

Útmutató a közös adatmodell betartásához és példák a modell létrehozására.
Mi az a közös adatmodell?
Az alkalmazások kombinálhatók a felhasználási esetek megoldására, a gyártási folyamatokat összekapcsolva a Tulip Common Data Model for Discrete{target=_blank} vagy Common Data Model for Pharma táblák segítségével. A hagyományos adatmodellekkel ellentétben, amelyek függőségekre támaszkodnak, a Tulip összeállítható közös adatmodellje lehetővé teszi, hogy a táblákat idővel, eseti alapon hozzá lehessen adni.
A Közös adatmodell szabványosított és bővíthető adatsémák gyűjteményét biztosítja. Ezek az előre definiált sémák különböző adattípusokat fednek le, beleértve az operatív műtárgyakat, a fizikai műtárgyakat, a referenciaanyagokat és az eseménynaplókat. A széles körben használt fogalmak és tevékenységek, mint például a munkautasítások és az egységek ábrázolásával ezek a sémák megkönnyítik az adatok létrehozását, összeállítását és elemzését. Ez a szabványosítás segít a különböző rendszerekben történő adatkezelés racionalizálásában.
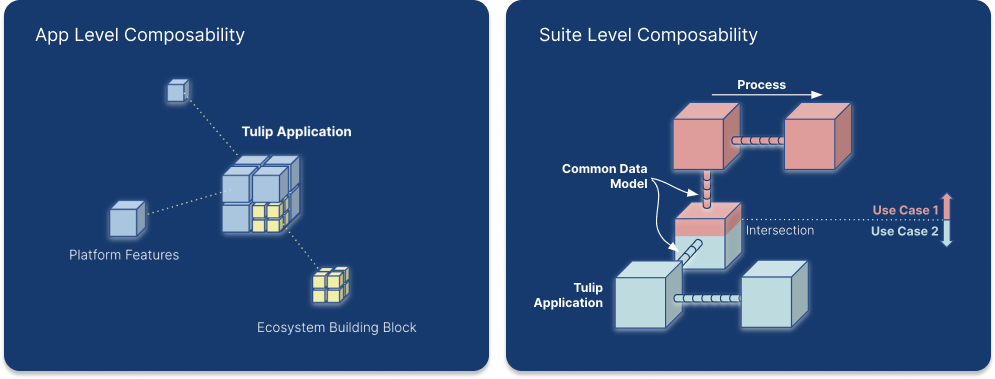
Közös adatmodell az összeállíthatóságban
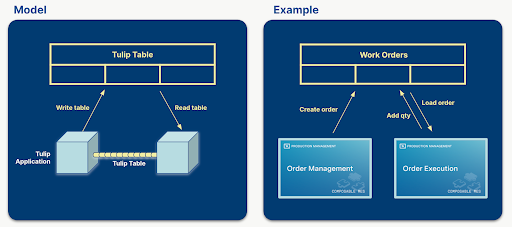
A Tulip Tables döntő szerepet játszanak az adatfolyamok kezelésében és az alkalmazások közötti kapcsolat fenntartásában. Olyan információkat tartalmaznak, amelyek az alkalmazásokban megjelennek, és az alkalmazások létrehozzák, frissítik és törlik a Táblaleveleket. Ha több alkalmazás használja ugyanazokat a táblákat, akkor azok a táblákon keresztül kommunikálhatnak egymással.
Például egy menedzser létrehoz egy munkamegrendelést egy alkalmazásban, és egy operátor végrehajtja ezt a munkamegrendelést egy másik alkalmazásban vagy alkalmazások egy csoportjában.
Egy adott probléma megoldásának megtervezésekor az egyik legfontosabb lépés a használni kívánt táblázatok meghatározása. A táblázatok logikus kiválasztása egyszerűbb, újrafelhasználhatóbb és összetehetőbb alkalmazásokat eredményezhet. Ha a megfelelő mennyiségű adatot táblázatokban tároljuk, az alkalmazáskészítő csökkentheti a használt alkalmazásváltozók számát, így az alkalmazás kevésbé lesz összetett és könnyen testreszabható. Ha a megoldáson belüli alkalmazások ugyanazt a táblázatkészletet használják, az alkalmazások felcserélhetővé vagy összeállíthatóvá válnak, anélkül, hogy az egyik vagy a másik alkalmazást újra kellene tervezni.
Legjobb gyakorlatok
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
A Tulip táblázatoknak elsősorban a Digital Twin modellt kell követniük, vagyis a táblázatoknak a lehető legszigorúbban kell tükrözniük a fizikai üzemet vagy az üzlethelyiséget. Az alkalmazás történeti adatait a Teljesítési rekordokra kell korlátozni, biztosítva, hogy a táblákat ne használják törzsadatok vagy a Teljesítési rekordok vagy külső rekordok duplikált adatainak tárolására.
Elsődleges táblatípusok
Ideális esetben a tábláknak fizikai és működési műtárgyakat kell ábrázolniuk.
Ezek a táblák mindig tartalmaznak egy Status mezőt, amelyet az alkalmazások rendszeresen frissítenek.
