

Przewodnik po szablonie uniwersalnym i optymalizacji korzystania z funkcji.
Szablon Universal Template to pojedyncze środowisko do płynnego tworzenia analiz. Umożliwia przełączanie się między typami wizualizacji poprzez oddzielenie zapytań i wizualizacji danych. Universal Template obsługuje wszystkie typy analiz i źródła danych Tulip (Completions, Table data i Machine data).

Korzystanie z zapytań i wizualizacji
Zapytanie jest jak instrukcja, którą przekazujesz systemowi, określając, co chcesz, aby zrobił z "surowymi" danymi z aplikacji, urządzenia lub tabeli Tulip. Wynikiem zapytania jest tabelaryczna reprezentacja danych utworzona przez Tulip Analytics w oparciu o sposób skonfigurowania zapytania. Zapytanie konfiguruje się w lewym panelu bocznym Edytora Analytics.
Dane z tego zapytania można wizualizować za pomocą różnych wizualizacji, pokazujących wszystkie lub tylko wybrane ich części. Wizualizacja jest wybierana w górnej części Edytora analitycznego i dalej konfigurowana w prawym panelu bocznym Edytora analitycznego.
Wynik zapytania można zawsze zobaczyć poniżej wizualizacji po kliknięciu opcji Pokaż wynik zapytania, chyba że wybrano wizualizację "Tabela".
Tworzenie zapytania
Źródło danych
Źródło danych jest tym, na czym opiera się analiza. Możesz wybrać dane ukończenia aplikacji, dane tabeli lub dane maszyny.
Jeśli tworzysz analizę dla danych ukończenia aplikacji, możesz wybrać wiele aplikacji. Spowoduje to uwzględnienie w analizie rekordów ukończenia ze wszystkich wybranych aplikacji.
Należy pamiętać, że w przypadku wybrania wielu aplikacji dane nie zostaną połączone, ale każde ukończenie będzie traktowane jako osobny wiersz. Oznacza to, że będzie można wspólnie analizować "pola" ukończeń (np. użytkownik, czas rozpoczęcia i stacja). Inne dane, takie jak zmienne aplikacji, będą traktowane oddzielnie dla każdej aplikacji i będą miały wartość "null" jako wartość dla rekordów ukończenia wszystkich innych aplikacji.
Jeśli tworzysz analizę dla urządzeń, możesz wybrać jeden lub wiele typów urządzeń. Jeśli chcesz utworzyć analizę dla określonego urządzenia, dodaj dodatkowy filtr.
Grupowania i operacje
Grupowania i operacje to podstawowe obszary tworzenia zapytań. To tutaj definiujesz, które z opcji danych chcesz wyświetlić i w jakiej formie.
Grupowania
Grupowanie daje instrukcję, aby połączyć grupy w jak największym stopniu. Jeśli znasz funkcję GROUP BY w popularnych narzędziach QL i BI, proces grupowania zachowuje się niemal identycznie. Grupowania określają pola i typy danych w celu znalezienia podobnych wartości. Umożliwiają one uzyskanie coraz bardziej szczegółowego widoku danych, które chcesz zobaczyć.
Grupowania dają większą kontrolę nad określaniem, które wiersze powinny być łączone. Grupowanie może być dowolnym polem dowolnego typu. W zależności od tego, jakie operacje zostały skonfigurowane, dodanie jednego lub wielu grupowań doprowadzi do różnych wyników.
Przyjrzyjmy się kilku kombinacjom grupowania.
