

Dowiedz się, jak strukturyzować dane wyjściowe konektorów HTTP.
Przegląd
Edytor funkcji konektorów w aplikacji Tulip umożliwia strukturyzowanie danych zwracanych przez funkcje konektorów, tak aby były one użyteczne i możliwe do wykorzystania w aplikacjach. W tym artykule omówimy podstawy formatowania funkcji konektora Output poprzez wprowadzenie do:
- Pojęcie konektora "Output"
- Narzędzia dostępne do formatowania danych wyjściowych
- Różne popularne formaty wyjściowe
Czym są dane wyjściowe?
Dane wyjściowe służą do definiowania i strukturyzowania wyników zwracanych przez funkcję konektora. Są one sposobem na wyodrębnienie informacji, które są ważne dla aplikacji z większego ciała zwrotnego HTTP.
Jak ustrukturyzować dane wyjściowe
Znajdź sekcję Dane wyjściowe w lewym dolnym rogu edytora funkcji konektora.
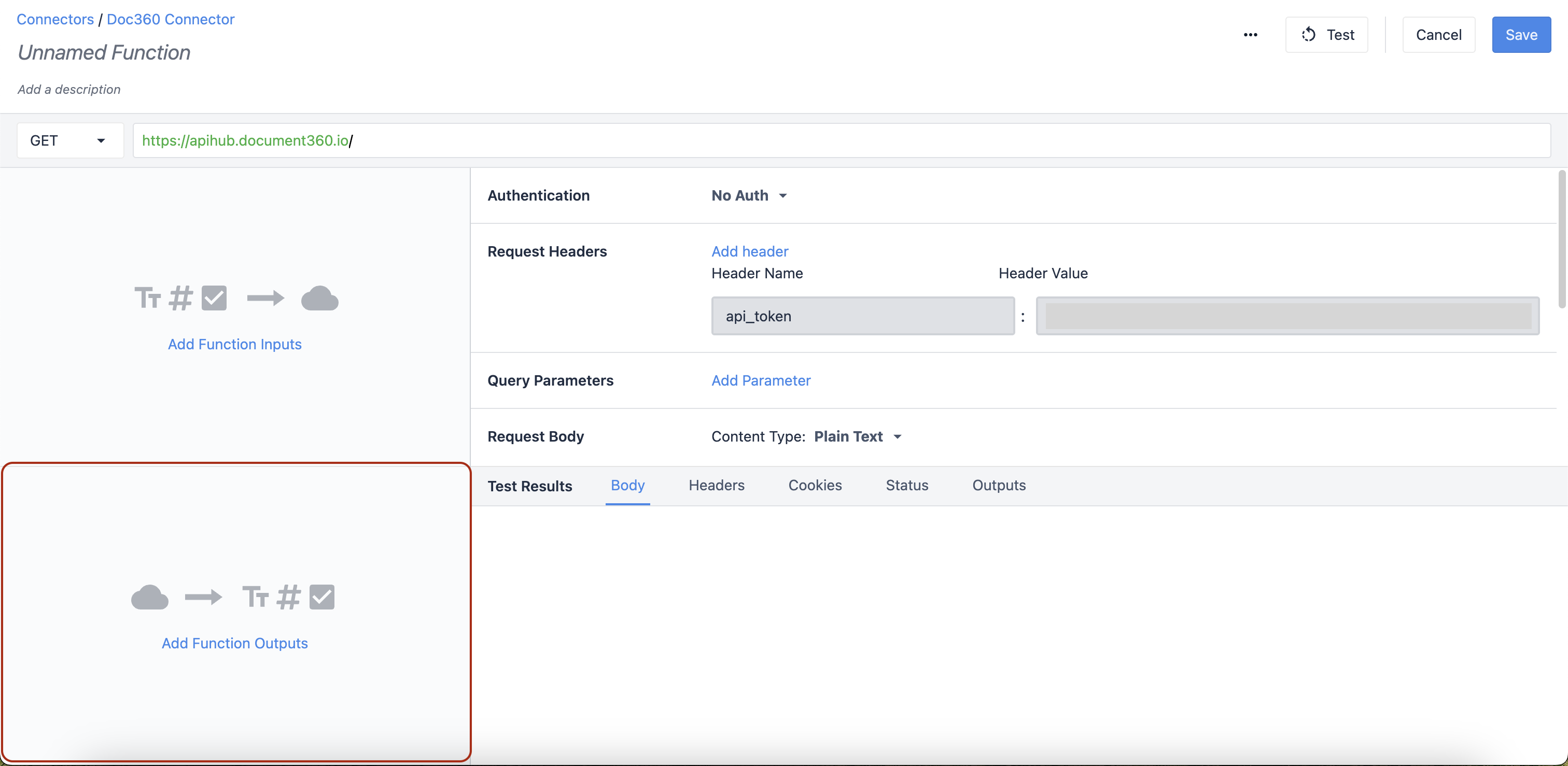
Aby rozpocząć dodawanie danych wyjściowych, kliknij przycisk Add Function Outputs.
Dobrą praktyką jest nadawanie wyjściom etykiet, które można zidentyfikować. Nazwy te pojawiają się jako zmienne w aplikacjach, więc ważne jest, aby móc je rozróżnić.

Aby zrozumieć wyniki żądania HTTP, ważne jest, aby najpierw zrozumieć kształt obiektu zwracanego w wynikach testu. Poniższy diagram ilustruje, w jaki sposób wyniki są podzielone na sekcje obiektów i tablic.
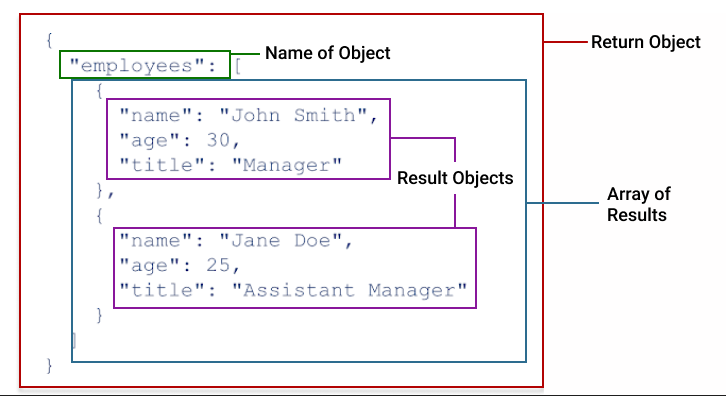
If you haven’t worked with JSON before, you may be unfamiliar with two critical datatypes, objects and arrays. Arrays are lists of values of the same type. For example, [1,2,3,5], or [oak, elm, alder, hickory]. Values in arrays are contained within square brackets, [ ]. Objects are a datatype for holding key:value pairs. The key:value pairs within an object can be of multiple different types, including arrays and nested objects. Objects are contained with curly brackets, { }.
Więcej informacji na temat obiektów i tablic można znaleźć w artykule Understanding Arrays and Objects in Connector Function Outputs.
