

Orientação para aderir a um modelo de dados comum e exemplos de como criar um.
O que é um modelo de dados comum?
As aplicações podem ser combinadas para solucionar casos de uso, conectando-se aos processos de manufatura por meio de tabelas no Tulip Common Data Model for Discrete{target=_blank} ou Common Data Model for Pharma. Ao contrário dos modelos de dados tradicionais que dependem de dependências, o Common Data Model da Tulip permite que as tabelas sejam adicionadas ao longo do tempo, caso a caso.
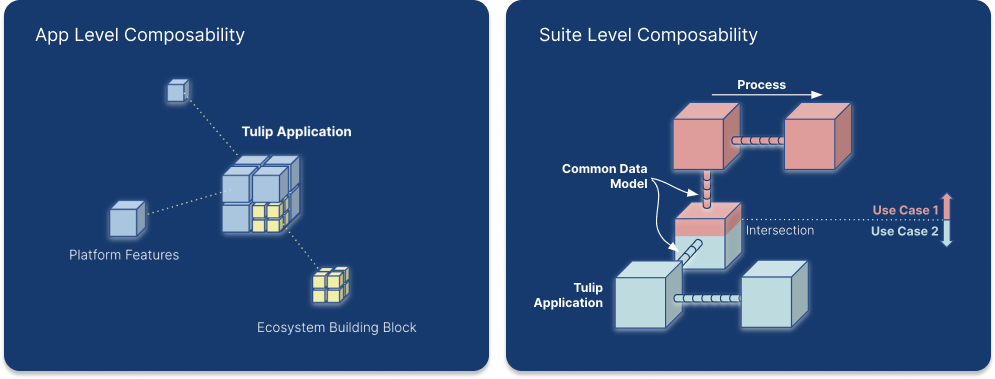
Um modelo de dados comum oferece uma coleção de esquemas de dados padronizados e expansíveis. Esses esquemas predefinidos abrangem vários tipos de dados, incluindo artefatos operacionais, artefatos físicos, materiais de referência e registros de eventos. Ao representar conceitos e atividades amplamente utilizados, como ordens de serviço e unidades, esses esquemas facilitam a criação, a compilação e a análise de dados. Essa padronização ajuda a simplificar o manuseio de dados em diferentes sistemas.
Modelo de dados comum na capacidade de composição
As tabelas Tulip desempenham um papel fundamental no tratamento de fluxos de dados e na manutenção da conexão entre aplicativos. Elas contêm informações que são exibidas nos aplicativos e os aplicativos criam, atualizam e excluem registros de tabela. Se vários aplicativos estiverem usando as mesmas tabelas, eles poderão se comunicar entre si por meio de tabelas.
Por exemplo, um gerente cria uma ordem de serviço em um aplicativo e um operador executa essa ordem de serviço em outro aplicativo ou conjunto de aplicativos.
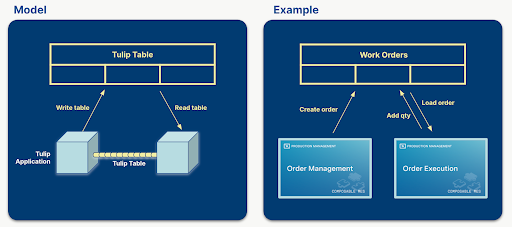
Ao projetar uma solução para um determinado problema, definir as tabelas que serão usadas é uma das etapas mais importantes. A escolha lógica das tabelas pode resultar em aplicativos mais simples, reutilizáveis e compostáveis. Se a quantidade certa de dados for armazenada em tabelas, o construtor de aplicativos poderá reduzir o número de variáveis de aplicativos usadas, tornando o aplicativo menos complexo e fácil de personalizar. Se os aplicativos de uma solução estiverem usando o mesmo conjunto de tabelas, os aplicativos se tornarão intercambiáveis ou compostáveis, sem a necessidade de reprojetar um ou outro aplicativo.
Práticas recomendadas
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
As tabelas Tulip devem seguir principalmente o modelo Digital Twin, o que significa que as tabelas devem refletir a planta física ou o chão de fábrica o mais estritamente possível. Os dados históricos do aplicativo devem ser confinados aos registros de conclusão, garantindo que as tabelas não sejam usadas para armazenar dados mestre ou dados duplicados de registros de conclusão ou registros externos.
Tipos de tabelas primárias
Idealmente, as tabelas devem representar artefatos físicos e operacionais.
