

Un guide sur le modèle universel et sur la façon d'optimiser votre expérience de la fonctionnalité.
Le Universal Template est une expérience unique pour construire des analyses de manière transparente. Il vous permet de passer d'un type de visualisation à l'autre en découplant la requête et la visualisation des données. Le modèle universel prend en charge tous les types d'analyse et toutes les sources de données Tulip (achèvements, données de tableau et données machine).

Utilisation des requêtes et des visualisations
La requête est comme une instruction que vous donnez au système en détaillant ce que vous voulez qu'il fasse avec vos données "brutes" provenant d'une application, d'une machine ou d'une table Tulip. Le résultat de la requête est une représentation tabulaire des données créée par Tulip Analytics en fonction de la façon dont vous avez configuré la requête. Vous configurez la requête sur le panneau latéral gauche de l'Editeur d'Analyse.
Vous pouvez visualiser les données de cette requête avec différentes visualisations, en affichant toutes les données ou seulement des parties sélectionnées. La visualisation est sélectionnée en haut de l'éditeur d'analyse et configurée dans le panneau latéral droit de l'éditeur d'analyse.
Vous pouvez toujours voir le résultat de la requête sous la visualisation si vous cliquez sur Afficher le résultat de la requête, sauf si vous avez sélectionné la visualisation "Tableau".
Construction de la requête
Source de données
Une source de données est ce sur quoi l'analyse est construite. Vous pouvez choisir entre les données d'achèvement d'une application, les données d'un tableau ou les données d'une machine.
Si vous construisez une analyse pour les données d'achèvement d'une application, vous pouvez sélectionner plusieurs applications. L'analyse prendra alors en compte les enregistrements d'achèvement de toutes les applications sélectionnées.
Notez que si plusieurs applications sont sélectionnées, les données ne seront pas jointes, mais chaque achèvement sera traité comme une ligne distincte. Cela signifie que vous pourrez analyser conjointement les "champs" des achèvements (par exemple, l'utilisateur, l'heure de début et la station). D'autres données telles que les variables d'application seront traitées séparément pour chaque application et auront "null" comme valeur pour les enregistrements d'achèvement de toutes les autres applications.
Si vous construisez une analyse pour des machines, vous pouvez sélectionner un ou plusieurs types de machines. Si vous souhaitez construire une analyse pour une machine spécifique, ajoutez un filtre supplémentaire.
Groupements et opérations
Les regroupements et les opérations sont au cœur de la construction de votre requête. C'est là que vous définissez les options de données que vous souhaitez afficher et sous quelle forme.
Regroupements
Les regroupements donnent des instructions pour combiner les groupes autant que possible. Si vous êtes familier avec la fonction GROUP BY des outils QL et BI courants, le processus de regroupement se comporte de manière presque identique. Les regroupements déterminent les champs et les types de données pour lesquels des valeurs similaires doivent être trouvées. Ils vous permettent d'obtenir une vue de plus en plus granulaire des données que vous souhaitez consulter.
Les regroupements permettent de mieux définir les lignes à combiner. Un regroupement peut être un champ de n'importe quel type. Selon les opérations que vous avez configurées, l'ajout d'un ou de plusieurs regroupements aboutira à des résultats différents.
Voyons quelques combinaisons de regroupements.
| Un seul regroupement | Plusieurs regroupements | --- | --- | --- | Uniquement les valeurs distinctes | Une ligne pour chaque ligne des données source montrant les valeurs du champ de regroupement et les valeurs distinctes pour cette ligne | Une ligne pour chaque ligne des données source montrant les valeurs des champs de regroupement et les valeurs distinctes pour cette ligne | Uniquement les agrégations | Une ligne pour chaque entrée distincte dans le champ de regroupement avec cette valeur pour le regroupement et les valeurs agrégées de toutes les lignes des données source avec cette valeur de regroupement | Une ligne pour chaque entrée distincte dans le champ de regroupement avec cette valeur pour le regroupement et les valeurs agrégées de toutes les lignes des données source avec cette valeur de regroupement | Une ligne pour chaque entrée distincte dans le champ de regroupement avec cette valeur de regroupement | Une ligne pour chaque combinaison d'entrées distinctes dans les champs de regroupement avec les valeurs respectives des regroupements et les valeurs agrégées de toutes les lignes des données source avec les valeurs de regroupement respectives | | Valeurs distinctes et agrégations | Une ligne pour chaque ligne des données source montrant les valeurs des regroupements et les valeurs distinctes et les valeurs agrégées de toutes les lignes des données source avec cette valeur de regroupement (c'est-à-dire que les valeurs agrégées sont les valeurs de regroupement et les valeurs distinctes de toutes les lignes des données source).Les valeurs agrégées sont les mêmes pour toutes les lignes ayant la même valeur de regroupement.) | Une ligne pour chaque ligne des données source montrant les valeurs des regroupements et les valeurs agrégées de toutes les lignes des données source avec les valeurs de regroupement respectives (c'est-à-dire que les valeurs agrégées sont les mêmes pour toutes les lignes avec les mêmes valeurs de regroupement).
