

Conseils pour adhérer à un modèle de données commun et exemples de création d'un tel modèle.
Qu'est-ce qu'un modèle de données commun ?
Les applications peuvent être combinées pour résoudre les cas d'utilisation, en se connectant à travers les processus de fabrication en utilisant les tables du Modèle de Données Commun de Tulip pour Discrete{target=_blank} ou du Modèle de Données Commun pour Pharma. Contrairement aux modèles de données traditionnels qui reposent sur des dépendances, le modèle de données commun composable de Tulip permet d'ajouter des tables au fil du temps, au cas par cas.
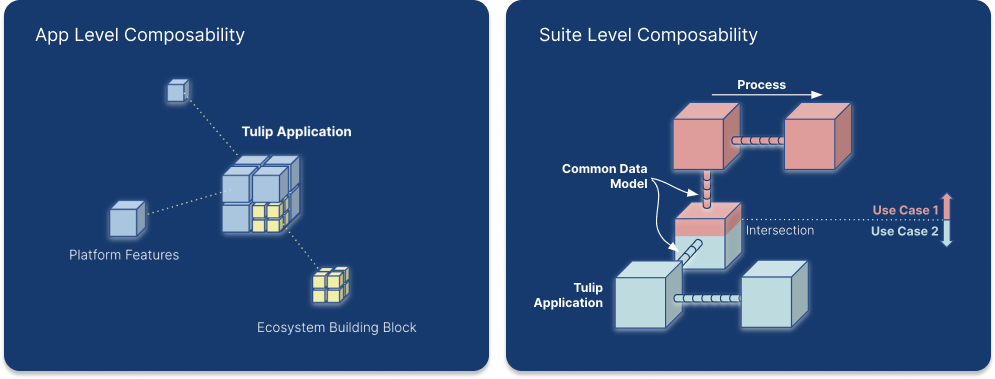
Un modèle de données commun fournit une collection de schémas de données standardisés et extensibles. Ces schémas prédéfinis couvrent différents types de données, y compris les artefacts opérationnels, les artefacts physiques, les matériaux de référence et les journaux d'événements. En représentant des concepts et des activités largement utilisés, tels que les ordres de travail et les unités, ces schémas facilitent la création, la compilation et l'analyse des données. Cette normalisation permet de rationaliser le traitement des données dans les différents systèmes.
Modèle de données commun dans la composabilité
Les tables Tulip jouent un rôle crucial dans la gestion des flux de données et le maintien de la connexion entre les applications. Elles contiennent des informations qui sont affichées dans les applications et les applications créent, mettent à jour et suppriment des enregistrements de table. Si plusieurs applications utilisent les mêmes tables, elles peuvent communiquer entre elles par l'intermédiaire des tables.
Par exemple, un gestionnaire crée un ordre de travail dans une application et un opérateur exécute cet ordre de travail dans une autre application ou un autre ensemble d'applications.
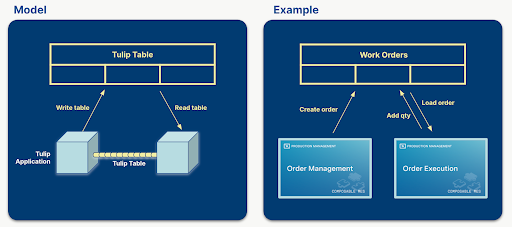
Lors de la conception d'une solution à un problème donné, la définition des tables qui seront utilisées est l'une des étapes les plus importantes. Un choix logique des tables peut aboutir à des applications plus simples, plus réutilisables et plus composables. Si la bonne quantité de données est stockée dans les tables, l'app builder peut réduire le nombre de variables utilisées, ce qui rend l'application moins complexe et plus facile à personnaliser. Si les applications d'une solution utilisent le même ensemble de tables, elles deviennent interchangeables ou composables, sans qu'il soit nécessaire de revoir la conception de l'une ou l'autre application.
Meilleures pratiques
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Les tables Tulip devraient principalement suivre le modèle Digital Twin, ce qui signifie que les tables devraient refléter l'usine physique ou l'atelier aussi strictement que possible. Les données historiques de l'application doivent être limitées aux enregistrements d'achèvement, en veillant à ce que les tables ne soient pas utilisées pour stocker des données de base ou des données dupliquées à partir d'enregistrements d'achèvement ou d'enregistrements externes.
Types de tables primaires
Idéalement, les tables doivent représenter des artefacts physiques et opérationnels.
Ces tables comprendront toujours un champ Statut qui sera régulièrement mis à jour par les applications.