Essas tabelas sempre incluirão um campo Status que será atualizado regularmente pelos aplicativos.
O diagrama abaixo mostra as tabelas completas no Common Data Model e quais tabelas devem ser usadas para casos de uso de manufatura discreta e farmacêutica.
Aqui está um detalhamento de todos os tipos de tabelas no Common Data Model:
Artefatos físicos
Os artefatos físicos são objetos tangíveis em suas instalações ou componentes que são usados ou produzidos durante as operações. Quando o estado de um artefato físico é alterado ou atualizado, essa alteração é refletida no registro (por exemplo, alteração de status).
Há duas categorias de artefatos físicos:
1. AtivosOs ativosenvolvem componentes que equipam, contêm ou atuam em um processo, como: * Equipamentos * Balanças * Locais
2. MateriaisOs materiaisenvolvem os itens usados ou criados em um processo, como: * Itens de estoque * Unidades * Lotes
Artefatos operacionais
Os artefatos operacionais são elementos ou componentes tangíveis ou intangíveis que permitem ou dão suporte às operações.
Há três categorias de artefatos operacionais:
1. TarefasAs tarefasenvolvem um processo acionável, como: * Resultados de inspeção * Cartões Kanban
2. EventosOs eventosenvolvem algo que aconteceu, como: * Defeitos * Correções
3. PedidosOrdensenvolvem informações sobre mercadorias ou compromissos, como: * Ordens de trabalho * Ordens de processo
Tipos de tabelas secundárias (avançadas)
Há ocasiões em que você pode precisar considerar a quebra das práticas recomendadas. Em circunstâncias mais avançadas - e com o mínimo de parcimônia possível -, talvez você precise usar os dois tipos de tabela secundária a seguir:
- Registro
- Referência
Os dados nessas tabelas provavelmente serão estáticos e não serão atualizados (por isso é preferível manter esses tipos de dados em registros de conclusão ou no sistema externo original).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Registros
Os registros de eventos são informações que podem ser pesquisadas e definem algo na produção. Eles geralmente são encontrados em sistemas externos, como um ERP. Como os dados históricos são tradicionalmente rastreados por meio da conclusão do aplicativo e armazenados em registros de conclusão, só será necessário usar uma tabela de logs se:* Você precisar separar dados específicos dos registros de conclusão para fins de visualização* Você precisar usar esses dados em cálculos, especificamente consultas e agregações
Exemplos:
- Notas e comentários
- Registros de genealogia
- Histórico de atividades da estação
- Resultados de inspeção
NÃO se deve recorrer a tabelas de registro para:* Registros históricos* Rastreabilidade
Referências
As referências são registros compartilhados entre aplicativos. Isso é semelhante ao conceito de um registro de conclusão, exceto pelo fato de ser compartilhado entre aplicativos e tornar acessíveis as consultas de tabela, Aggregations e a mutabilidade das tabelas Tulip.
Sempre que possível, os dados devem ser obtidos em tempo real diretamente da fonte original - como um ERP - por meio de um conector HTTP. Talvez seja necessário usar uma tabela de referência em casos excepcionais, tais como:* Temporariamente, ao estabelecer conexão com um ERP;* Se o seu sistema externo contiver dados de referência limitados que precisem ser aumentados com o Tulip.
Sua abordagem evoluirá com o tempo, à medida que as soluções amadurecerem e os sistemas se tornarem mais integrados e fortemente acoplados.
Exemplos:
- Definições de materiais
- Lista de materiais
Crie seu próprio modelo de dados comuns
O exemplo de modelo de dados comum da Tulip foi projetado para ser um ponto de partida para a criação de seu modelo de dados. No entanto, todos os processos e soluções são diferentes e, assim como os aplicativos, o modelo de dados pode ser personalizado conforme necessário.
Pequenas alterações incluem adicionar e remover campos das tabelas. Em alguns casos (processos especiais, várias tabelas necessárias para o mesmo caso de uso), são necessárias grandes alterações. Isso pode ser feito substituindo uma ou mais tabelas do modelo de dados baixado ou inserindo tabelas adicionais.
Planeje um modelo de dados comum
- Defina os artefatos físicos e operacionais do seu processo
- Encontre as respectivas tabelas para cada artefato
- Explore os tipos de dados a serem coletados pelos aplicativos e as referências que precisam ser usadas
Leitura adicional
- Armazenamento de dados
- Tabelas comuns do Tulip
- Práticas recomendadas para armazenamento de dados no Tulip