
Dans ce guide, vous apprendrez
- Deux façons différentes de stocker des données avec Tulip
- Quand utiliser les différentes méthodes de stockage des données
- L'importance d'adopter un modèle de données
Lorsque l'on travaille avec des données, le maintien de l'organisation est crucial pour éviter l'encombrement et centraliser l'information. Avec Tulip, le stockage et la gestion de vos données sont facilités par de multiples options basées sur vos besoins.
Comment les données de Tulip capturent-elles vos opérations ?
Les données existent à plusieurs niveaux dans Tulip.
Les applications stockent des données statiques, comme des instructions textuelles sur une étape.
Lestables sont des bases de données construites par Tulip, comme une feuille de calcul de bons de travail, que vous pouvez utiliser dans plusieurs applications.
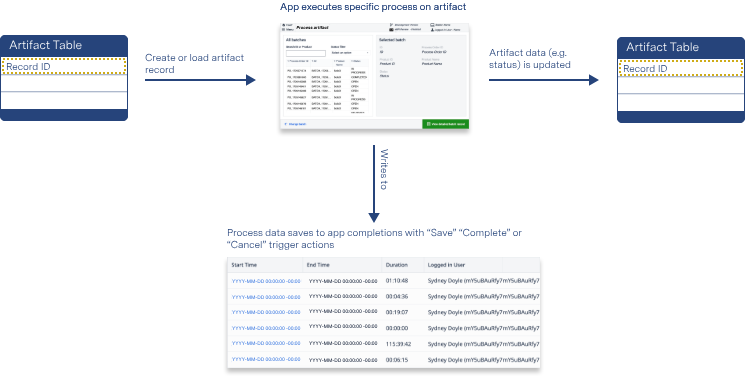
Lesachèvements stockent les métadonnées de production, telles que la durée de l'application, le nom de la station, et toutes les données d'entrée des variables.
Le diagramme ci-dessous montre un flux opérationnel de données à travers un atelier.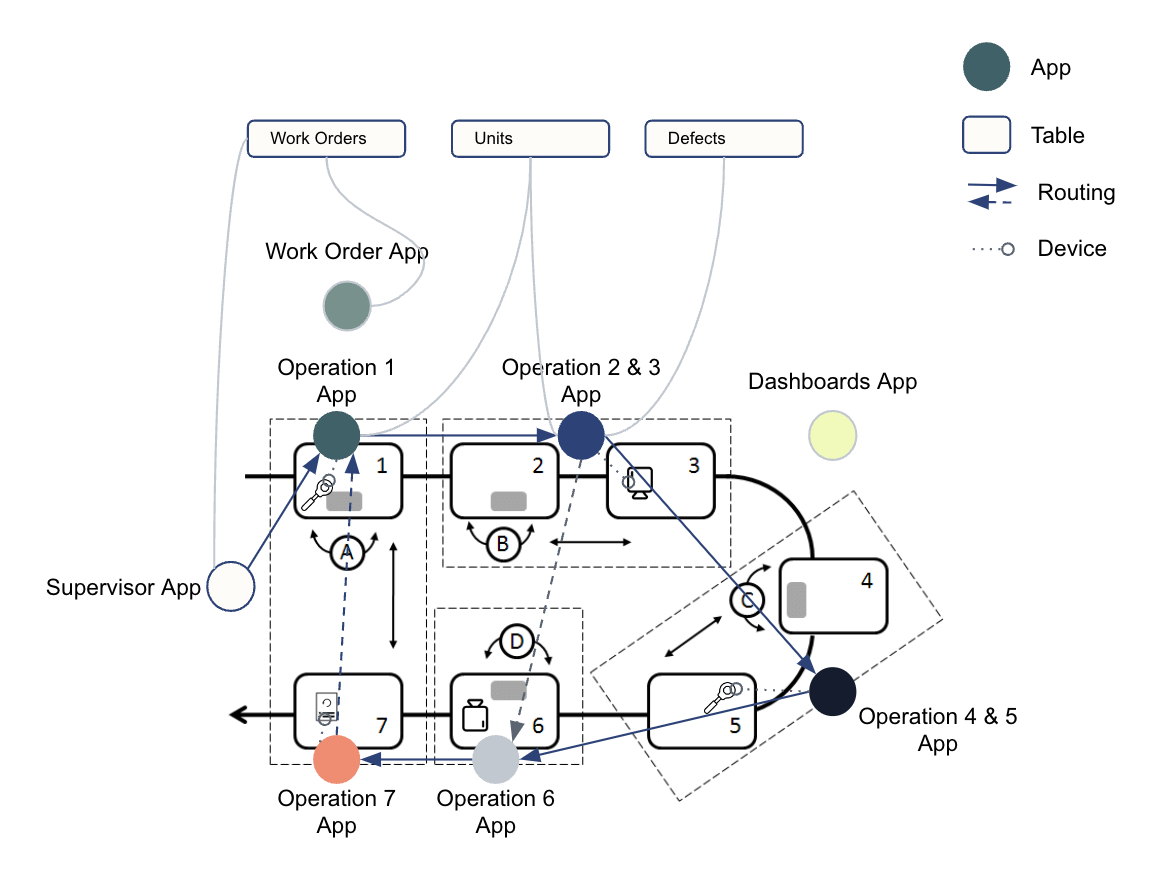
Options de stockage des données
Il y a 2 options pour stocker les données dans Tulip, les Tables et les Complétions.
Tableaux
Les tableaux sont un croisement entre les feuilles de calcul et les bases de données relationnelles qui sont personnalisables en fonction de la façon dont vous souhaitez présenter vos données. Ce sont des sources de données partageables que plusieurs applications peuvent utiliser.