Il est important de noter que les données ne seront affichées que s'il existe une ligne contenant des informations pertinentes. S'il n'y a pas de données dans les données sources pour un jour spécifique, l'analyse apparaîtra vide.
Voyons un exemple du fonctionnement des regroupements :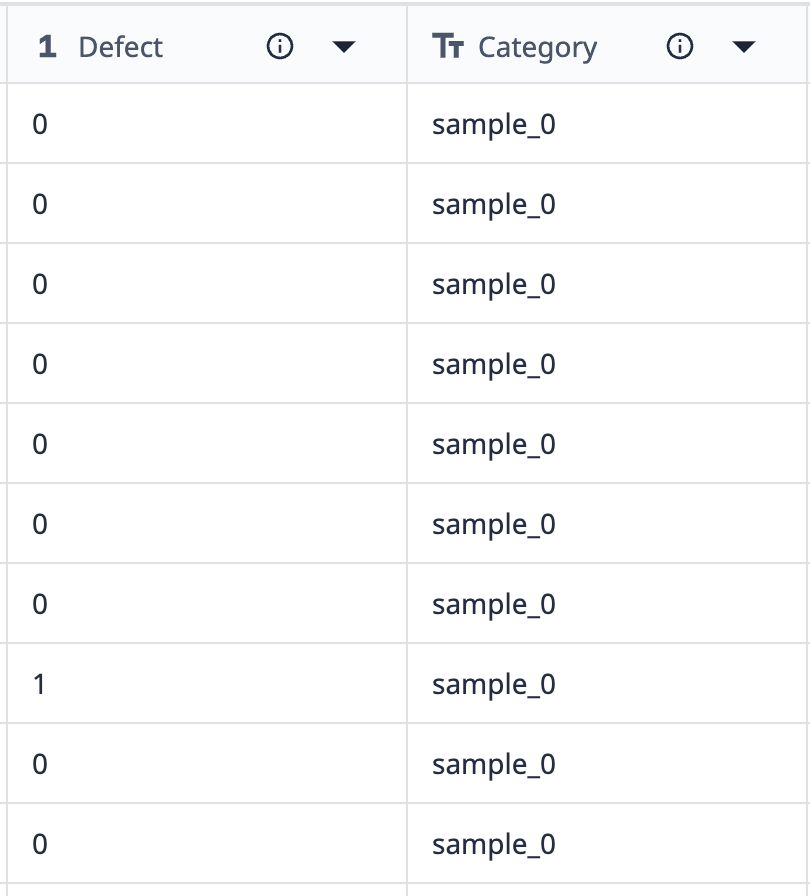
Les données de ce tableau montrent qu'il existe 10 enregistrements intitulés "sample_0". Si nous voulons regrouper ces données dans une visualisation qui ne montre que les différents points de l'échantillon_0 où le nombre de défauts diffère, nous pouvons utiliser les regroupements pour combiner des ensembles de données similaires.
