
Interroger les tables Tulip avec un script ETL Glue pour simplifier le transfert de données de Tulip vers Redshift (ou d'autres nuages de données)
Objectif
Ce script fournit un point de départ simple pour interroger les données des tables Tulip et les déplacer vers Redshift ou d'autres entrepôts de données.
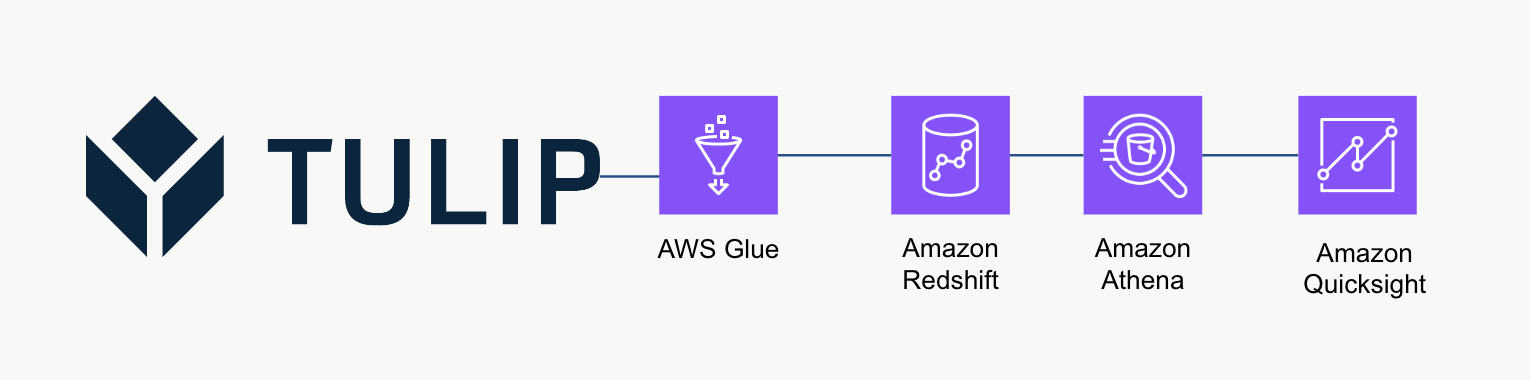
Architecture de haut niveau
Cette architecture de haut niveau peut être utilisée pour interroger des données à partir de l'API Tulip Tables, puis sauvegardées sur Redshift pour une analyse et un traitement ultérieurs.
Exemple de script
L'exemple de script ci-dessous montre comment interroger une seule table Tulp avec Glue ETL (Python Powershell) et ensuite écrire dans Redshift. REMARQUE : Pour les cas d'utilisation de production à grande échelle, il est recommandé d'écrire dans un godet S3 temporaire et de copier ensuite le contenu du godet dans S3. En outre, les informations d'identification sont sauvegardées via AWS Secrets Manager.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name) : # Créer un client Secrets Manager session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try : get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e : # Pour une liste des exceptions lancées, voir # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# Construire le moteur SQL
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0 : offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# capture de la date et de l'heure
now = datetime.now() df['date\_updated'] = now
# écrire dans Redshift
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
Considérations sur l'échelle
Envisagez d'utiliser S3 comme stockage temporaire intermédiaire pour ensuite copier les données de S3 vers Redshift au lieu de les écrire directement dans Redshift. Cela peut s'avérer plus efficace en termes de calcul.
En outre, vous pouvez également utiliser les métadonnées pour écrire toutes les tables Tulip dans un entrepôt de données au lieu de tables Tulip uniques.
Enfin, cet exemple de script écrase la totalité de la table à chaque fois. Une méthode plus efficace consisterait à mettre à jour les lignes modifiées depuis la dernière mise à jour ou requête.
Prochaines étapes
Pour en savoir plus, consultez le document Amazon Well-Architected Framework. Il s'agit d'une excellente ressource pour comprendre les méthodes optimales pour les flux de données et les intégrations.