| | Jedno grupowanie | Wiele grupowań | | --- | --- | --- | Tylko odrębne wartości | Jeden wiersz dla każdego wiersza w danych źródłowych pokazujący wartości dla pola grupowania i odrębne wartości dla tego wiersza | Jeden wiersz dla każdego wiersza w danych źródłowych pokazujący wartości dla pól grupowania i odrębne wartości dla tego wiersza | Tylko agregacje | Jeden wiersz dla każdego odrębnego wpisu w polu grupowania z tą wartością grupowania i zagregowane wartości wszystkich wierszy z danych źródłowych z tą wartością grupowania | Jeden wiersz dla każdego odrębnego wpisu w polu grupowania z tą wartością grupowania i zagregowane wartości wszystkich wierszy z danych źródłowych z tą wartością grupowania | Jeden wiersz dla każdego odrębnego wpisu w polu grupowania z tą wartością grupowania Wartość grupowania | Jeden wiersz dla każdej kombinacji pól grupowania z odrębnymi wpisami z odpowiednimi wartościami dla grupowania i zagregowanymi wartościami wszystkich wierszy z danych źródłowych z odpowiednimi wartościami grupowania | | Wartości odrębne i agregacje | Jeden wiersz dla każdego wiersza w danych źródłowych pokazujący wartości grupowania i wartości odrębne oraz zagregowane wartości wszystkich wierszy z danych źródłowych z tą wartością grupowania (tj. zagregowane wartości są wartościami grupowania).zagregowane wartości są takie same we wszystkich wierszach z tą samą wartością grupowania) | Jeden wiersz dla każdego wiersza w danych źródłowych pokazujący wartości grupowania i zagregowane wartości wszystkich wierszy z danych źródłowych z odpowiednimi wartościami grupowania (tj. zagregowane wartości są takie same we wszystkich wierszach z tymi samymi wartościami grupowania).
Ważne jest, aby pamiętać, że dane będą wyświetlane tylko wtedy, gdy istnieje wiersz z odpowiednimi informacjami. Jeśli w danych źródłowych nie ma danych dla określonego dnia, analiza będzie pusta.
Przyjrzyjmy się przykładowi działania grupowania: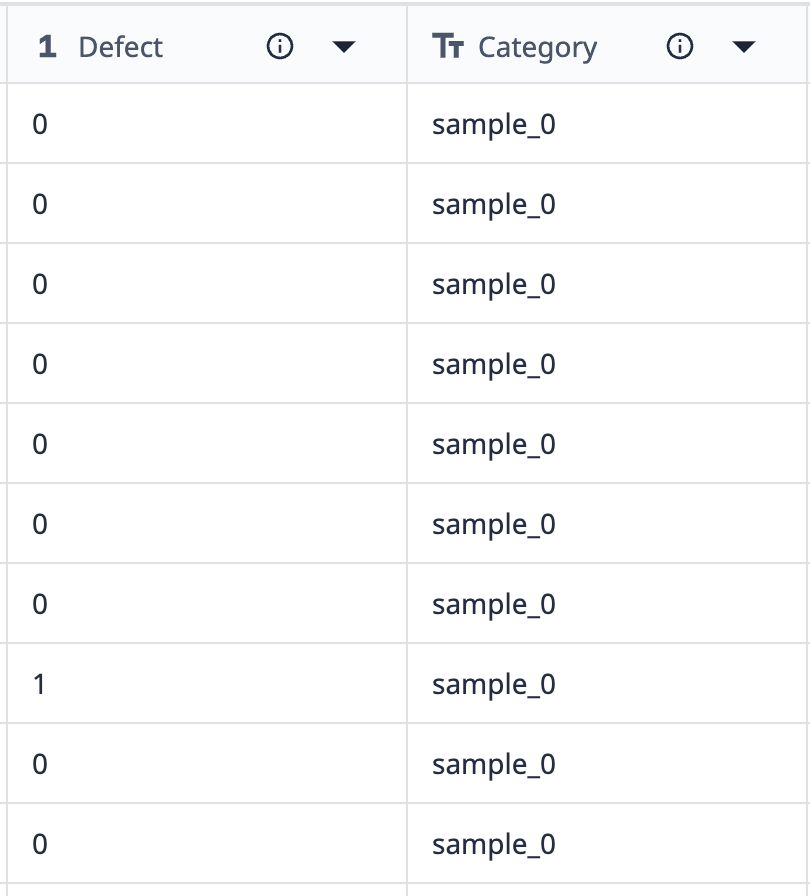
Dane z tej tabeli pokazują, że istnieje 10 rekordów oznaczonych jako "sample_0". Jeśli chcemy pogrupować te dane w wizualizację, która pokazuje tylko różne punkty sample_0, w których liczba defektów jest różna, możemy użyć grupowania, aby połączyć podobne zestawy danych.