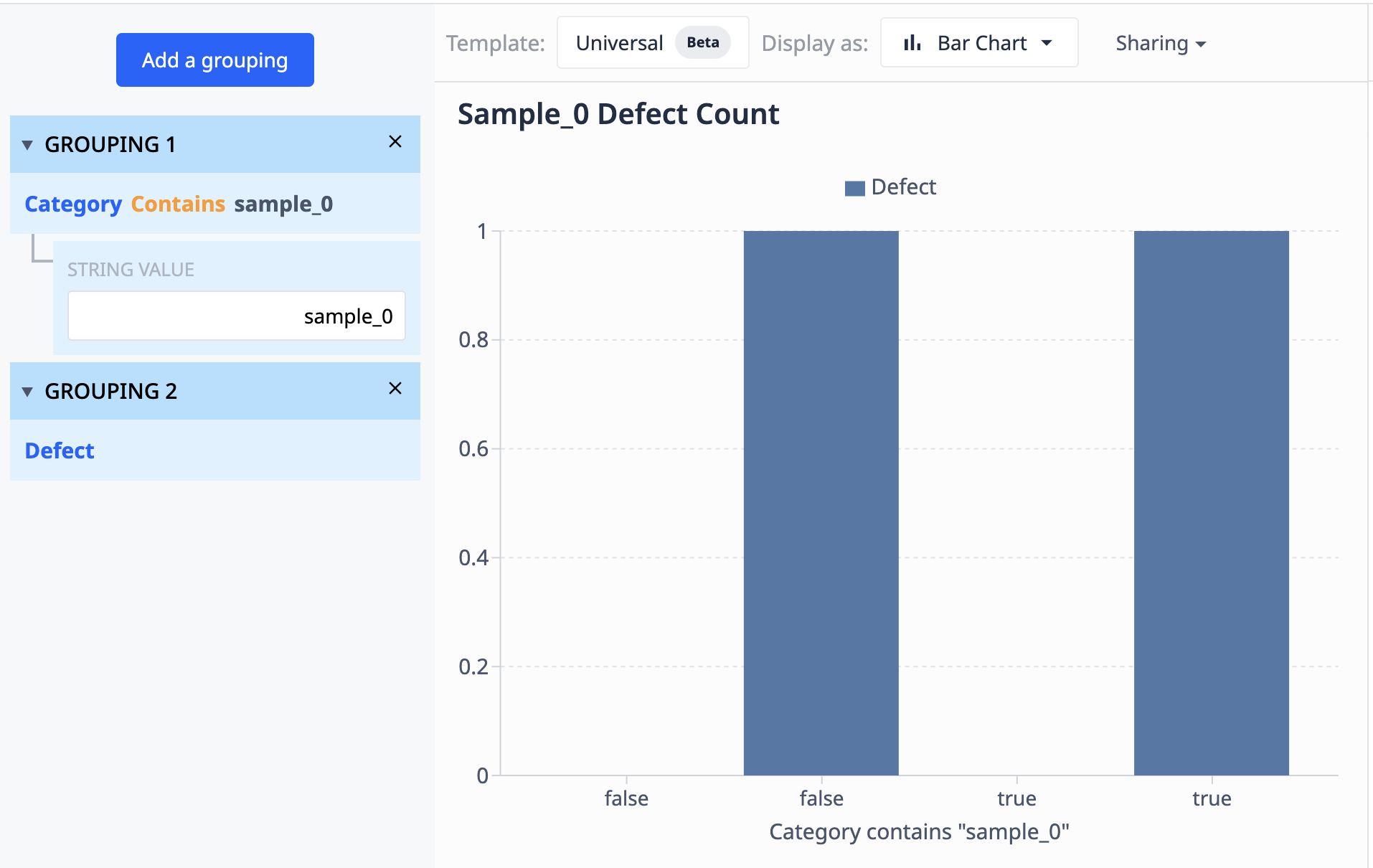
Opérations
Les opérations peuvent être soit une agrégation qui combine plusieurs enregistrements, soit un champ qui ne le fait pas.
Les opérations se répartissent en deux catégories générales : 1. Valeurs distinctes Les valeurs distinctes représentent des points de données individuels de vos données sources. Dans le cas le plus simple, il s'agit d'une valeur d'une variable d'un enregistrement d'achèvement, d'un champ d'une table ou d'un attribut de machine.
Mais il peut également s'agir d'un point de données plus avancé, comme la somme de deux champs d'un même enregistrement, une combinaison de plusieurs chaînes de caractères ou une expression qui n'inclut pas de fonction d'agrégation.
