
Rationaliser l'extraction des données de Tulip vers AWS pour élargir les possibilités d'analyse et d'intégration.
Objectif
Ce guide explique étape par étape comment récupérer toutes les données de Tulip Tables sur AWS via une fonction Lambda.
Cela va au-delà de la requête de base de récupération et itère à travers toutes les tables dans une instance donnée ; cela peut être utile pour un travail ETL hebdomadaire (Extraire, Transformer, Charger).
La fonction Lambda peut être déclenchée par l'intermédiaire de diverses ressources telles que des minuteries Event Bridge ou une passerelle API.
Un exemple d'architecture est présenté ci-dessous :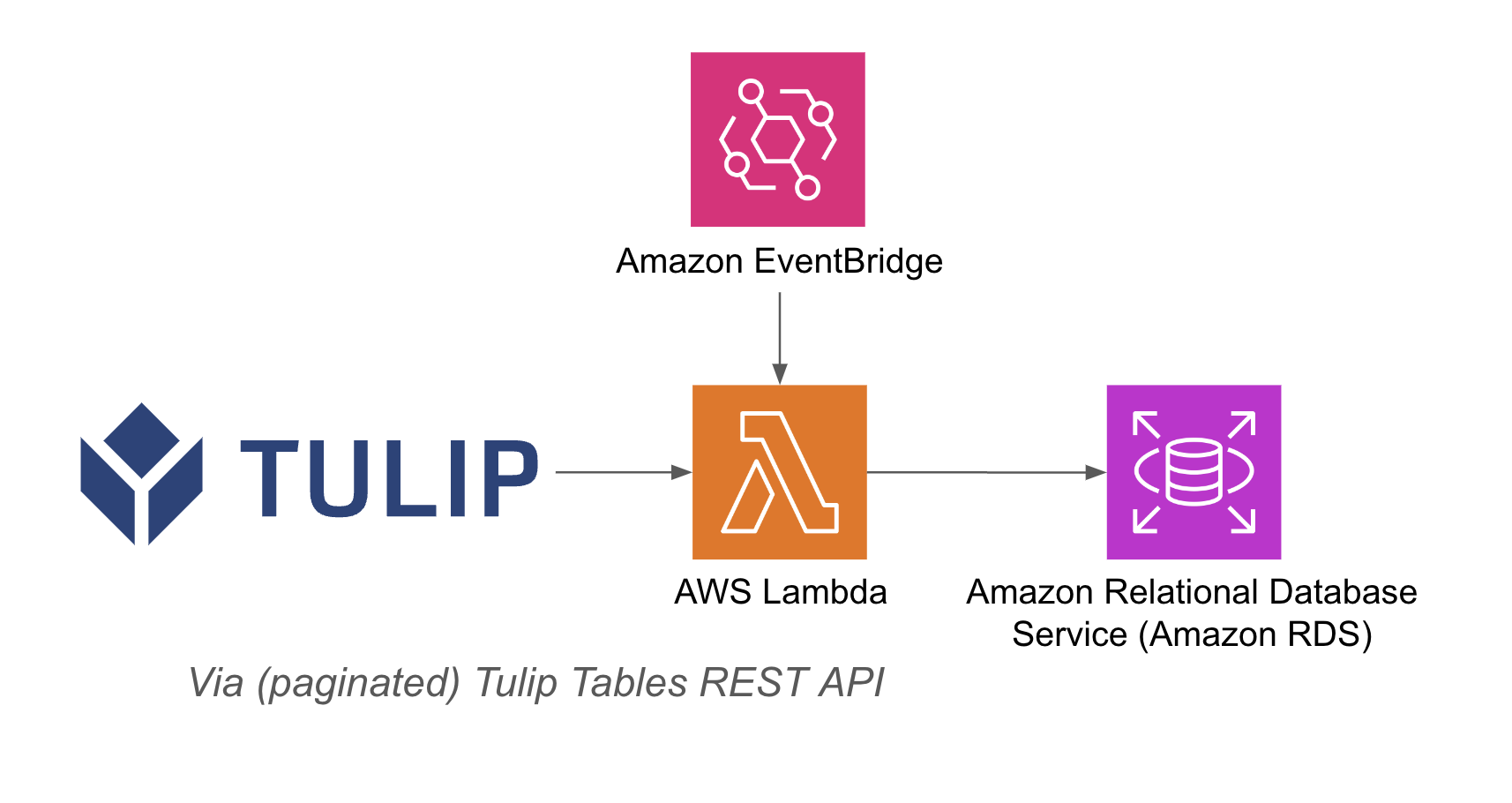
Configuration
Cet exemple d'intégration nécessite les éléments suivants
- Utilisation de l'API Tulip Tables (Obtenir la clé API et le secret dans les paramètres du compte)
- Tulip Table (Obtenir l'ID unique de la table)
Étapes de haut niveau : 1. Créer une fonction AWS Lambda avec le déclencheur approprié (API Gateway, Event Bridge Timer, etc.) 2. Récupérer les données de la table Tulip avec l'exemple ci-dessous ``python import json import pandas as pd import requests from sqlalchemy import create_engine import os
def lambda_handler(event, context) : # initialize db host = os.getenv('host') user = os.getenv('username') password = os.getenv('password') db = os.getenv('database')
engine_str = f'postgresql://{user}:{password}@{host}/{db}' engine = create_engine(engine_str) api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) df = pd.DataFrame(r.json()) # Fonction pour convertir les dictionnaires en chaînes def dict_to_str(cell) : if isinstance(cell, dict) : return str(cell) return cell # fonction de requête de table def query_table(table_id, base_url, api_header) : offset = 0 function = f'/tables/{table_id}/records ?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0 : offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row : row.apply(dict_to_str), axis=1) return df # create function def write_to_db(row, base_url, api_header) : table = row['label'] id = row['id'] df = query_table(id, base_url, api_header) df.to_sql(table,engine, if_exists='replace', index=False) print(f'wrote {table} to database!') # iterate through all tables : df.apply(lambda row : write_to_db(row, base_url, api_header), axis=1) return { 'statusCode' : 200, 'body' : json.dumps('written to db!')}
## Cas d'utilisation et prochaines étapes
Une fois que vous avez finalisé l'intégration avec lambda, vous pouvez facilement analyser les données avec un sagemaker notebook, QuickSight, ou une variété d'autres outils.
**1. Prédiction des**défauts - Identifier les défauts de production avant qu'ils ne se produisent et augmenter la qualité dès la première fois - Identifier les principaux facteurs de production de la qualité afin de mettre en œuvre des améliorations.
**2. Optimisation du coût de la qualité**- Identifier les possibilités d'optimisation de la conception des produits sans incidence sur la satisfaction des clients.
**3. Optimisation de l'énergie de production**- Identifier les leviers de production pour optimiser la consommation d'énergie
**4. Prévision et optimisation des livraisons et de la planification**- Optimiser le calendrier de production en fonction de la demande des clients et du calendrier des commandes en temps réel.
**5. Benchmarking global des machines / lignes**- Benchmarker des machines ou équipements similaires avec normalisation.
**6. Gestion de la performance numérique globale / régionale**- Consolidation des données pour créer des tableaux de bord en temps réel.