Notacja kropkowa
W przypadku konektorów HTTP dane wyjściowe używają formatu o nazwie Dot Notation. Notacja kropkowa umożliwia dostęp do wartości wewnątrz obiektu. Notacja kropkowa jest przydatna do wyciągania tylko tego, czego potrzebujesz z dużej treści odpowiedzi JSON i zapewnia większą elastyczność w tworzeniu funkcji konektorów HTTP. Mówiąc prościej: jest to ustrukturyzowany format oparty na wartościach zagnieżdżonych jedna w drugiej.
Przeanalizujmy na przykładzie, w jaki sposób notacja kropkowa jest używana w wyjściach konektorów.
Poniższy przykładowy obiekt o nazwie "employees" zawiera tablicę obiektów ze szczegółowymi informacjami o każdym pracowniku. Gdybyśmy chcieli uzyskać dostęp tylko do tytułu każdego pracownika, użylibyśmy składni: employees.title. Używamy kropki, aby uzyskać dostęp do wartości powiązanych z kluczami, które nas interesują. Powiedzmy, że chcemy uzyskać tylko pierwszy wynik. Określilibyśmy to, dodając pozycję indeksu między nazwą głównego obiektu, "employees", a interesującą nas wartością, "title". Składnia wyglądałaby następująco: employees.0.title. W przypadku bardziej złożonych obiektów może być konieczne zagłębienie się w obiekt, aby uzyskać potrzebne informacje.

Pójdźmy o krok dalej z innym przykładem. W tym przypadku powiedzmy, że jesteśmy zainteresowani stworzeniem funkcji konektora do pobierania