Lors de la construction d'une table, vous créez les Field qui contiennent et organisent les données par enregistrements. Les champs font office de colonnes, les enregistrements sont les lignes de données spécifiques et chaque donnée individuelle est un champ d'enregistrement de tableau.
Les tableaux peuvent être intégrés dans votre application pour créer, modifier et afficher des enregistrements pertinents pour vos tâches.
Vous pouvez importer des données existantes dans les tables Tulip, comme indiqué ici.
Si vous ne souhaitez pas créer votre propre table, mais que vous n'avez pas non plus de données existantes à importer, vous pouvez utiliser l'une des tables préconfigurées de Tulip qui sont chargées dans votre Instance. Celles-ci vous donnent une idée des différents champs que vous pouvez utiliser dans les tables et des types généraux de données qui peuvent être enregistrées. Les options pour les types de données incluent :
- Texte
- Entier
- Nombre
- Booléen
- Date
- Intervalle
- Couleur
- Image
- Vidéo
- Fichier
- Machine
- Enregistrement lié
Chacun de ces champs correspondra aux données utilisées dans votre application. Pour visualiser les enregistrements dans un tableau, naviguez vers l'écran de tableau via votre page d'instance Tulip. Passez votre curseur sur "Apps" et sélectionnez "Tables".
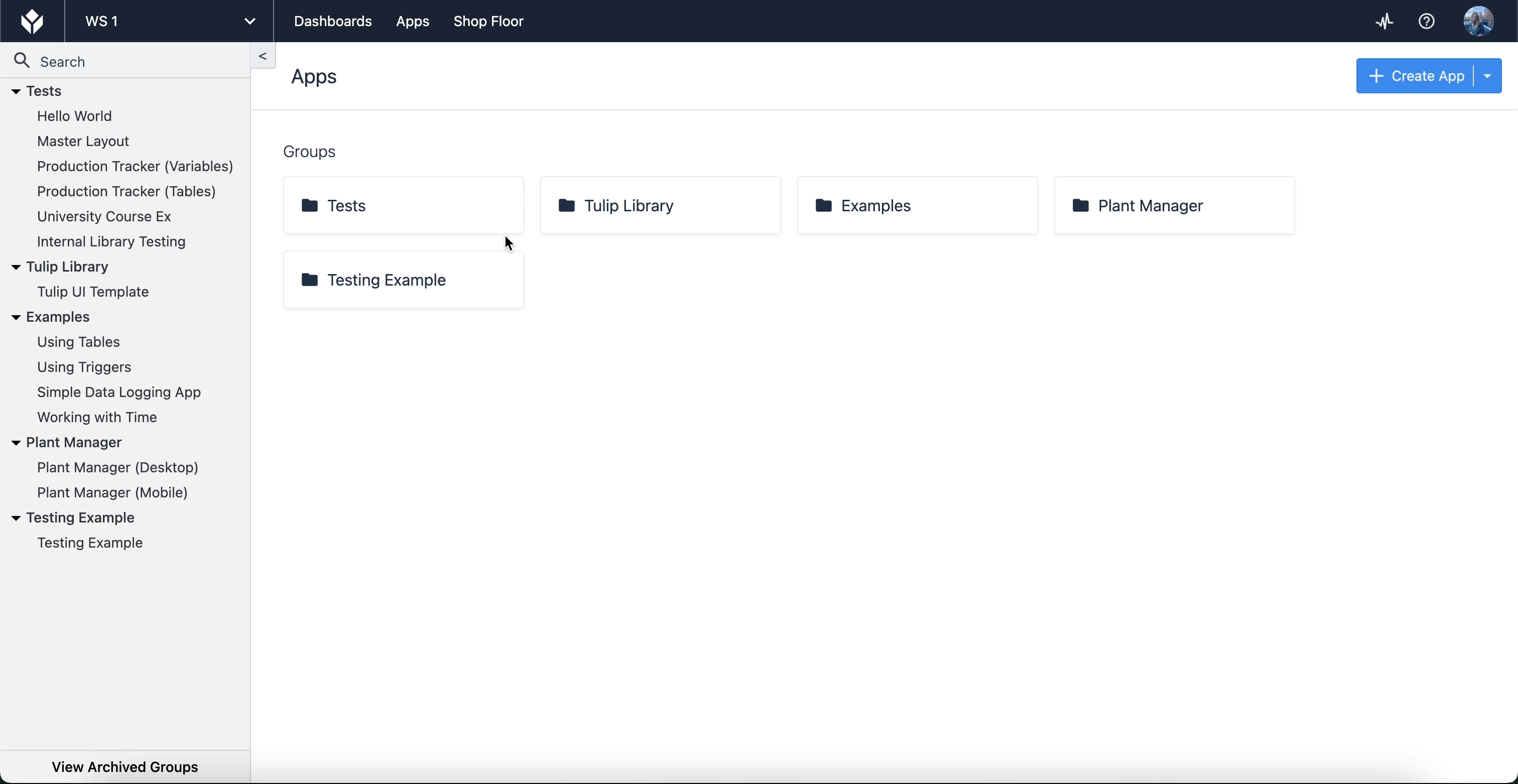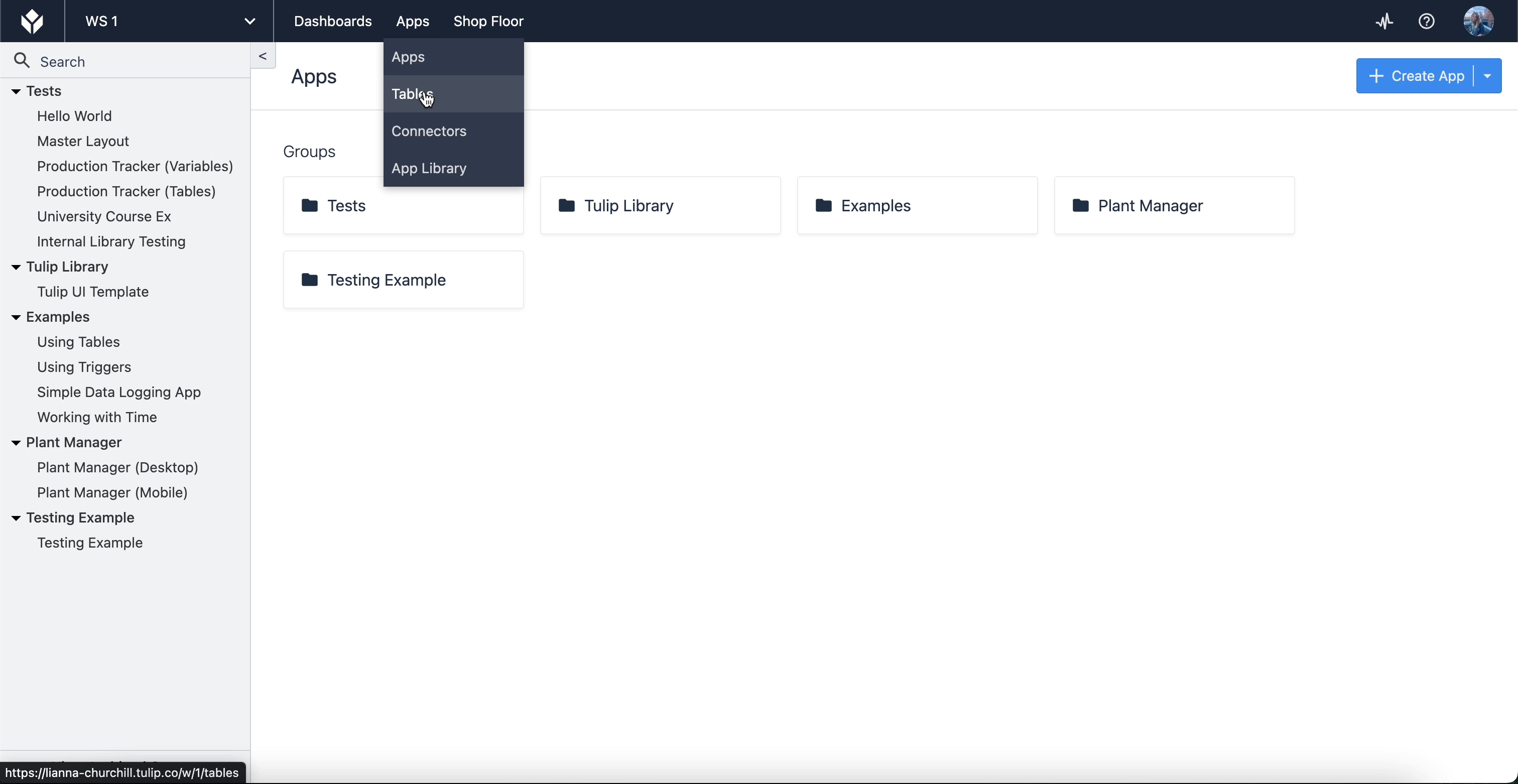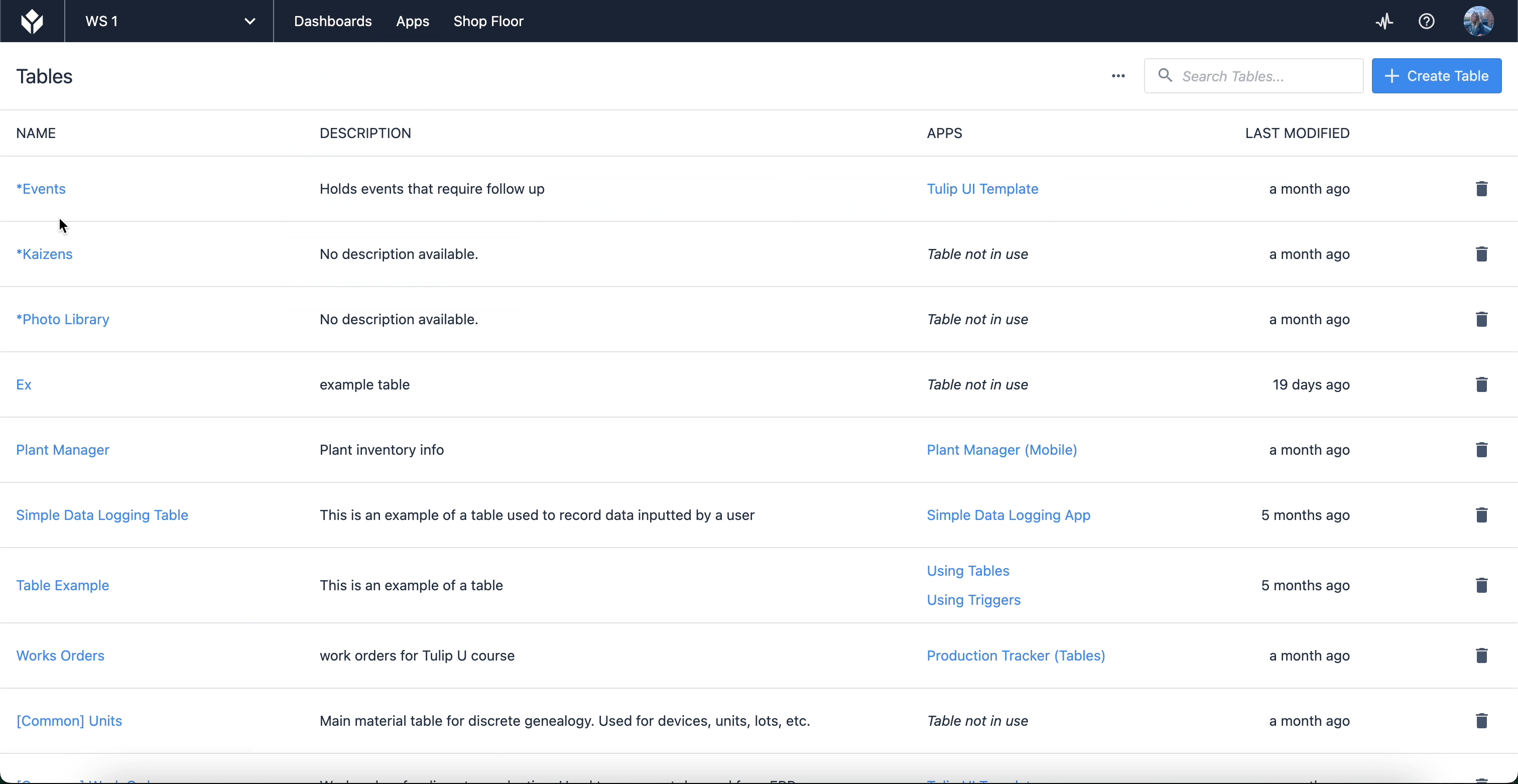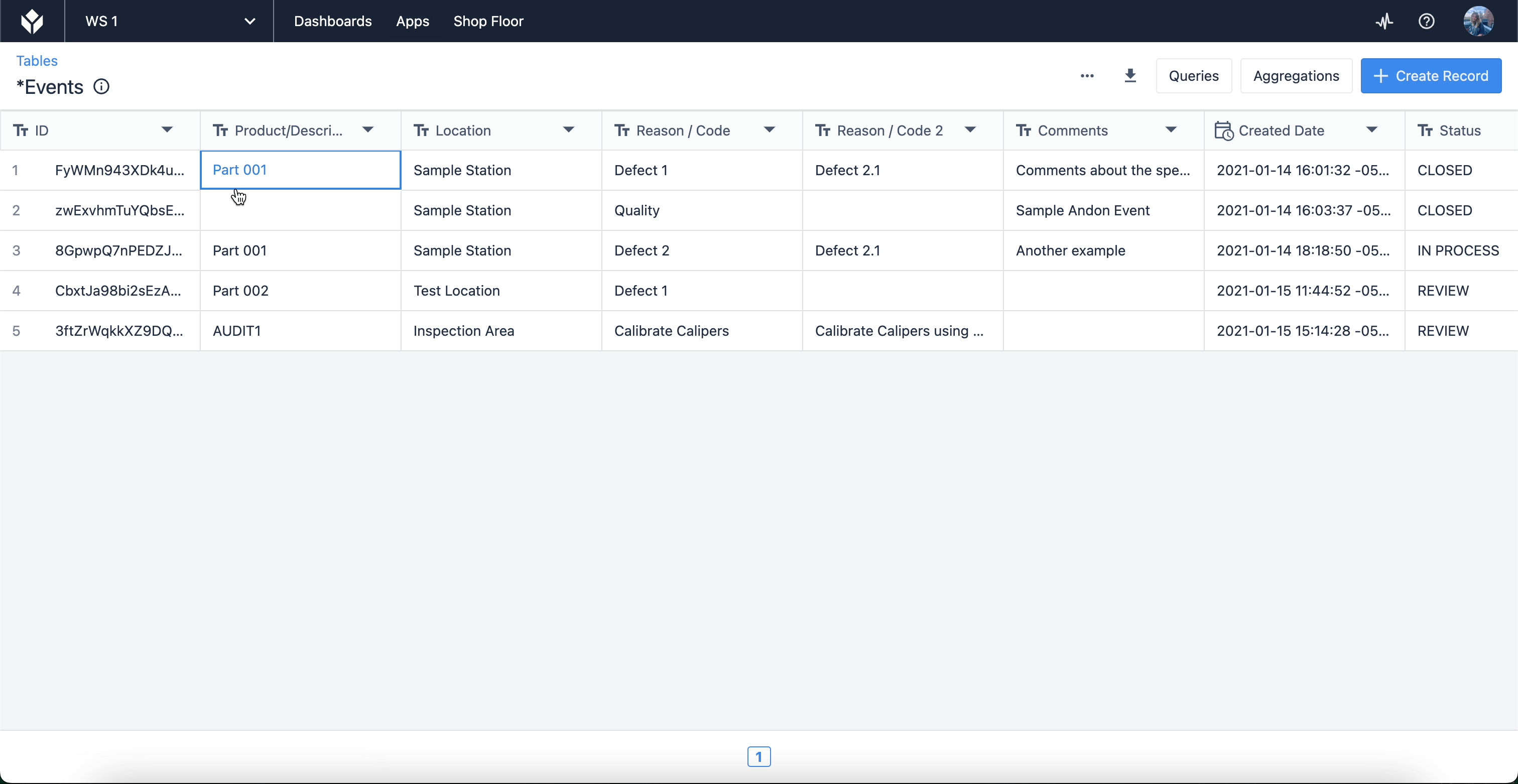
Ici, vous trouverez une liste de tables que vous avez créées ou auxquelles vous avez accès pour les utiliser dans vos applications. Lorsque vous sélectionnez une table, vous pouvez modifier les champs et les enregistrements eux-mêmes, ainsi que créer des requêtes et des agrégations qui vous permettent d'exploiter les données de la table dans les applications. Les tables peuvent également être liées les unes aux autres (pour des cas d'utilisation tels que la généalogie des produits).