En utilisant un tableau contenant un champ de valeurs (numériques) et un champ d'horodatages (datetime), nous pouvons visualiser les valeurs par horodatage pour qu'elles apparaissent comme telles :
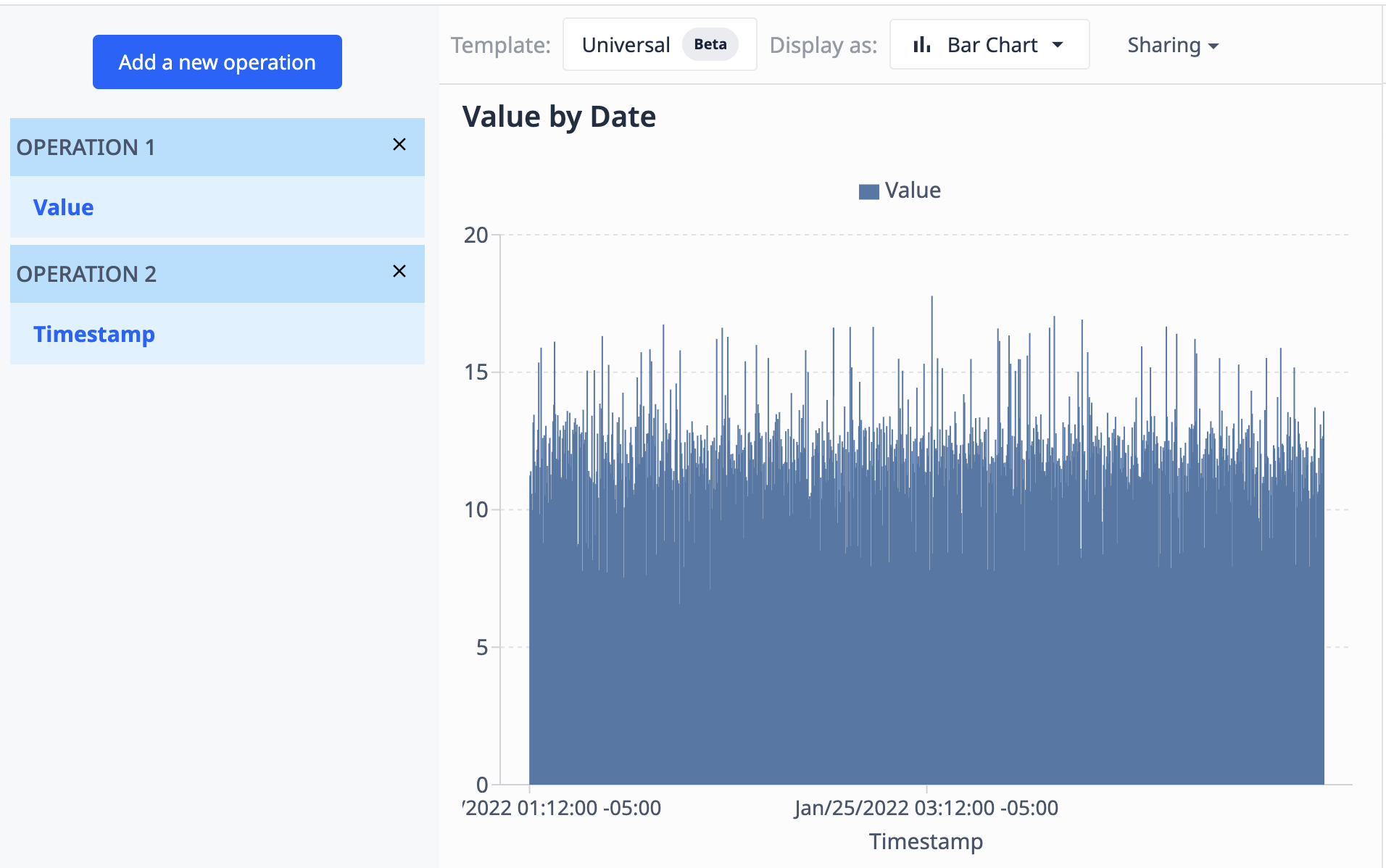
- Agrégations
Les agrégations sont des fonctions qui prennent des données de plusieurs lignes et les combinent en fonction d'une logique définie. Un ensemble de fonctions d'agrégation est disponible sous forme de sélections préconfigurées. Vous pouvez également utiliser des fonctions d'agrégation dans l'éditeur d'expressions pour créer vos propres agrégations avancées. Différentes fonctions d'agrégation fonctionnent pour différents types de données. Vous trouverez ci-dessous les fonctions disponibles et les types de données qu'elles prennent en charge.