informacji powiązanych z artykułami w Bazie Wiedzy. Nasz konektor zwraca następujący obiekt JSON o nazwie "data" zawierający dane o konkretnym artykule:
 {height="" width=""}.
{height="" width=""}.
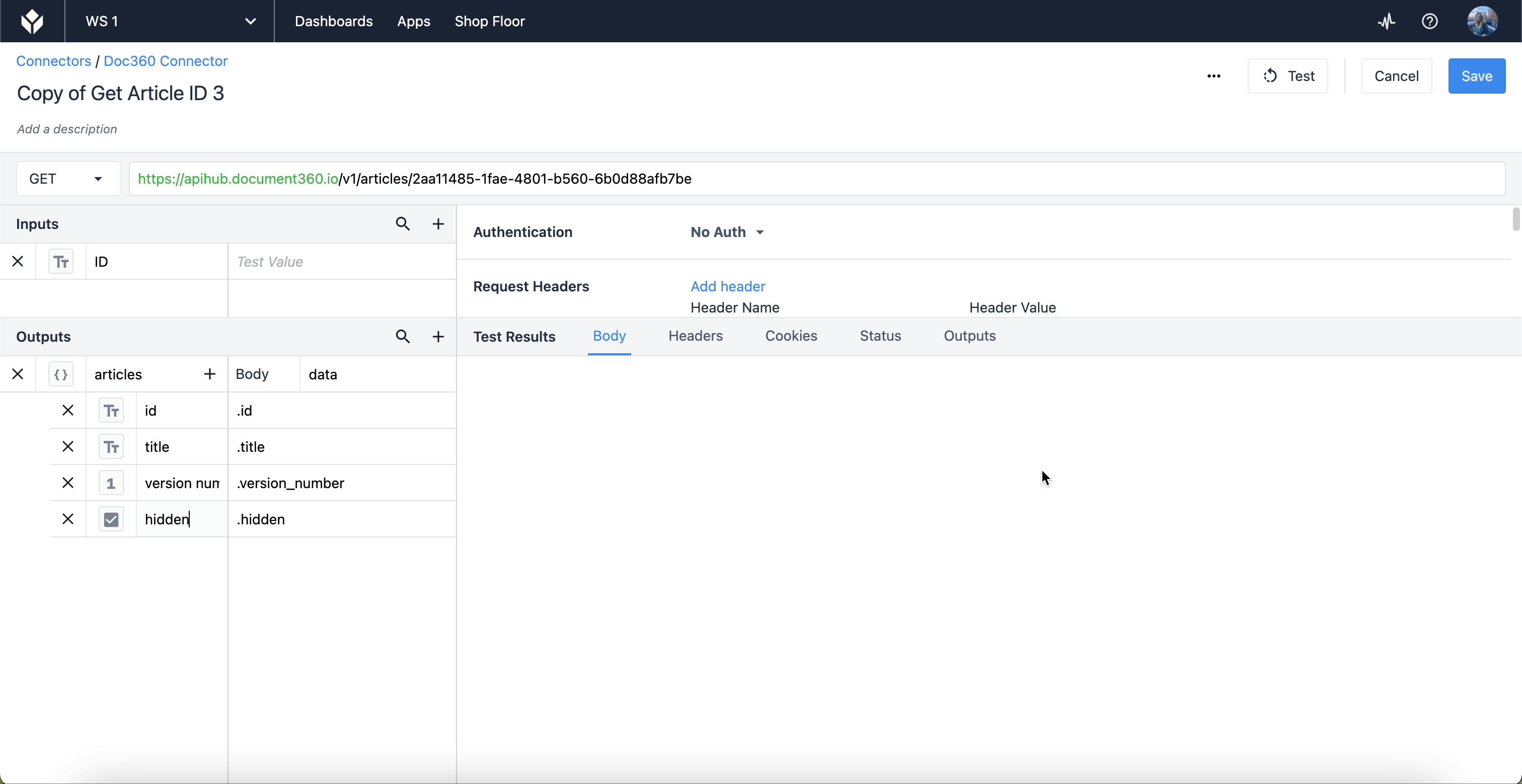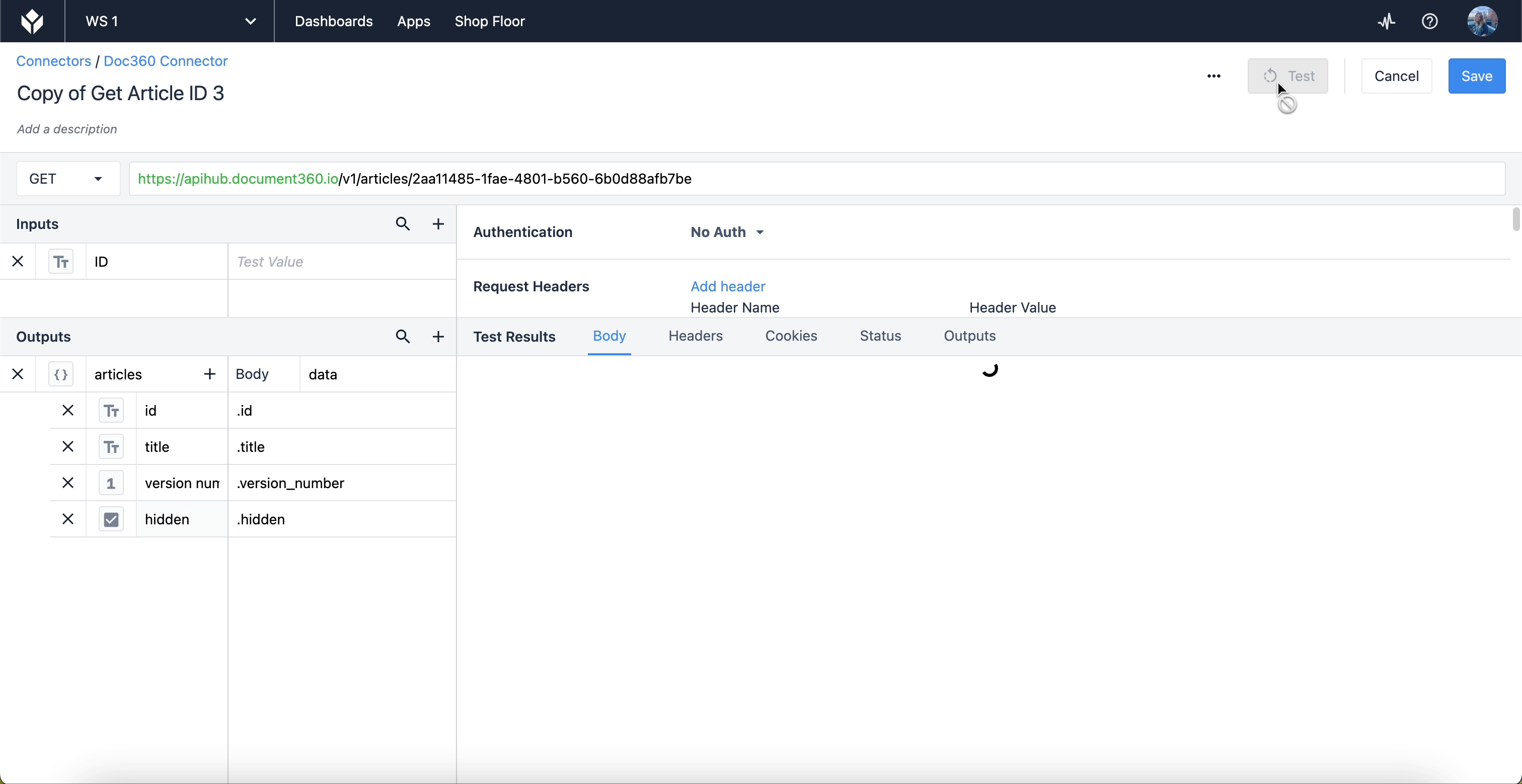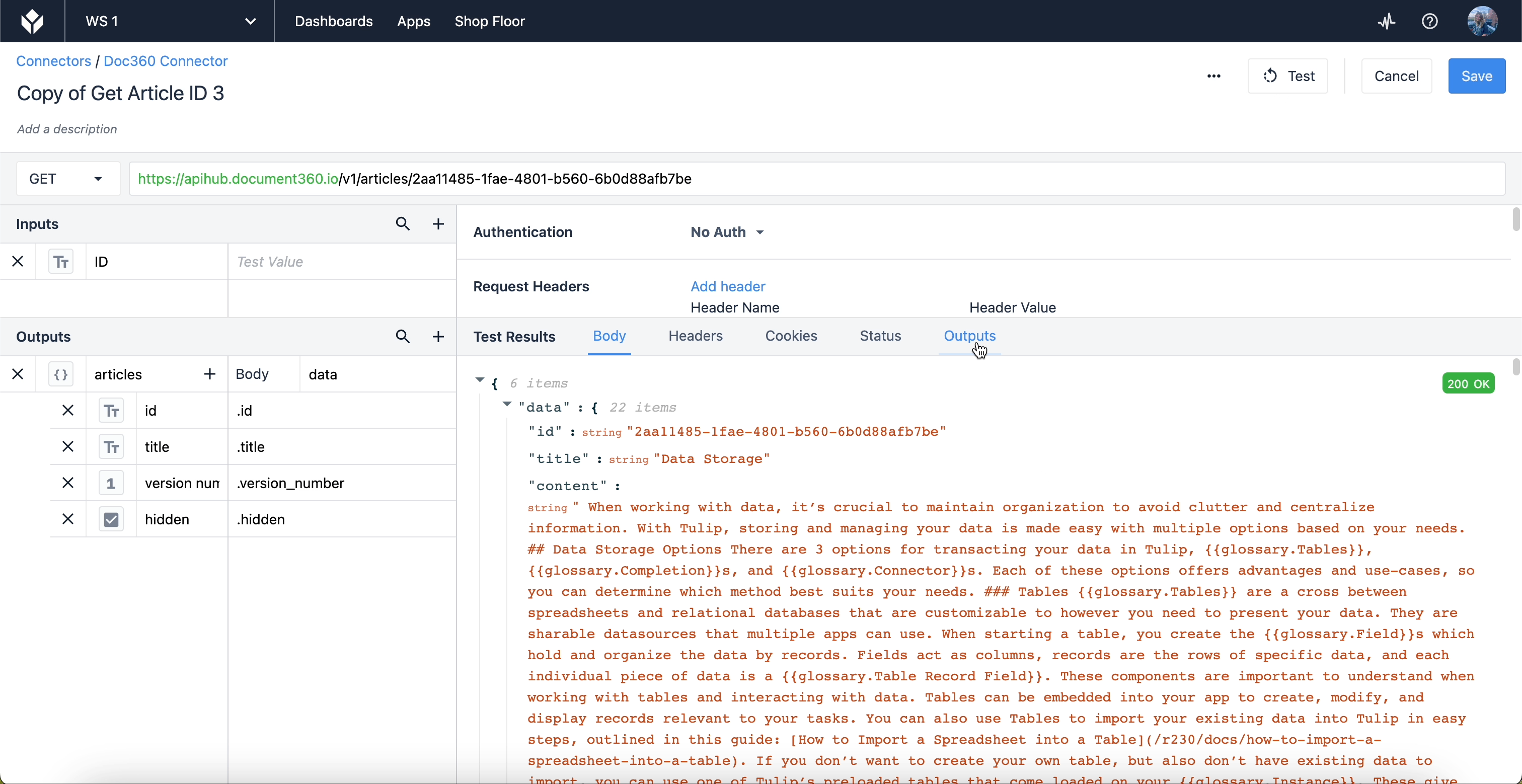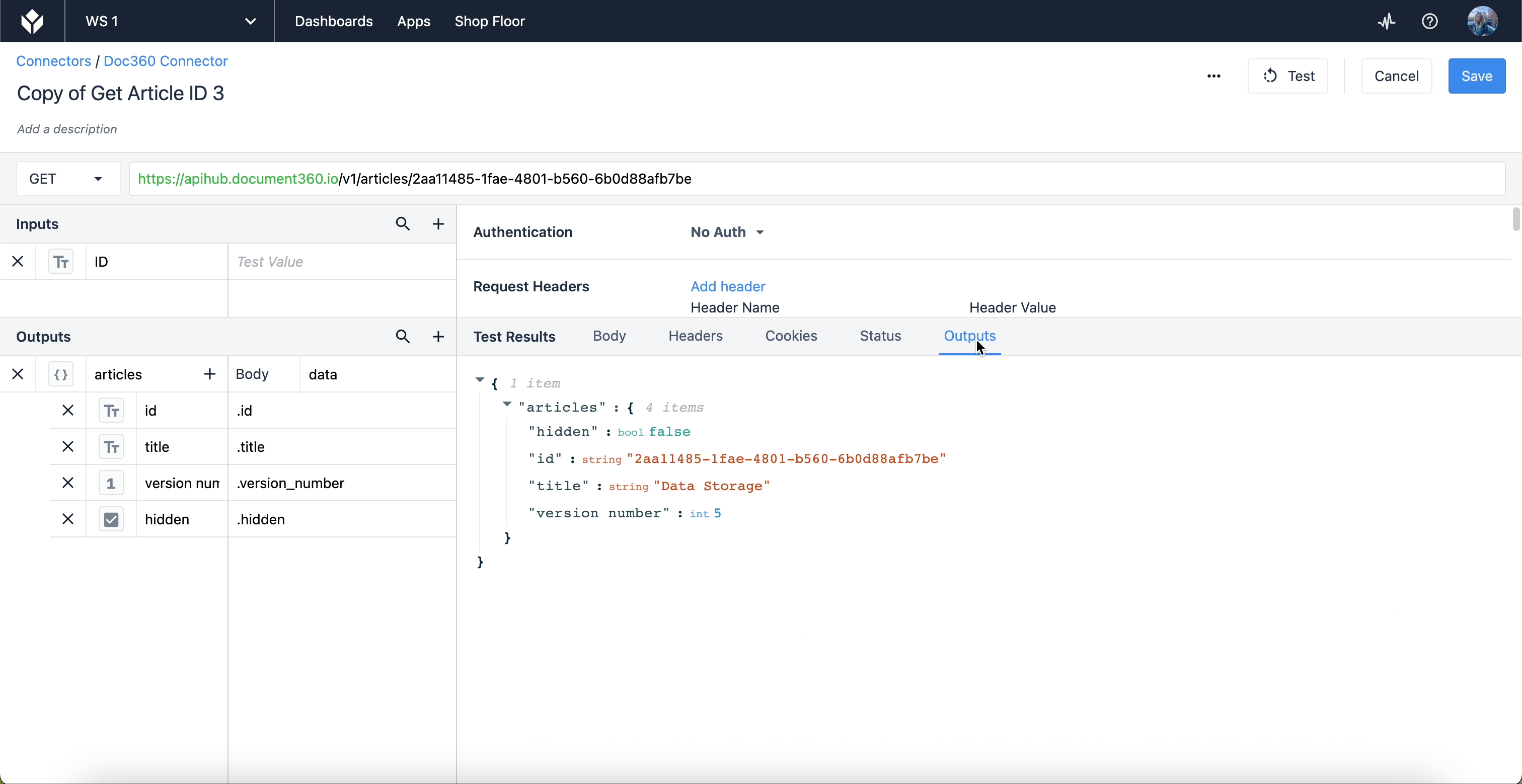
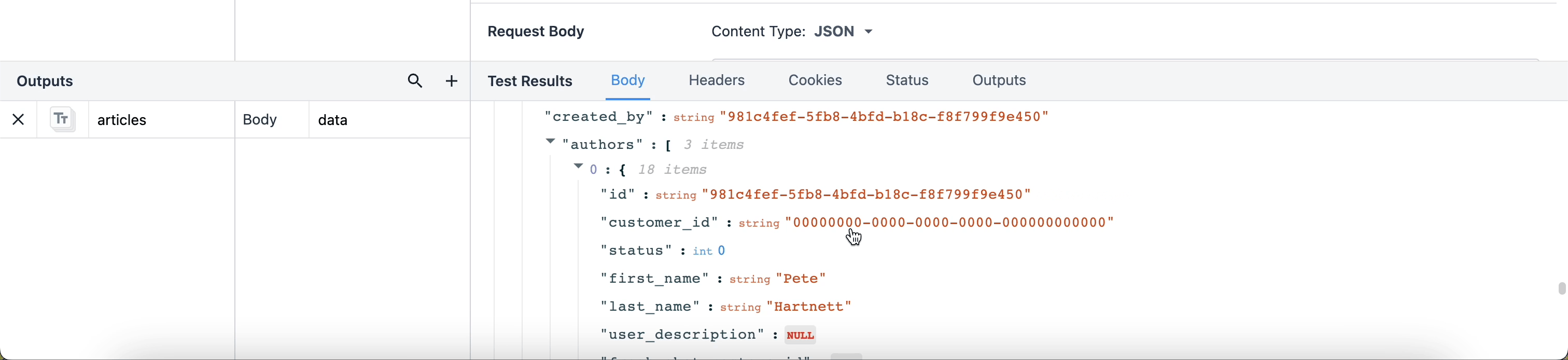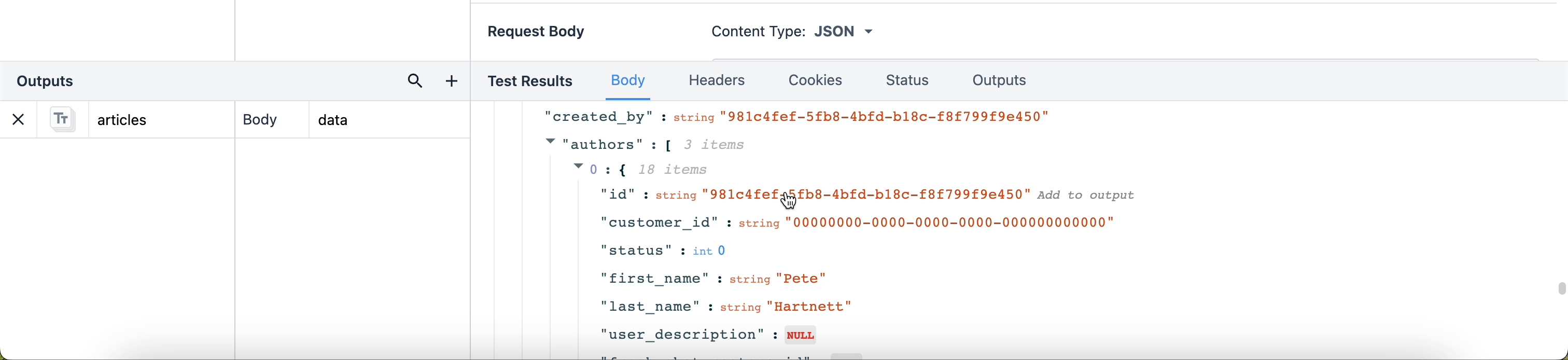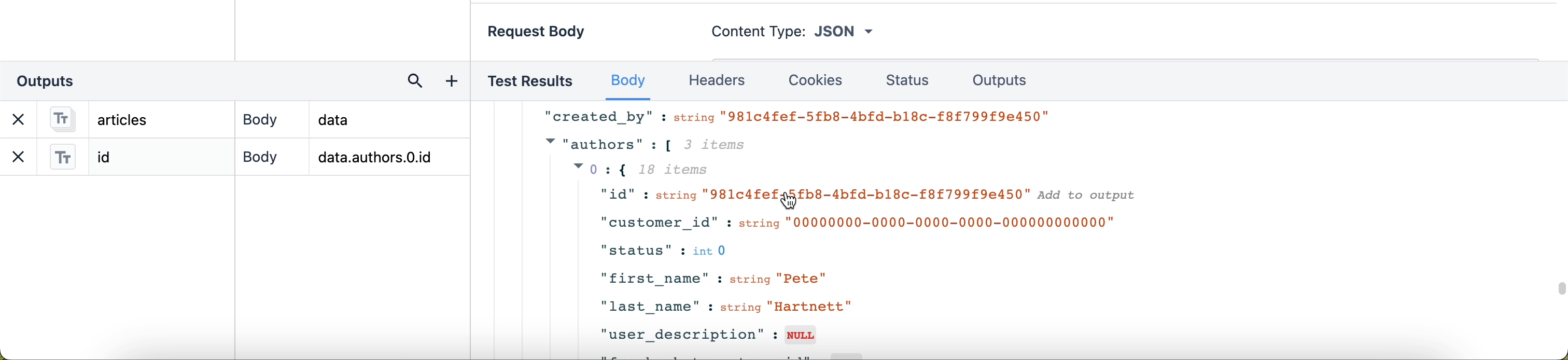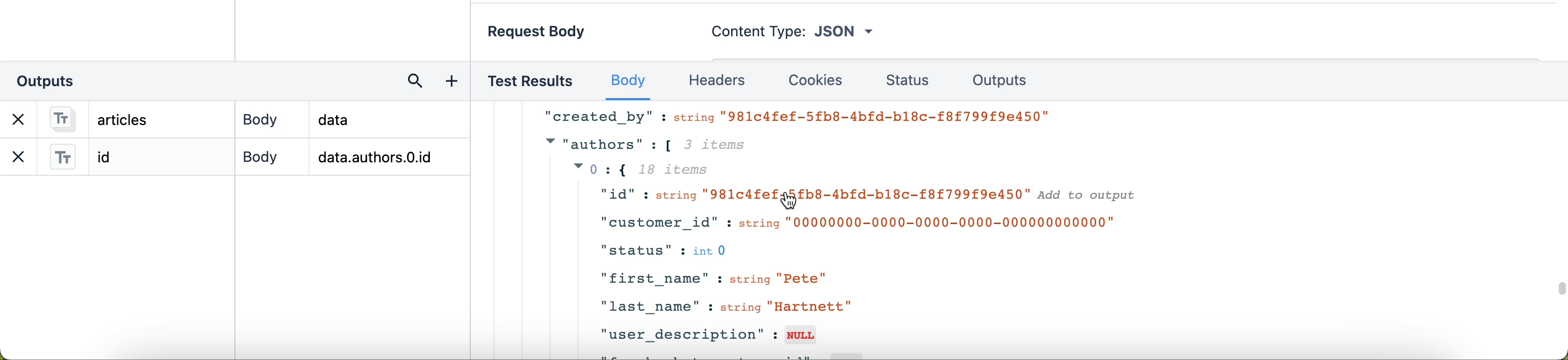
Gdybyśmy chcieli pobrać tylko, powiedzmy, identyfikator, tytuł, wersję i to, czy artykuł jest ukryty. Musielibyśmy określić to za pomocą danych wyjściowych. Zademonstrujmy, jak wygląda notacja kropkowa w sekcji danych wyjściowych edytora:
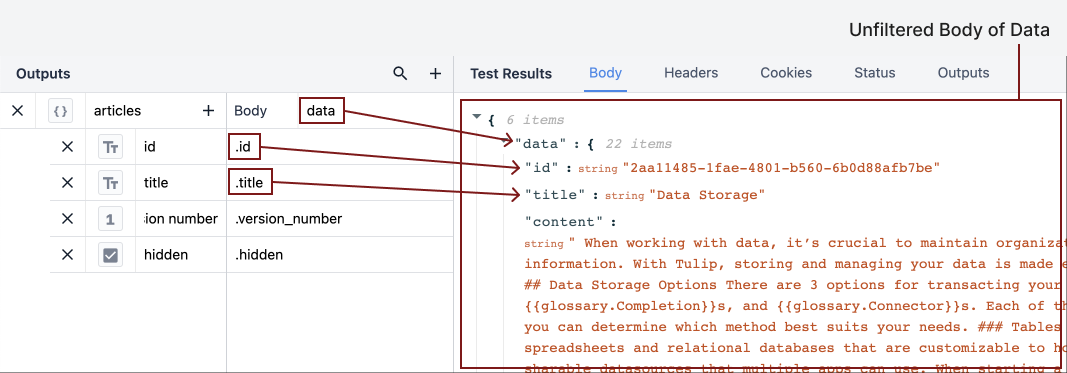
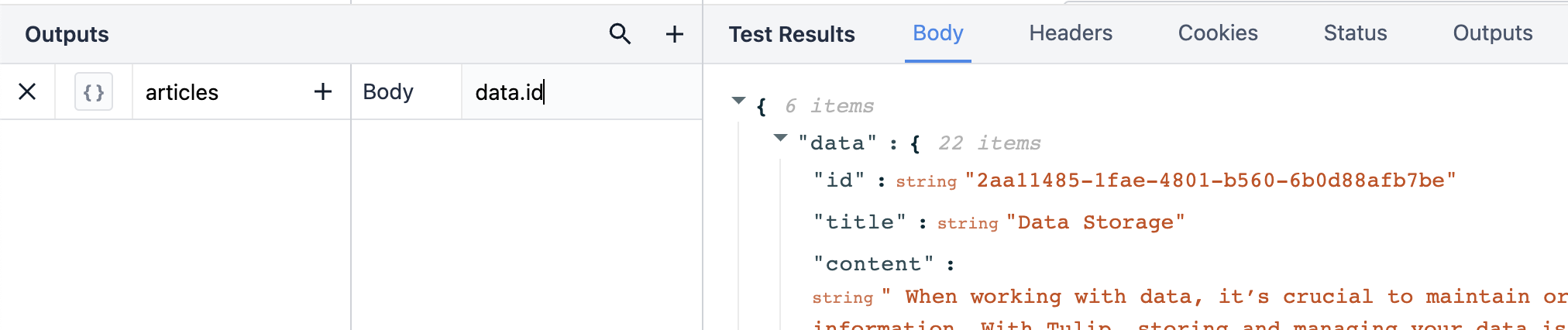
Aby wyciągnąć wyniki takie jak "id" i "title", musimy określić, gdzie te wyniki znajdują się w JSON. Treść danych wyjściowych to "data", odpowiadająca pierwszemu menu rozwijanemu w sekcji Test Results. Każdy wynik w rozwijanym menu "data" jest zagnieżdżony w tym obiekcie. W sekcji Outputs kropka oznacza przejście o jedną warstwę w głąb obiektu "data".
It doesn’t matter whether the dot is placed in the body, or in front of individual properties, so long as there is a dot separating each layer of the JSON.