Utilisation recommandée des tables Tulip
Tulip recommande d'utiliser les tables pour stocker, à un haut niveau, deux types d'artefacts différents : physiques et opérationnels.
Lesartefacts****physiques sont des objets tangibles ou des composants qui sont utilisés ou produits pendant les opérations, tels que les lots ou les équipements. Lesartefacts opérationnels sont des éléments non-physiques ou des composants qui permettent ou supportent les opérations, tels que les événements de défauts ou la configuration kanban.
Pour en savoir plus sur l'utilisation des tableaux, voir
Complétions
Les compléments d'application sont idéaux pour stocker et organiser les données de production. Des champs de métadonnées sont automatiquement générés et stockés lorsqu'un utilisateur termine ou annule l'application. Ces champs comprennent
- Durée de l'application
- Heure de début et de fin
- Utilisateur connecté
- Nom de la station
- Commentaires
- Version de l'application
- ID d'exécution
- Annulé (si l'application a été annulée ou non)
Contrairement aux données stockées dans les tableaux, les données stockées dans les applications terminées ne peuvent pas être modifiées. Cela garantit que l'information est absolue, qu'elle ne peut pas être manipulée ou modifiée et qu'elle reflète fidèlement l'utilisation de l'application.
Les données d'achèvement ne peuvent être utilisées que par une seule application et sont également moins accessibles à partir de systèmes externes.
Pour accéder aux données d'utilisation, sélectionnez une application dans un groupe d'applications dans votre instance de Tulip. Une fois sur l'écran principal de l'application, sélectionnez l'onglet "Achèvements".
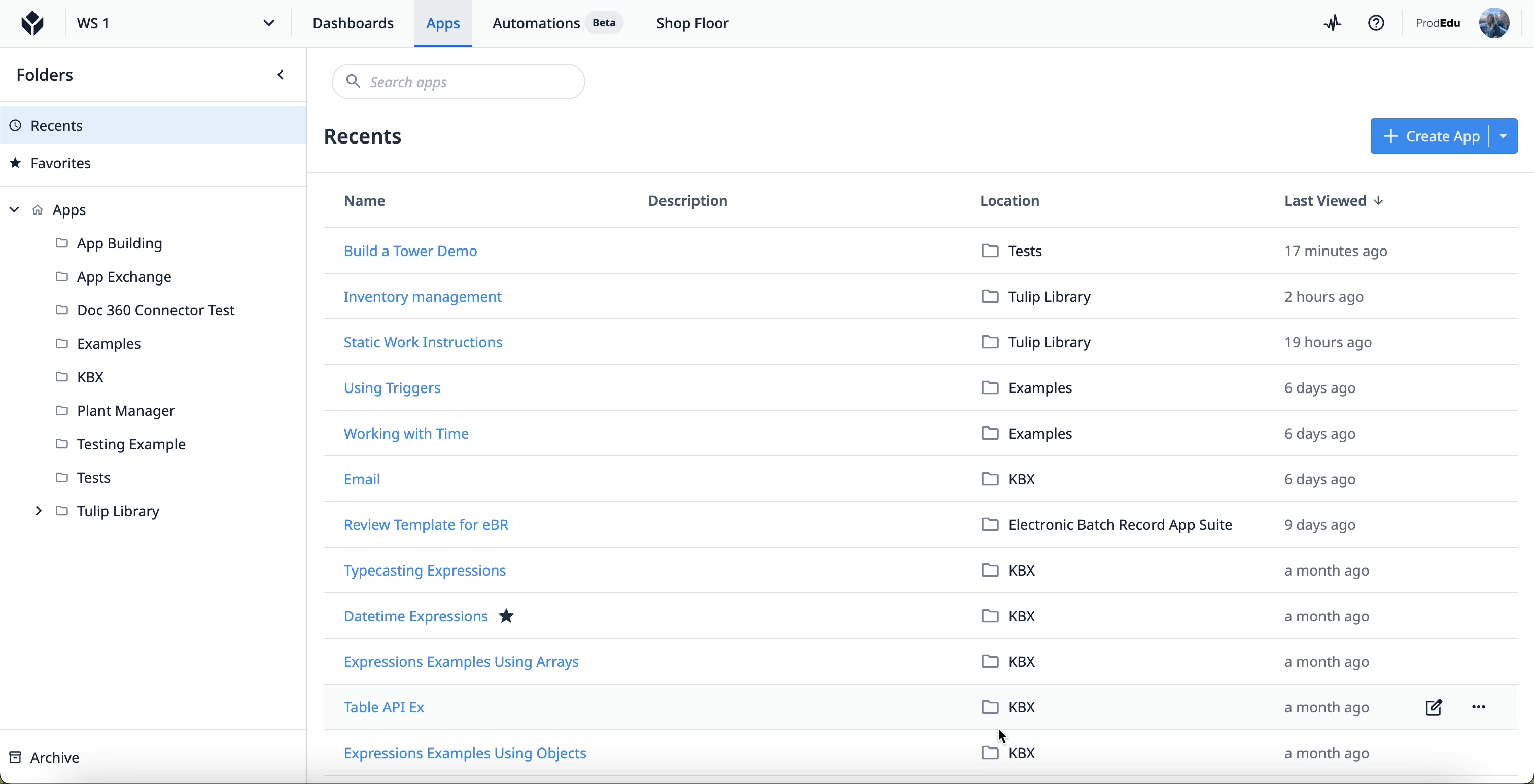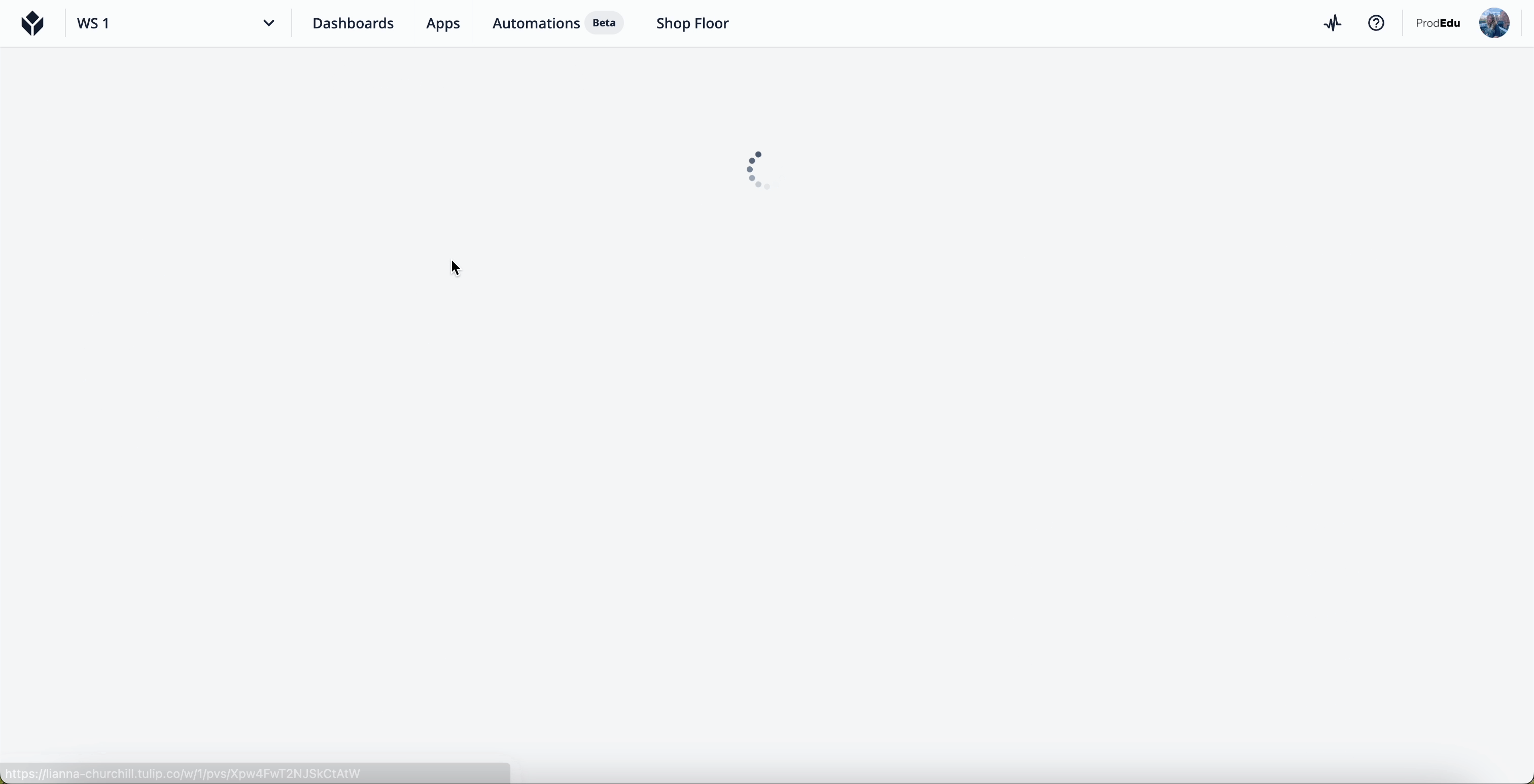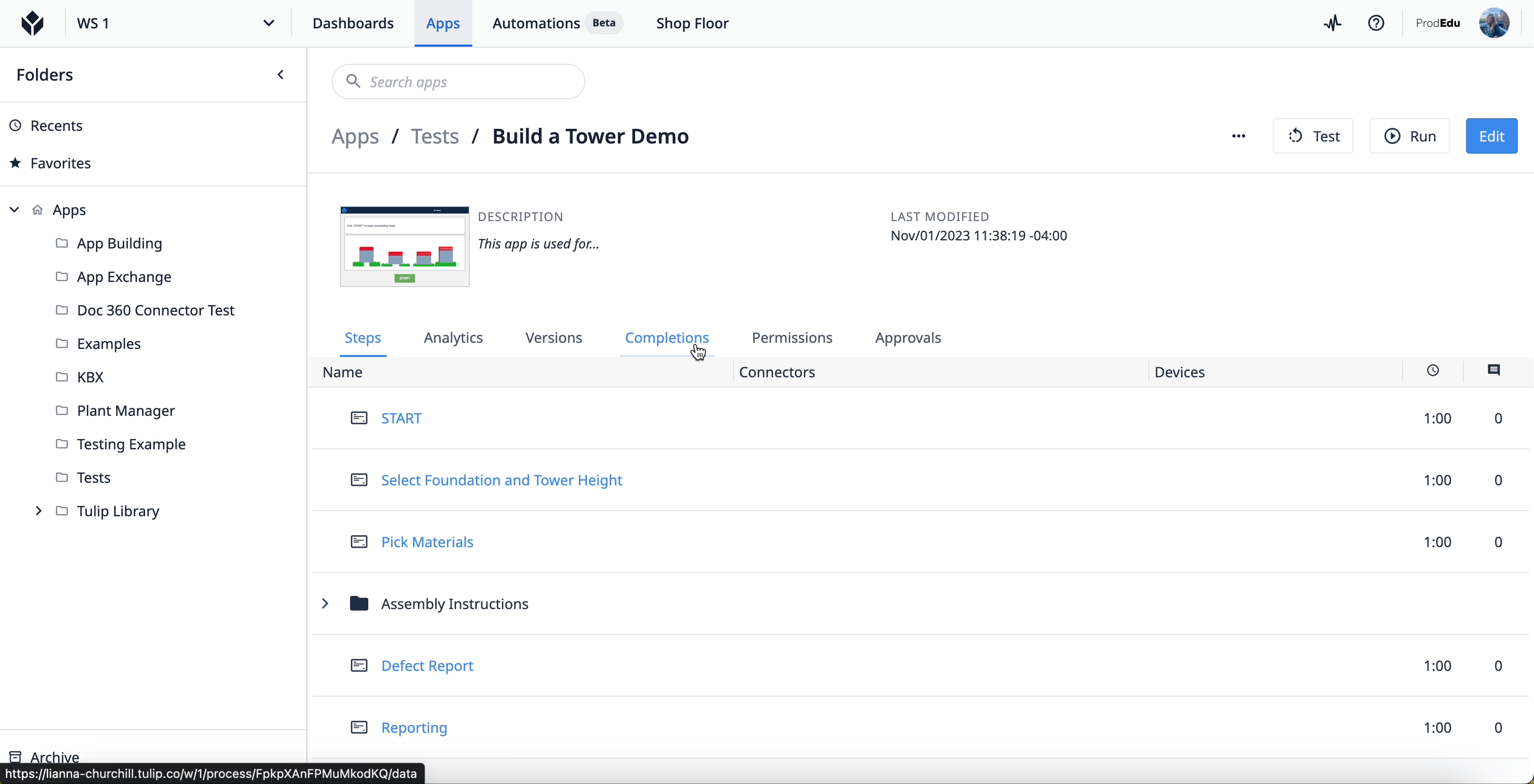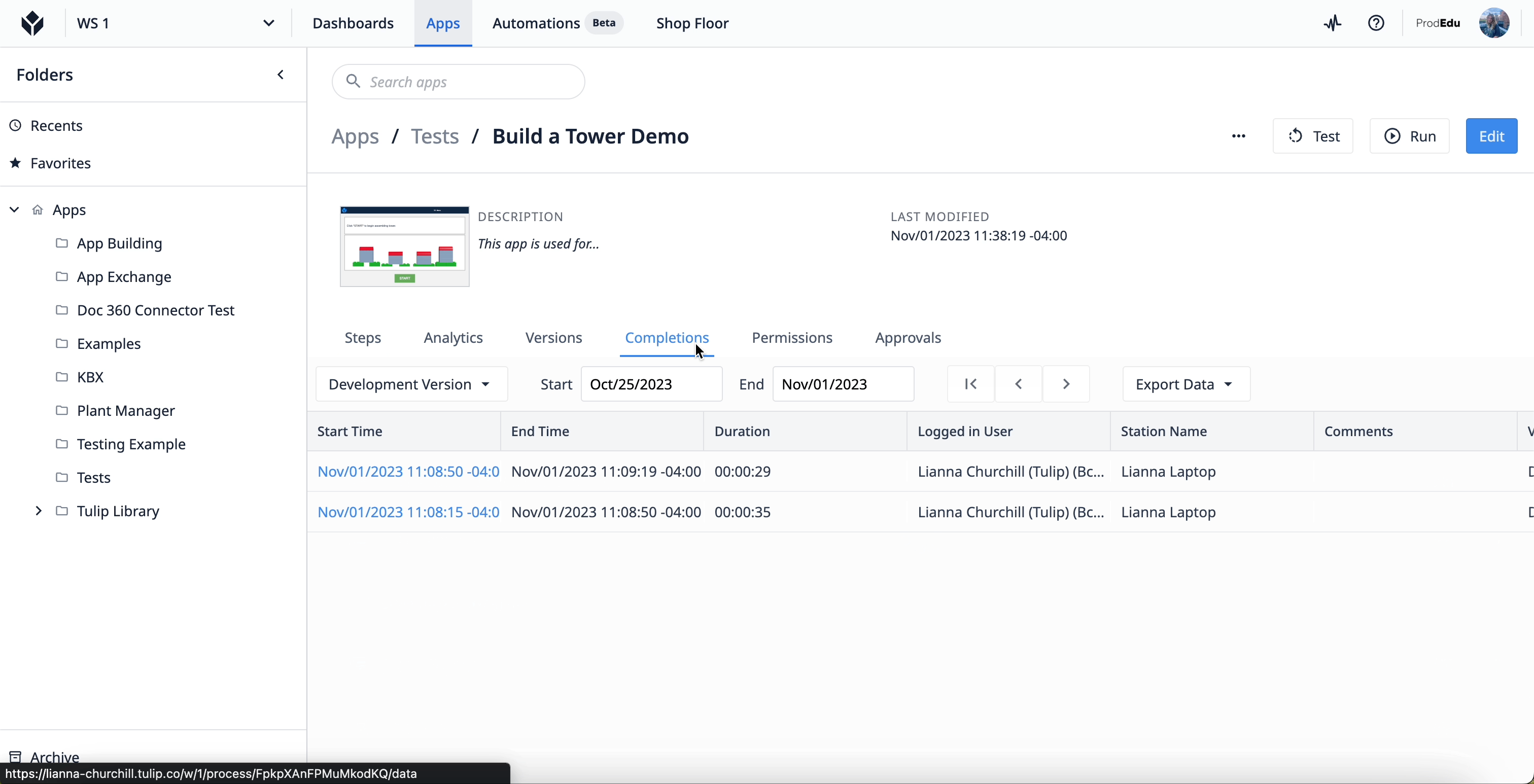
Pour en savoir plus sur les achèvements , cliquez ici.
