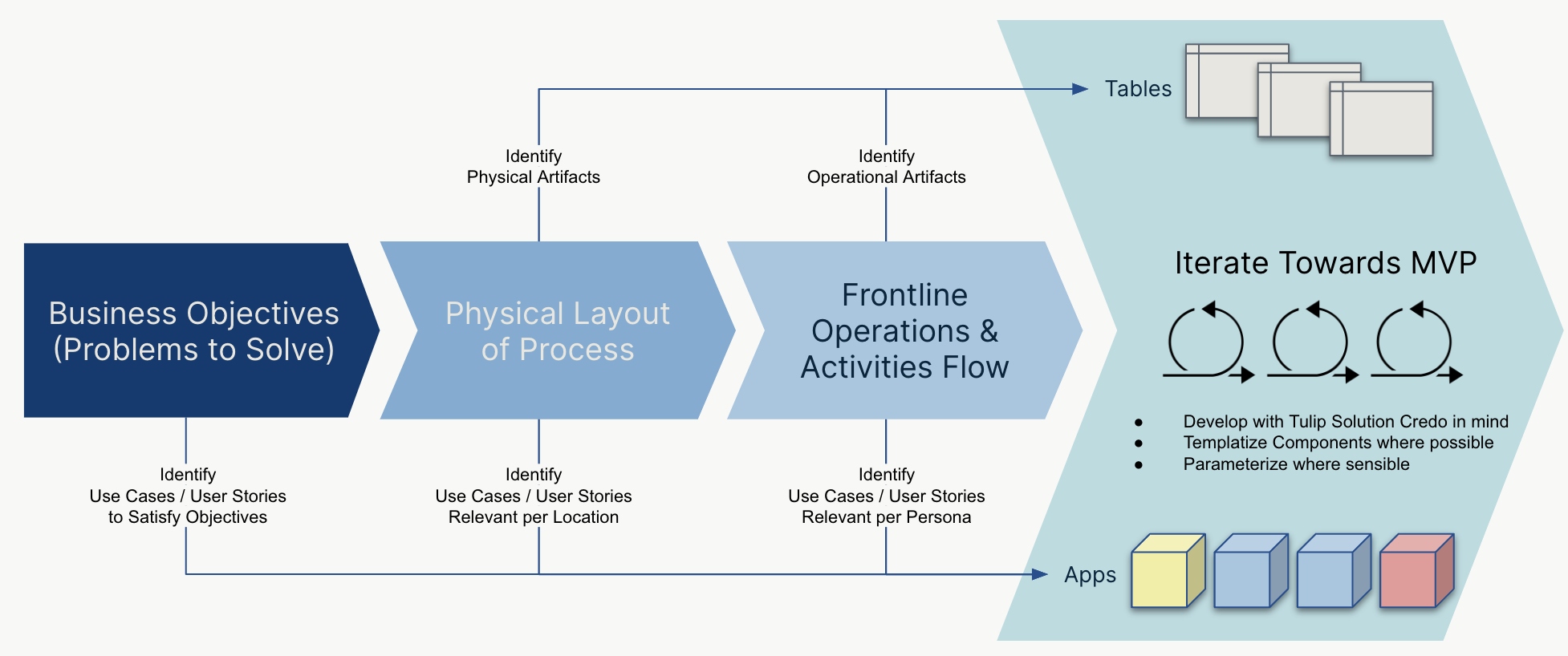
For example, the tables in Tulip’s example common data model are broken down into two categories:
| Category | Description | Examples |
|---|---|---|
| Physical artifact | This is something tangible that you can physically touch on your shop floor | Inventory Item, Equipment & Assets |
| Operational artifacts | This is a uniquely identified, intangible element that can be commonly found related to operations. These are often found as printed travelers or tickets. | Kanban Card, Work Order |
It’s important to remember that tables should avoid duplicating external data.
Table Structure and Set Up
Tables and fields should be simple and have a clear purpose for what information they store. By using the previously discussed table types (physical artifacts and operational artifacts), you can narrowly define each table's purpose.
Fields for each table are dependent on the information relevant to artifacts. A good rule of thumb is that most tables should contain a status (or similar) field.
Other common fields you may add include:
- Material
- Location/Bin
- IDs (work order, material, customer, etc.)
- Measurements
- Start, request, or completed dates
- Comments
- Photo
For any data that you want to use in calculations, create a query or aggregation. Calculations that inform goals and KPIs will allow you to obtain a snapshot of current operations.
Naming Conventions
Consider that the Table Names and Column Names you use may be seen by other Citizen Developers and by Operators in Tulip Analytics, so be sure to use intuitive human-centric names for Tables and table Columns, rather than using a naming conventions typically used by software engineers. I.e., give a table a name like ‘Equipment and Tools’ rather than ‘eqps_tools’, and use column names like ‘Equipment Type’ rather than ‘eqpType’.
Learn more about Best Practices for Naming Elements in Tulip.
Table optimization for scalability and performance
The article linked above discusses the fundamentals of implementing and maintaining a Tulip table model that is: performant, reliable, composable, and scalable.
When to Use Completion Records
A Completion Record is created either completing an app via a Transition like App / Complete App or by the trigger action Save All App Data.
Historical data is traditionally tracked via App Completion and stored to Completion Records, which are local to each app.
If you only need to store data for the purpose of process history and/or to make analyses on that data via Analytics, then Completion Records are likely sufficient and the easiest way to save this data.
Learn more about Completion Records.
Consider a Common Data Model
A common data model enables composability, a key factor for being successful with Tulip. As you build out an app suite, it's important to also have a data model as a base to "connect" the apps with reusable data.
Learn more about using a common data model.
You can also start out with the Tulip Commmon Data Model, which you can then adjust to your needs.
.gif)