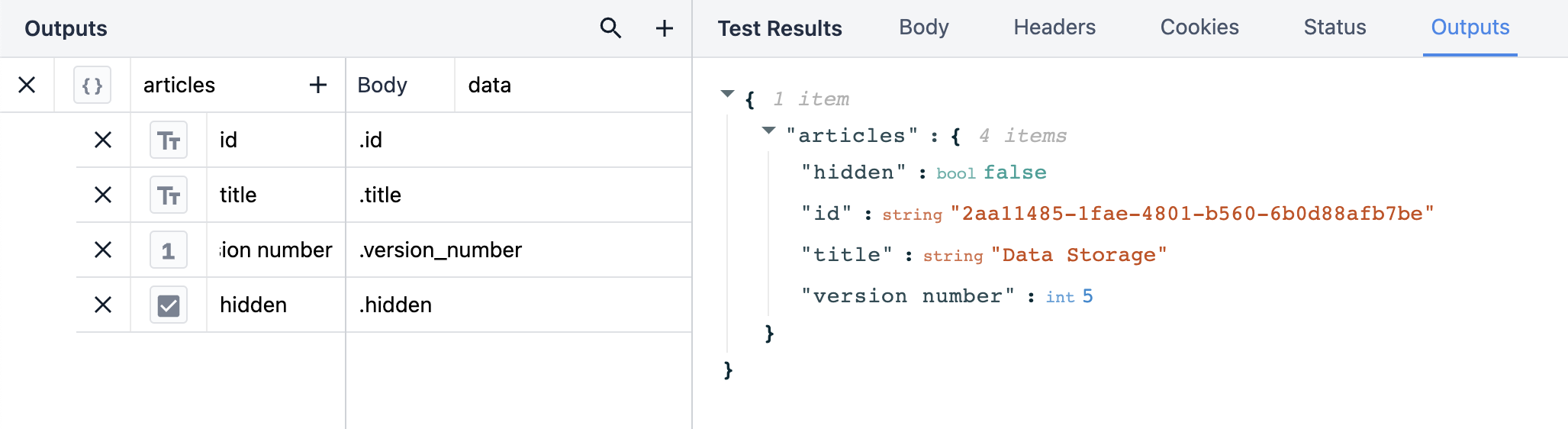
Po kliknięciu zakładki Outputs w sekcji Test Results, dane wyjściowe odfiltrowują resztę danych, dzięki czemu widzimy tylko te informacje, na których nam zależy.
Innym sposobem na zapisanie danych wyjściowych jest pojedyncza linia. To pokazuje pełną ścieżkę w jednym zapytaniu.
Aby w łatwy sposób zapisać ścieżkę wyjściową, można również kliknąć wiersz danych, aby dodać go jako nowe dane wyjściowe.
Aby uzyskać więcej informacji na temat korzystania z notacji kropkowej, zobacz ten zasób: Processmaker: JSON Dot Notation.
Wyniki wyjściowe
Istnieje wiele sposobów strukturyzowania danych wyjściowych, ale sposób, w jaki to zrobisz, jest całkowicie zależny od tego, co chcesz zrobić z danymi w swoich aplikacjach. Zanim zaczniesz strukturyzować dane wyjściowe, zastanów się nad swoim celem końcowym. Czy chcesz wyświetlać wiele typów danych w poszczególnych zmiennych? A może masz te same typy danych w jednej tablicy, którą chcesz po prostu przeanalizować w poszukiwaniu odpowiednich informacji?
Poniższe przykłady opierają się na tej samej funkcji łącznika i w każdym przypadku treść wyników testu jest taka sama. Dane wyjściowe różnią się jednak w zależności od ich struktury.
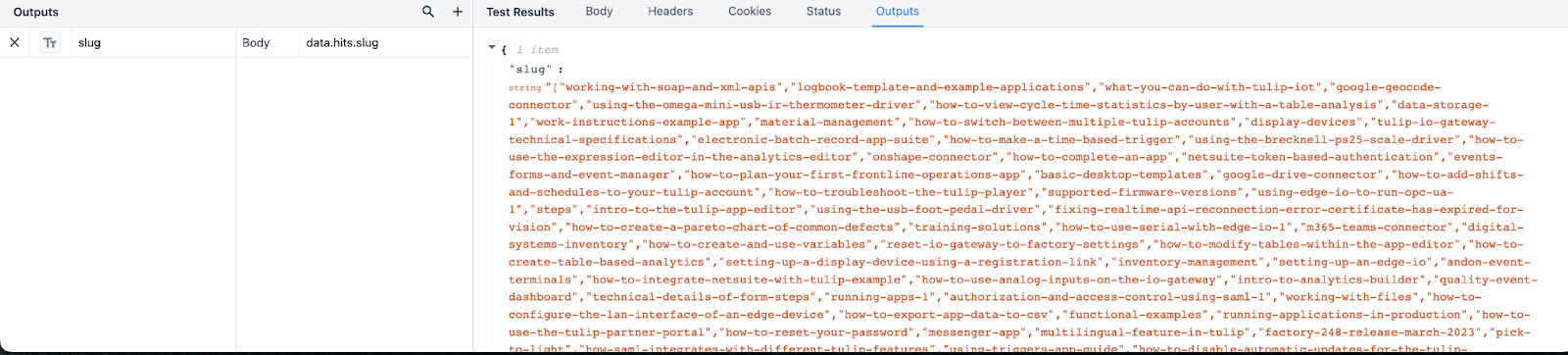
Poniższy przykład pokazuje, w jaki sposób konektor generuje dane wyjściowe dla ścieżki JSON data.hits.slug. Sposób, w jaki skonstruowane są te dane wyjściowe, powoduje, że konektor zwraca dużą tablicę wszystkich slug adresów URL dla artykułów Bazy Wiedzy. W naszych aplikacjach, dane zwracane przez konektor będą dostępne w zmiennej tablicowej.
Możemy ustrukturyzować dane wyjściowe jako listę obiektów i wyciągnąć poszczególne typy danych z wyników, tworząc wiele obiektów danych, które mogą być widoczne indywidualnie w aplikacjach.
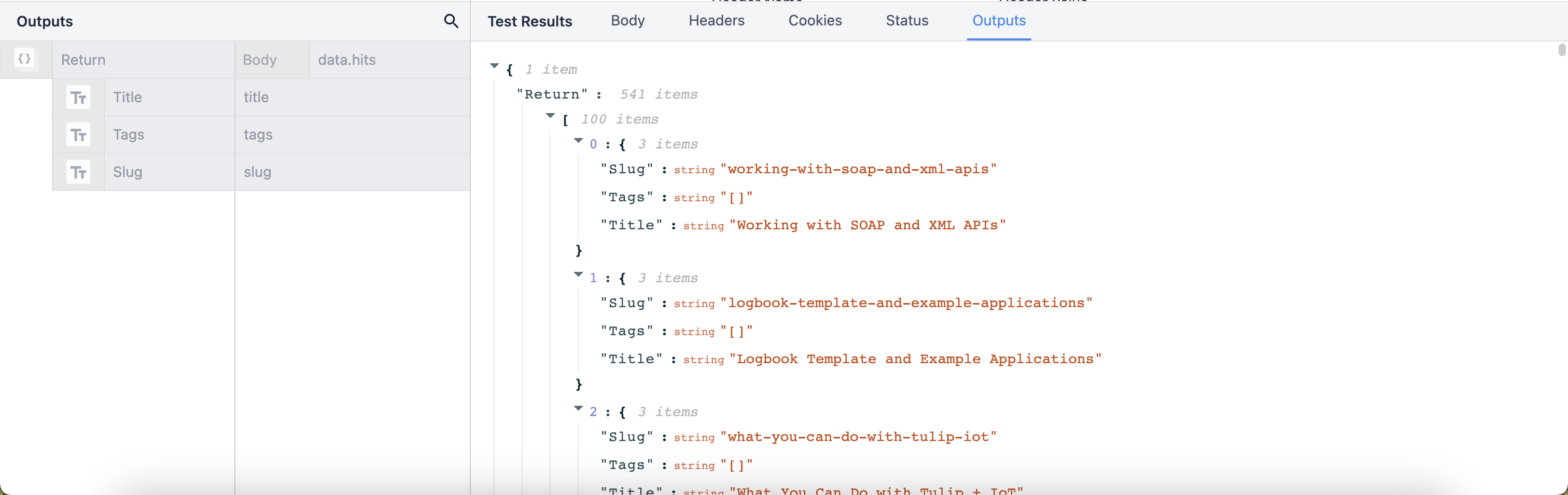
Listy obiektów to obiekty, które zawierają w sobie wiele zagnieżdżonych typów danych. Listy obiektów można używać, klikając typ wyjściowy i przełączając przełącznik Lista w prawym rogu.