Fonctions d'agrégation directement accessiblesElles permettent de combiner des lignes :
- Moyenne
- Médiane
- Somme
- Minimum
- Maximum
- Mode de fonctionnement
- Écart-type
- 95ème centile
- 5ème centile
- Ratio
- Ratio Complément
Fonctions d'agrégation disponibles dans l'éditeur d'expression
Les fonctions d'agrégation de l'éditeur d'expressions peuvent fournir des données plus granulaires en fonction de vos besoins spécifiques. Pour un guide complet de toutes les expressions disponibles que vous pouvez utiliser dans vos analyses, voir Liste complète des expressions dans l'éditeur d'analyse.
Limite et tri
Vous pouvez définir le nombre maximum de lignes que le résultat de la requête contient en ajoutant une limite. Les limites vous permettent de vous concentrer sur des données spécifiques ou de limiter la quantité de données affichées dans un graphique. Par exemple, vous pouvez ajouter une limite pour afficher les trois lignes de production qui ont eu le plus de défauts au cours du mois dernier.
Les données de tri définissent les lignes à inclure dans l'évaluation de la limite. Vous pouvez ajouter un tri croissant ou décroissant pour tout champ faisant partie du résultat de la requête. Si vous ajoutez plusieurs champs à trier, les données seront d'abord triées en fonction du premier champ. Les groupes résultant de chaque valeur du premier champ seront ensuite triés en fonction du second, etc.
Notez que si vous ne définissez pas explicitement le tri, le tri du résultat de votre requête peut varier en fonction des données disponibles. Lorsque vous utilisez des limites ou des graphiques avec des axes ordinaux, cela peut conduire à des visualisations différentes. Nous recommandons d'ajouter un tri approprié dans ces cas.
L'exemple suivant reprend le graphique que nous avons vu en utilisant Opérations. Ici, nous limitons les résultats à 100 points de données et les trions par ordre décroissant en fonction de leur date.
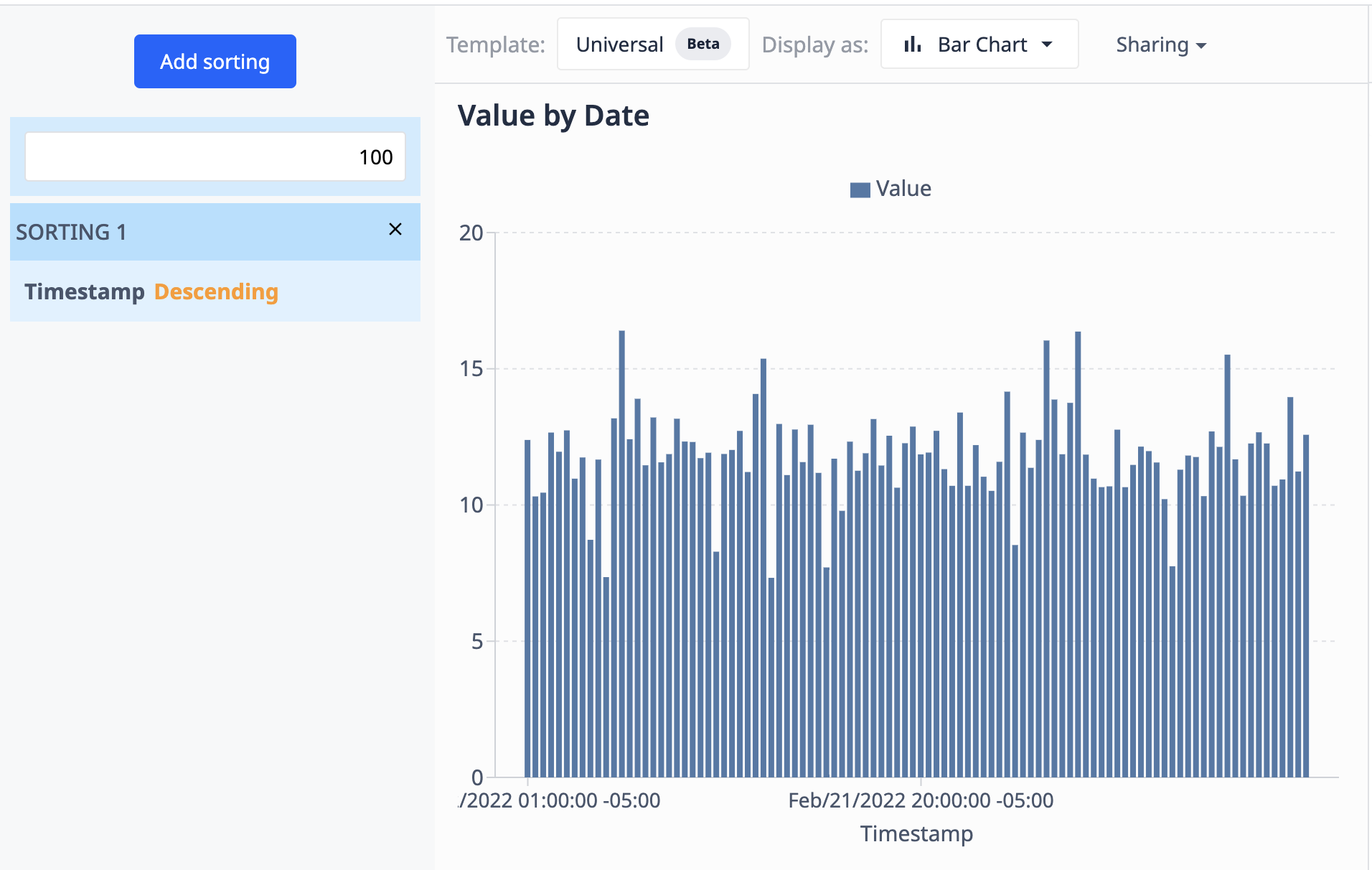
Comme la source de données (le tableau) est mise à jour avec de nouveaux enregistrements, la visualisation n'affichera que les 100 enregistrements les plus récents.
Plage de dates
La plage de dates définit les données à inclure dans l'évaluation de l'analyse. Il s'agit en quelque sorte d'un filtre pour une valeur de date dans l'ensemble de données. Pour des raisons de performance, nous vous recommandons d'utiliser la plage de dates la plus courte possible pour votre cas d'utilisation plutôt que d'ajouter des filtres supplémentaires ultérieurement pour réduire la période.