Le diagramme ci-dessous montre l'ensemble des tables du modèle de données commun et les tables à utiliser pour les cas d'utilisation de la fabrication discrète et de l'industrie pharmaceutique.
Voici une ventilation de tous les types de tables dans le modèle de données commun :
Artéfacts physiques
Lesartefacts physiques sont des objets tangibles de votre installation ou des composants utilisés ou produits pendant les opérations. Lorsque l'état d'un artefact physique change ou est mis à jour, ce changement est reflété dans l'enregistrement (par exemple, changement d'état).
Il existe deux catégories d'artefacts physiques :
1. ActifsLes actifssont des composants qui équipent, contiennent ou interviennent dans un processus, tels que : * Équipements * Balances * Emplacements
2. MatériauxLes matériauxcomprennent les éléments utilisés ou créés dans le cadre d'un processus, tels que : * Articles d'inventaire * Unités * Lots
Artefacts opérationnels
Les artefactsopérationnels sont des éléments ou des composants tangibles ou intangibles qui permettent ou soutiennent les opérations.
Il existe trois catégories d'artefacts opérationnels :
1. TâchesLes tâchesimpliquent un processus actionnable, tel que : * Résultats d'inspection * Cartes Kanban
2. ÉvénementsLes événementsimpliquent quelque chose qui s'est produit, comme par exemple : * Défauts * Corrections
3. CommandesLes commandesimpliquent des informations sur des biens ou des engagements, telles que : * Ordres de travail * Ordres de traitement
Types de tables secondaires (avancées)
Il peut arriver que vous deviez envisager de déroger aux meilleures pratiques. Dans des circonstances plus avancées, et aussi rarement que possible, vous pouvez avoir besoin d'utiliser les deux types de tables secondaires suivants :
- Journal
- Référence
Les données de ces tables seront probablement statiques et ne seront pas mises à jour (c'est pourquoi il est préférable de conserver ces types de données dans les enregistrements d'achèvement ou dans le système externe d'origine).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Journaux
Lesjournaux d'événements sont des informations qui peuvent être consultées et qui définissent quelque chose dans la production. Ils se trouvent souvent dans des systèmes externes tels qu'un ERP. Étant donné que les données historiques sont traditionnellement suivies via l'achèvement de l'application et stockées dans les enregistrements d'achèvement, vous ne devez utiliser une table Log que si:* Vous devez séparer des données spécifiques des enregistrements d'achèvement à des fins de visualisation* Vous devez utiliser ces données dans des calculs, en particulier dans des requêtes et des agrégations.
Exemples :
- Notes et commentaires
- Enregistrements de généalogie
- Historique de l'activité de la station
- Résultats d'inspection
Vous ne devez PAS utiliser les tableaux de bord pour:* les enregistrements historiques* la traçabilité
Références
Lesréférences sont des registres partagés entre les applications. Ce concept est similaire à celui d'un enregistrement d'achèvement, sauf qu'il est partagé entre les applications et rend accessibles les requêtes de table, les Aggregation et la mutabilité des tables Tulip.
Dans la mesure du possible, les données doivent être récupérées en temps réel directement à partir de la source d'origine - telle qu'un ERP - par le biais d'un connecteur HTTP. Vous pouvez avoir besoin d'utiliser une table de référence dans des cas marginaux tels que:* Temporairement, en établissant une connexion à un ERP.* Si votre système externe contient des données de référence limitées qui doivent être augmentées avec Tulip.
Votre approche évoluera avec le temps, au fur et à mesure que les solutions mûriront et que les systèmes deviendront plus intégrés et étroitement couplés.
Exemples :
- Définitions des matériaux
- Nomenclature des matériaux
Construisez votre propre Modèle de Données Commun
L'exemple de modèle de données commun de Tulip est conçu comme un point de départ pour construire votre modèle de données. Cependant, tous les processus et solutions sont différents et, comme les applications, le modèle de données peut être personnalisé selon les besoins.
Les modifications mineures consistent à ajouter ou à supprimer des champs dans les tables. Dans certains cas (processus spéciaux, plusieurs tables nécessaires pour le même cas d'utilisation), des changements majeurs sont nécessaires. Pour ce faire, on peut remplacer une ou plusieurs tables du modèle de données téléchargé ou insérer des tables supplémentaires.
Planifier un modèle de données commun
- Définissez les artefacts physiques et opérationnels de votre processus.
- Trouver les tables respectives pour chaque artefact
- Explorer les types de données à collecter par les applications et les références à utiliser.
Pour en savoir plus
- Stockage des données
- Tables Tulip communes
- Meilleures pratiques pour le stockage des données dans Tulip