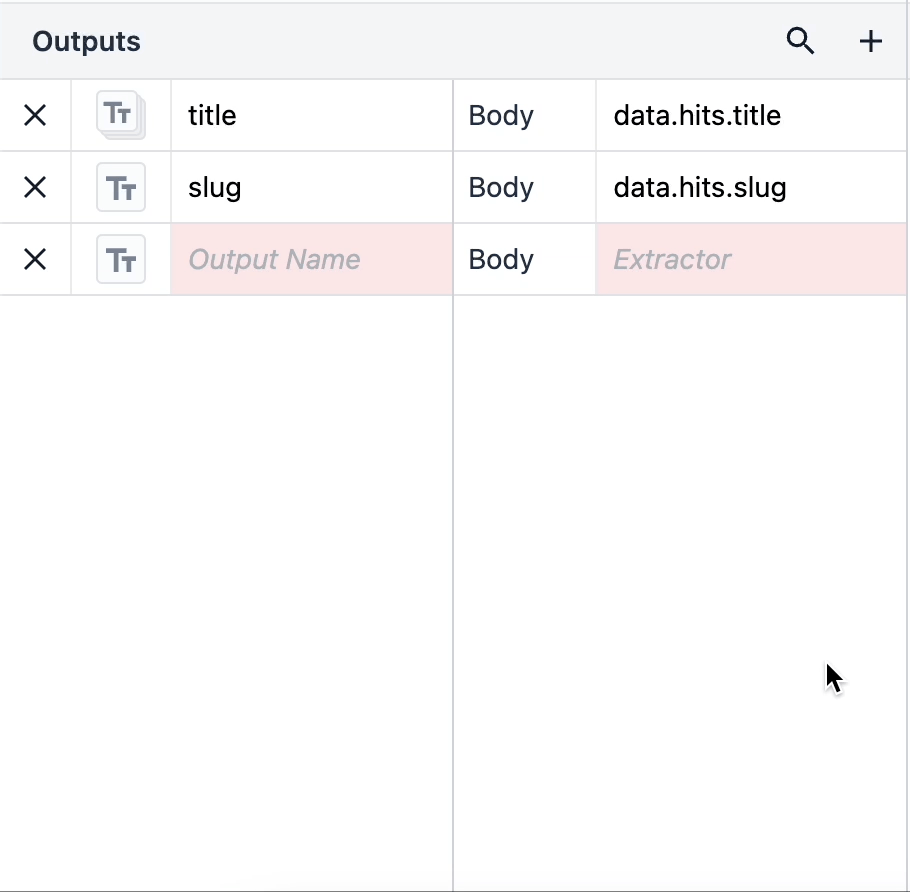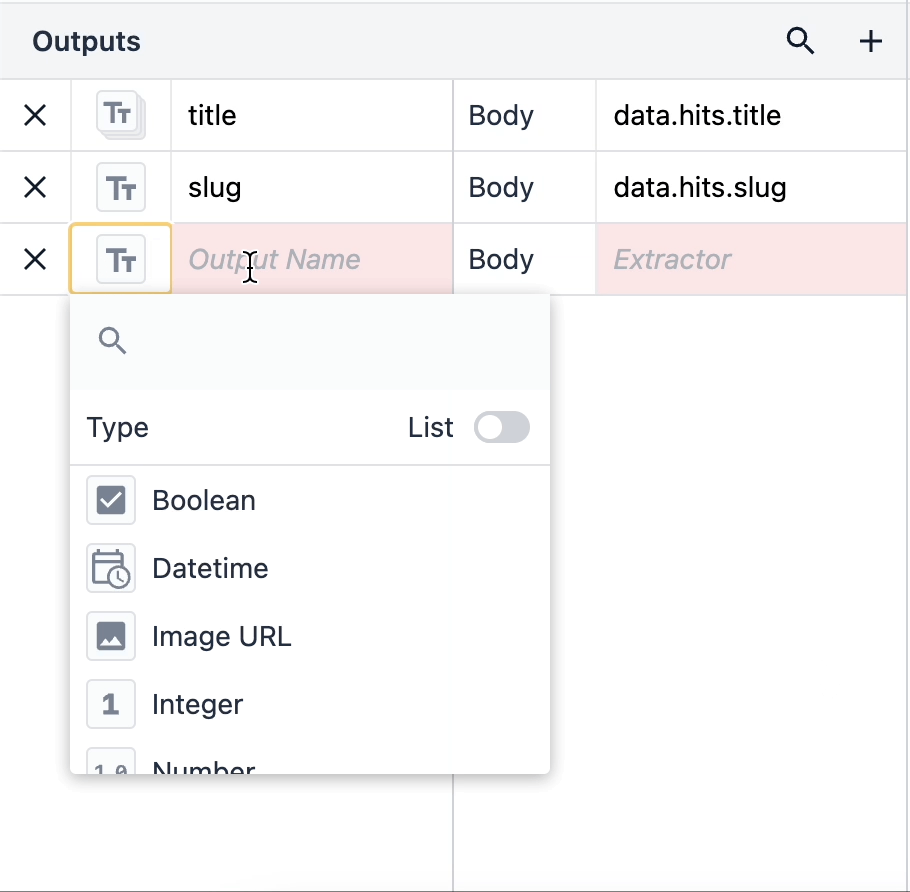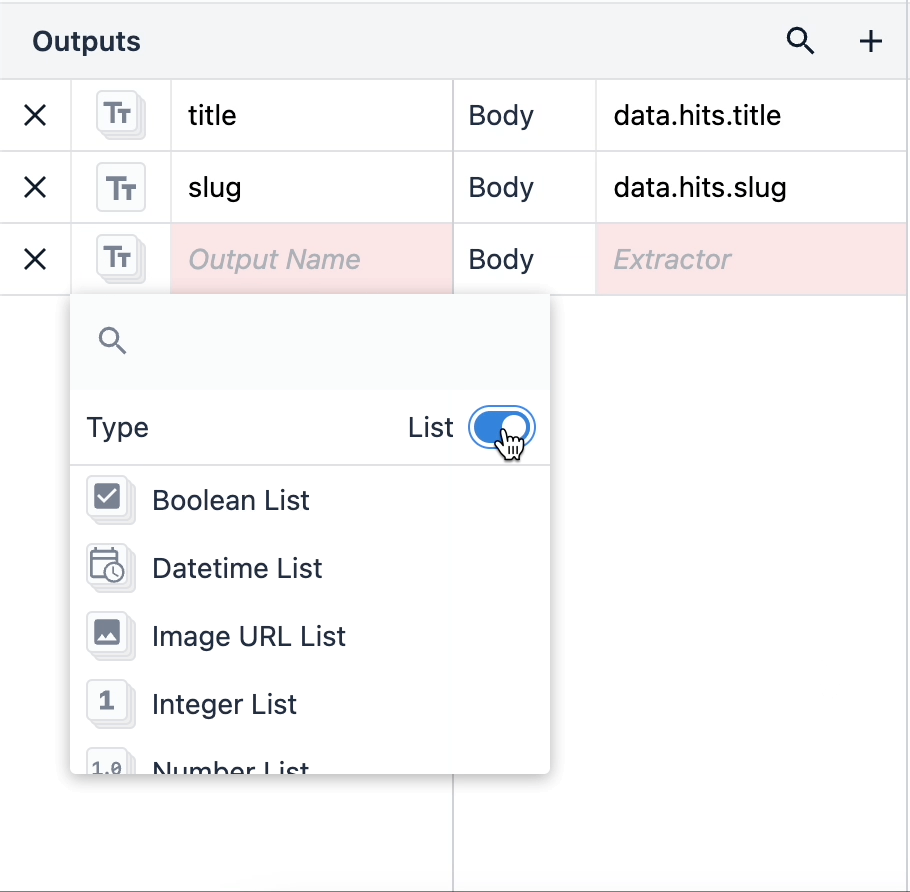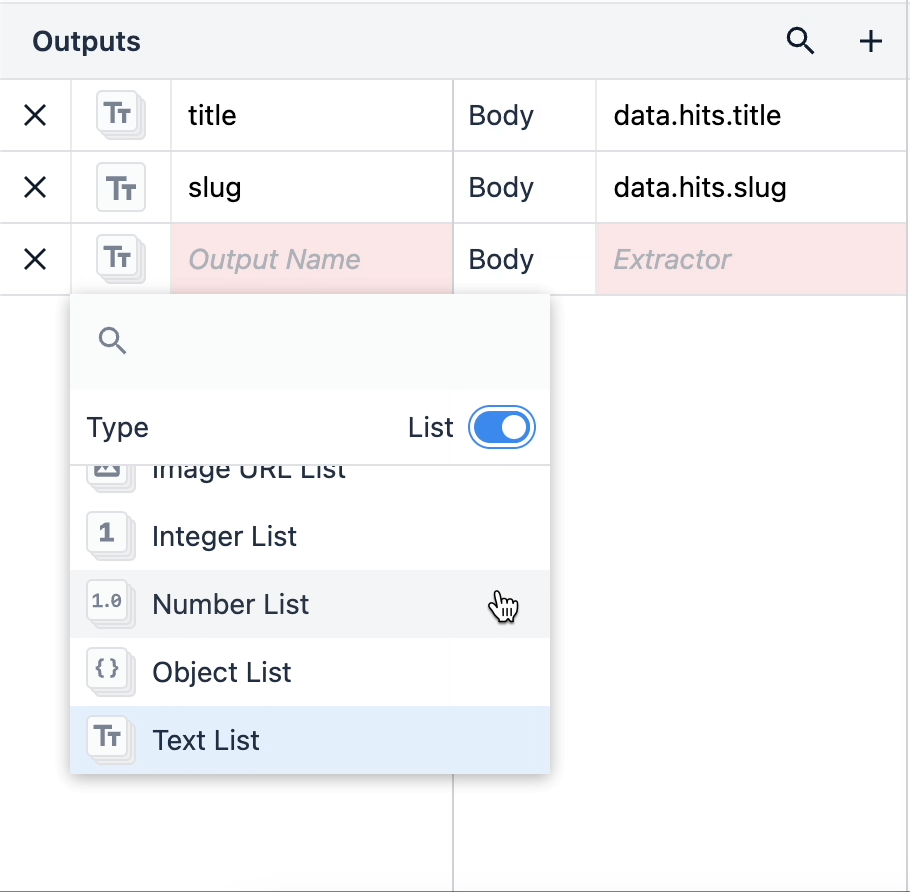
Gdy masz listę obiektów, możesz łatwo używać różnych typów danych jako pojedynczych elementów danych w swoich aplikacjach.
Jeśli wrócimy do powyższego przykładu, niech nasza ścieżka wyjściowa data.hits.slug będzie listą. W poniższych wynikach widać, że Tulip strukturyzuje ten konektor jako tablicę slugów, z każdą pozycją indeksu wymienioną obok każdej wartości.