Les valeurs suivantes sont utilisées pour la plage de dates des différentes sources de données : * Données d'achèvement de l'application * "Heure de début" de l'achèvement de l'application * Date de la table, sélectionnable par l'utilisateur * Date de création * Date de mise à jour * Données de la machine * Heure de début de l'entrée de l'activité de la machine
Filtres
Les filtres définissent les données à inclure dans le résultat de la requête. Les cas d'utilisation typiques sont les suivants : * Afficher les données d'une ligne de production spécifique * Exclure une machine spécifique d'une analyse * Afficher uniquement les points de données dont la valeur est supérieure à un seuil spécifique.
Les filtres sont configurés comme une condition. Toutes les données qui remplissent la condition sont incluses dans l'analyse. Voyons quelques exemples :
- Ligne de production égale A
- Inclura tous les enregistrements qui ont "A" dans le champ "Ligne de production".
- L'ID de la machine n'est pas égal à "Machine 1"
- Inclura toutes les machines qui ne sont pas égales à "Machine 1".
- Durée du test > 55
- Inclura tous les enregistrements où le test a duré plus de 55 secondes.
Les filtres peuvent être définis de deux manières différentes : 1. En utilisant les fonctions de filtrage préconfigurées en combinaison avec un champ de vos données source. 2. En configurant une expression qui évalue un booléen.
Visualisations
Lorsqu'une nouvelle analyse est créée à l'aide du modèle universel, la visualisation Tableau est sélectionnée par défaut. Vous pouvez à tout moment passer à un autre type de visualisation en utilisant le paramètre Display As en haut de l'écran. Outre "Tableau", les options sont les suivantes :
- Barre
- Ligne
- Scatter (nuage de points)
- Histogramme
- Donut
- Jauge
- Boîte
- Valeur unique
- Diaporama
- Pareto
Configuration d'une visualisation
Pour la plupart des types de visualisation, vous pouvez librement sélectionner les champs du résultat de votre requête que vous souhaitez visualiser et de quelle manière. Cette opération s'effectue dans le panneau de données situé à droite de l'éditeur d'analyse. Lorsque vous passez à une visualisation différente pour la première fois, la configuration est vide. Vous pouvez configurer votre visualisation manuellement dans le panneau de données ou commencer par une suggestion en cliquant sur le bouton Commencer par une suggestion au centre de l'écran.