Tables vs complétions
Les complétions étant stockées automatiquement dans les données de l'application, vous pouvez vous demander s'il ne serait pas préférable de créer une table pour les données.
Les données de complétion sont immuables, alors que les champs des tables sont créés en fonction de vos besoins. Les données des tables sont également écrites à partir de votre application en fonction des déclencheurs et des variables que vous avez définis ; cependant, les données d'achèvement ne sont écrites que lorsqu'un utilisateur termine ou annule l'application. Alors que les données d'achèvement offrent une facilité et une automatisation instantanée, les données de tableau peuvent être rendues uniques à votre application et offrent la flexibilité d'utiliser les données dans plusieurs applications.
Meilleures pratiques de stockage des données
Le stockage des données étant personnalisable en fonction de vos opérations, il existe de nombreuses façons de mettre en place des structures de données. Tulip recommande plusieurs pratiques pour s'assurer que vous construisez des tables et stockez des données avec les objectifs suivants :
- Les données sont facilement accessibles
- Les données sont visibles par les personnes et les systèmes nécessaires
- Les données sont centralisées et ne sont pas dupliquées ailleurs.
Pour en savoir plus sur les meilleures pratiques de Tulip pour le stockage des données , cliquez ici.
Appliquer un modèle de données
Tulip dispose d'un modèle de données commun pré-construit pour répondre à de multiples cas d'utilisation, afin que vous puissiez l'adopter et l'adapter à vos besoins spécifiques :
- Modèle de données commun pour les cas d'utilisation discrets
- Modèle de données commun pour les cas d'utilisation pharmaceutiques
Dans Tulip, un modèle de données commun est une collection de tables définies qui sont suffisamment flexibles pour partager des données à travers une solution d'applications.
Les diagrammes ci-dessous illustrent comment les tables partagent des données communes à travers les applications.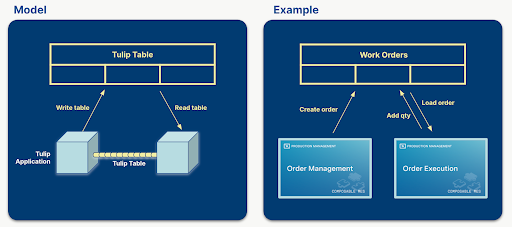
Un modèle de données commun offre des schémas de données normalisés et extensibles, rationalisant le traitement des données entre les systèmes en représentant des concepts largement utilisés (par exemple, les ordres de travail, les unités). Cela simplifie la création, la compilation et l'analyse des données et permet d'améliorer considérablement la gestion des données.
Les tables Tulip devraient principalement suivre le modèle Digital Twin, ce qui signifie que les tables devraient refléter l'usine physique ou l'atelier aussi strictement que possible. Les données d'application historiques doivent être limitées aux dossiers d'achèvement afin de s'assurer que les tables ne stockent pas de données de base ou ne dupliquent pas des données provenant de dossiers d'achèvement ou d'enregistrements externes.
Pour en savoir plus sur l'utilisation d'un modèle de données commun , cliquez ici.
Suivez le cours sur le modèle de données commun sur Tulip University ici.
Utiliser les données dans les applications
Pour afficher, modifier ou saisir des données de tableau dans vos applications, vous devez d'abord vous familiariser avec les Widgets. {Les Widgets de saisie vous permettent de modifier et de saisir des données qui s'afficheront dans votre tableau. Les widgets intégrés affichent vos informations et peuvent être configurés pour que vous puissiez interagir avec vos tableaux. Pour un tutoriel complet sur l'incorporation de données dans les tableaux, voir :
- Travailler avec des tableaux dans une application
- Plongée en profondeur dans les fonctionnalités : Tableaux Tulip
Les données d'achèvement peuvent être affichées dans vos applications par l'intermédiaire d'Analytics. Vous devrez d'abord créer une analyse à l'aide de vos données d'achèvement, puis intégrer cette analyse dans votre application.
Pour en savoir plus sur l'utilisation des données d'achèvement pour créer une analyse, voir ici.
Comment Tulip stocke vos données
Tulip étant une plateforme libre-service, vous pouvez déterminer quelles données sont transmises et stockées. Tulip Cloud stocke vos données sur AWS, en utilisant une base de données MongoDB ou PostgreSQL. Tulip télécharge automatiquement toutes les images, vidéos et PDF vers le stockage S3 d'Amazon, vous évitant ainsi de vous préoccuper de la gestion du stockage ou du suivi de vos données collectées.
Prochaines étapes
Commencez à travailler avec des données grâce aux conseils des experts de Tulip:* Walkthrough : Construisez votre première table* Cours de l'Université Travailler avec des données et des tableaux* Comprendre les complétions d'applications et le guide de l'Université des tableaux* Intégrer avec des systèmes externes
Vous avez trouvé ce que vous cherchiez ?
Vous pouvez également vous rendre sur community.tulip.co pour poser votre question ou voir si d'autres ont rencontré une question similaire !
.gif)