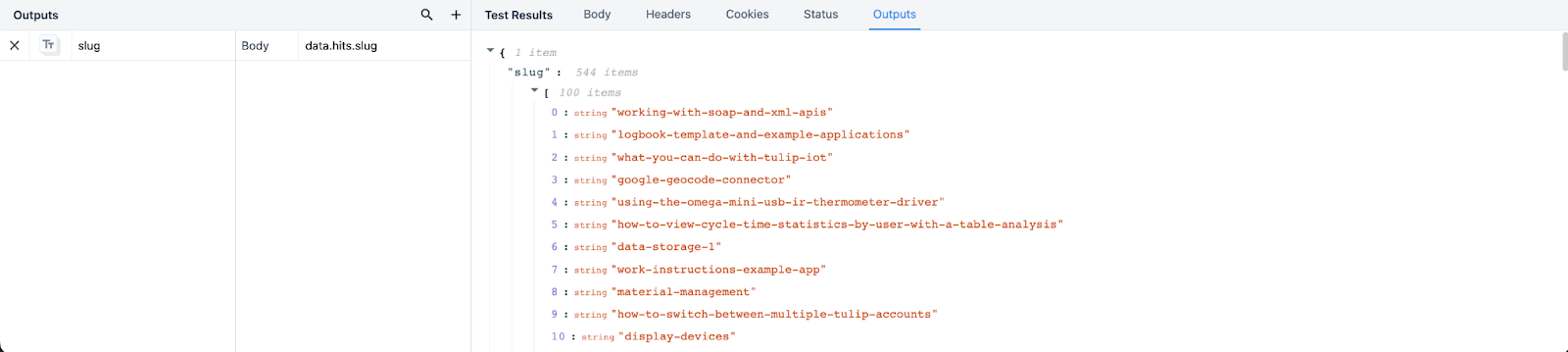
Mając to na uwadze, możesz teraz zmapować dane wyjściowe do własnych funkcji konektora i zoptymalizować zwracane wyniki z konektorów!
Więcej informacji
- Korzystanie z konektorów HTTP w aplikacjach
- Wyświetlanie interaktywnych list rekordów tabeli lub danych wyjściowych konektora w aplikacjach
Czy znalazłeś to, czego szukałeś?
Możesz również udać się na stronę community.tulip.co, aby opublikować swoje pytanie lub sprawdzić, czy inni mieli do czynienia z podobnym pytaniem!