Az alábbi ábra mutatja a Közös adatmodell teljes tábláit, valamint azt, hogy mely táblákat érdemes használni a diszkrét gyártási és gyógyszeripari felhasználási esetekhez.
Itt látható a Közös adatmodell összes táblázattípusának bontása:
Fizikai tárgyak
A fizikai tárgyak a létesítményében lévő kézzelfogható tárgyak vagy alkatrészek, amelyeket a műveletek során használnak vagy gyártanak. Amikor egy fizikai tárgy állapota megváltozik vagy frissül, ez a változás megjelenik a rekordban (pl. állapotváltozás).
A fizikai műtárgyaknak két kategóriája van:
1. EszközökAz eszközökolyan komponenseket foglalnak magukban, amelyek felszerelnek, tartalmaznak vagy teljesítenek egy folyamat során, mint például: * felszerelések * mérlegek * helyszínek
2. AnyagokAz anyagoka folyamat során használt vagy létrehozott tárgyakat foglalják magukban, mint például: - A tárgyak a folyamat során használt vagy létrehozott tárgyakat foglalják magukban: * Leltári tételek * egységek * tételek
Működési tárgyak
Az operatív műtárgyak olyan tárgyi vagy immateriális elemek vagy összetevők, amelyek lehetővé teszik vagy támogatják a műveleteket.
Az operatív műtárgyaknak három kategóriája van:
1. FeladatokA feladatokegy cselekvésre alkalmas folyamatot foglalnak magukban, mint például: * Kanban-kártyák
2. EseményekAz eseményekvalami olyasmit tartalmaznak, ami megtörtént, mint például: * Hibák * Javítások
3. MegrendelésekA megrendelésekaz árukra vagy megbízásokra vonatkozó információkat tartalmaznak, mint például: * Munka megrendelések * Folyamat megrendelések
Másodlagos (speciális) táblázattípusok
Vannak esetek, amikor meg kell fontolnia a legjobb gyakorlatok megszegését. Haladóbb körülmények között - és a lehető legritkábban - szükség lehet a következő két másodlagos táblatípus használatára:
- Napló
- Hivatkozás
Az ezekben a táblákban szereplő adatok valószínűleg statikusak lesznek, és nem frissülnek (ezért előnyösebb, ha az ilyen típusú adatokat vagy a kitöltési rekordokban, vagy az eredeti, külső rendszerben tartjuk).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Naplók
Az eseménynaplók olyan információk, amelyeket meg lehet keresni, és amelyek meghatároznak valamit a termelésben. Ezek gyakran külső rendszerekben, például egy ERP-ben találhatók. Mivel a múltbeli adatok nyomon követése hagyományosan az alkalmazás kitöltésén keresztül történik, és a kitöltési rekordokba tárolják, CSAK akkor van szüksége naplótábla használatára, ha:* Bizonyos adatokat kell elkülönítenie a kitöltési rekordoktól vizualizációs célokra* Ezeket az adatokat számításokban, különösen lekérdezésekben és aggregációkban kell felhasználnia.
Példák:
- Megjegyzések és megjegyzések
- Genealógiai rekordok
- Állomás tevékenységtörténete
- Ellenőrzési eredmények
A naplótáblákhoz NEM szabad fordulni:* Történelmi feljegyzések* Nyomonkövethetőség
Hivatkozások
Ahivatkozások az alkalmazások között megosztott főkönyvek. Ez hasonló a befejezési rekord fogalmához, azzal a különbséggel, hogy az alkalmazások között megosztott, és hozzáférhetővé teszi a Táblázati lekérdezéseket, az Aggregations és a Tulip Tables változtathatóságát.
Ahol csak lehetséges, az adatokat valós időben, közvetlenül az eredeti forrásból - például egy ERP-ből - kell lekérni egy HTTP-konnektoron keresztül. A referencia-tábla használatára olyan peremes esetekben lehet szükség, mint például:* Átmenetileg, az ERP-vel való kapcsolat létrehozása során.* Ha a külső rendszer korlátozott mennyiségű referenciaadatot tartalmaz, amelyet ki kell egészíteni a Tulip.
Az Ön megközelítése idővel fejlődni fog, ahogy a megoldások kiforrottá válnak, és a rendszerek egyre integráltabbá és szorosabban összekapcsolódnak.
Példák:
- Anyagdefiníciók
- Anyagjegyzék
Saját közös adatmodell létrehozása
A Tulip közös adatmodelljének példája kiindulópontként szolgál a saját adatmodelljének felépítéséhez. Azonban minden folyamat és megoldás más és más, és az alkalmazásokhoz hasonlóan az adatmodell is szükség szerint testre szabható.
A kisebb változtatások közé tartozik a táblázatok mezőinek hozzáadása és eltávolítása. Egyes esetekben (speciális folyamatok, ugyanazon felhasználási esethez szükséges több táblázat) nagyobb változtatásokra van szükség. Ez a letöltött adatmodellből egy vagy több tábla helyettesítésével vagy további táblák beillesztésével történhet.
Közös adatmodell tervezése
- Határozza meg a folyamat fizikai és működési artefaktumait.
- Keresse meg az egyes artefaktumokhoz tartozó táblákat
- Fedezze fel az alkalmazások által összegyűjtendő adattípusokat és a használandó hivatkozásokat