Les conditions préalables pour pouvoir configurer une visualisation sont les suivantes :
- Il y a des données dans le résultat de votre requête
- Vous avez les bons champs disponibles pour la visualisation. Par exemple, un diagramme à barres nécessite au moins un champ numérique
Si ces deux conditions ne sont pas remplies, l'éditeur d'analyses affichera un message d'avertissement.
Options du panneau de données
La liste suivante donne un aperçu des options de configuration pour les différents types de visualisation :
Barre, Ligne, Nuage de points
- Axe des X
- Le champ dont les valeurs doivent être affichées sur l'axe des X
- Axe Y
- Un ou plusieurs champs numériques dont les valeurs doivent être affichées sur l'axe des Y.
- Comparer par
- Champ utilisé pour afficher les valeurs d'une même série dans le graphique.
Si vous souhaitez afficher plusieurs séries, vous pouvez le faire en sélectionnant plusieurs champs pour l'axe des Y ou un champ pour l'axe des Y et un champ pour Comparer par. Il n'est pas possible de combiner plusieurs champs pour l'axe des Y et la comparaison par.
Un mode "Comparer les valeurs des champs" est disponible pour ces types de visualisation dans le menu "..." du réglage de l'axe des X. Ce mode permet de visualiser des valeurs numériques. Il permet de visualiser les valeurs numériques de plusieurs champs côte à côte. Lorsque l'option est activée, les options suivantes sont disponibles :
- Axe des X
- Les champs numériques à comparer
- Comparer par
- Le champ utilisé pour afficher les valeurs de la même série dans le graphique
- La valeur par défaut est l'indice de ligne des données.
Histogramme
- Valeurs
- Champ numérique contenant les valeurs pour lesquelles l'histogramme est affiché.
- Ce champ doit contenir toutes les valeurs de manière non agrégée. La visualisation se charge de calculer les valeurs de l'histogramme.
- Comparer par
- Le champ utilisé pour diviser les "Valeurs" en plusieurs séries, chacune étant représentée par un histogramme distinct dans la visualisation.
Donut
- Valeurs
- Les champs numériques contenant les valeurs à visualiser.
- Étiquettes
- Le champ utilisé pour les étiquettes des différents segments de donuts. Celles-ci apparaîtront dans l'infobulle et dans la légende.
- L'indice de ligne des données visualisées est utilisé par défaut.
Valeur unique, jauge
- Valeur
- Les champs numériques contenant la valeur à visualiser
Note : La valeur de la première ligne du résultat de la requête sera visualisée. Si votre requête renvoie plusieurs lignes, vous pouvez ajouter un tri pour modifier cette valeur. Nous vous recommandons d'utiliser le bouton "Afficher le résultat de la requête" en bas de page pour vérifier les données si vous ne voyez pas la valeur attendue dans la visualisation.
Boîte
- Axe des X
- Le champ dont les valeurs doivent être affichées sur l'axe des X
- Une "boîte" distincte sera visualisée pour chaque valeur de ce champ.
- Axe Y
- Le champ numérique contenant les valeurs à visualiser dans le diagramme en boîte est affiché
- Ce champ doit contenir toutes les valeurs de manière non agrégée. La visualisation se charge de calculer les valeurs de la boîte.
Pareto
- Axe des X
- Champ dont les valeurs doivent être affichées sur l'axe des X.
- Axe Y
- Le champ numérique dont les valeurs doivent être affichées sur l'axe des Y.
La ligne de pourcentage cumulé est automatiquement calculée dans la visualisation.
Passer d'un type de visualisation à l'autre
Lorsque l'on passe d'un type de visualisation à l'autre configuré dans l'écran de contrôle, toute configuration compatible est conservée. Cela minimise l'effort de commutation et vous permet d'essayer facilement différentes options de visualisation pour vos données.
Tableau et diaporama
Les visualisations Tableau et Diaporama n'ont pas de panneau de données et sont automatiquement configurées.
Ce tableau montre tous les regroupements et opérations configurés dans la requête. Ils sont classés dans l'ordre dans lequel ils apparaissent dans le générateur de requêtes à gauche.
Le Diaporama montre toutes les images qui se trouvent dans n'importe quel champ d'image du résultat de la requête sous forme de diapositives individuelles. Les champs supplémentaires configurés dans la requête sont affichés dans un tableau sous l'image.
Vous avez trouvé ce que vous cherchiez ?
Vous pouvez également vous rendre sur community.tulip.co pour poser votre question ou voir si d'autres personnes ont rencontré une question similaire !