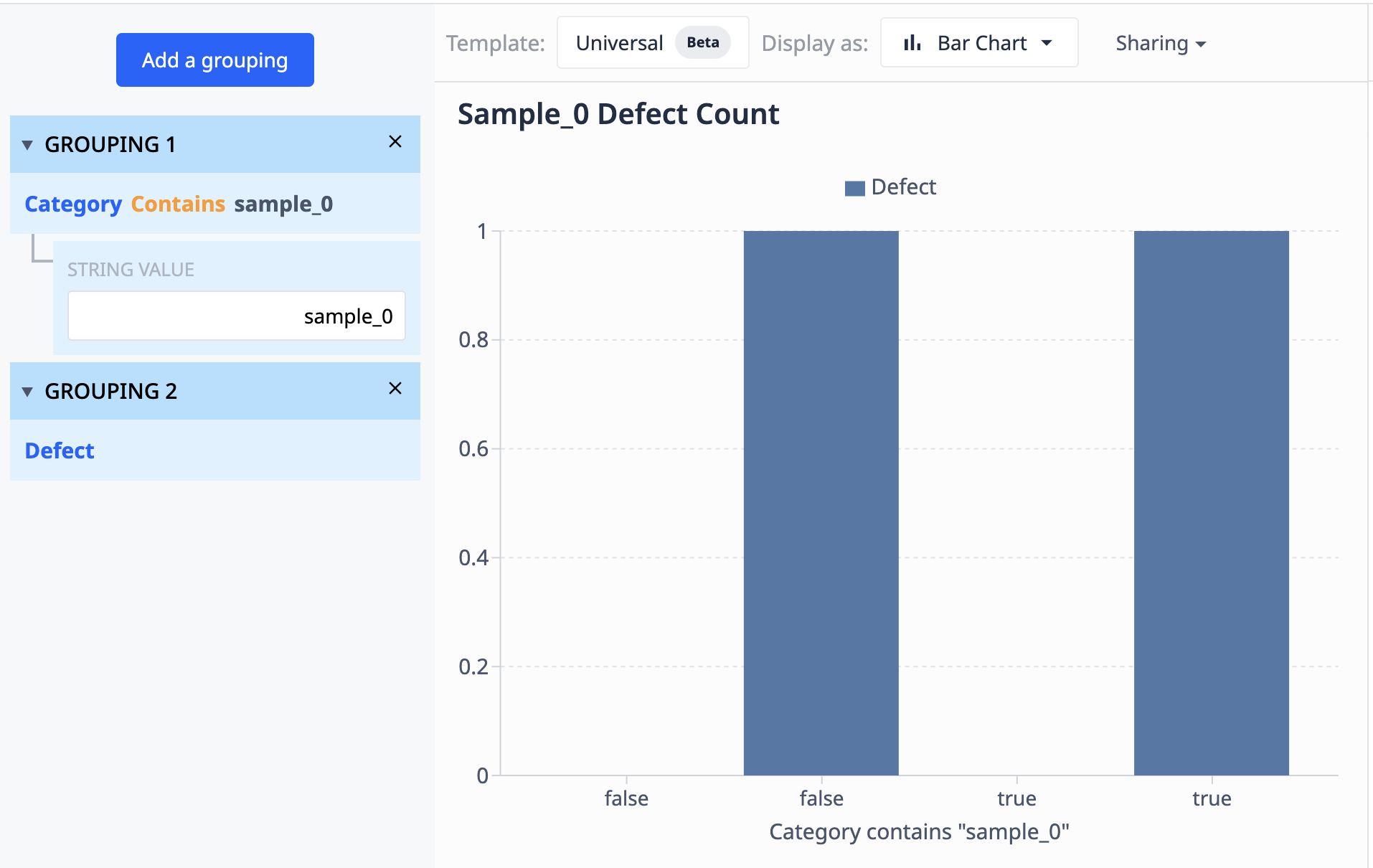
Operacje
Operacje mogą być albo agregacją, która łączy wiele rekordów, albo polem, które tego nie robi.
Operacje dzielą się na dwie ogólne kategorie: 1. Wartości odrębne Wartości odrębne reprezentują poszczególne punkty danych z danych źródłowych. W najprostszym przypadku jest to jedna wartość zmiennej z rekordu ukończenia, pole z tabeli lub atrybut maszyny.
Ale może to być również bardziej zaawansowany punkt danych, taki jak suma dwóch pól z tego samego rekordu, kombinacja wielu ciągów lub wyrażenie, które nie zawiera funkcji agregacji.
Używając tabeli zawierającej pole wartości (numeryczne) i pole znaczników czasu (datetime), możemy wizualizować wartości według znacznika czasu, aby wyglądały tak:
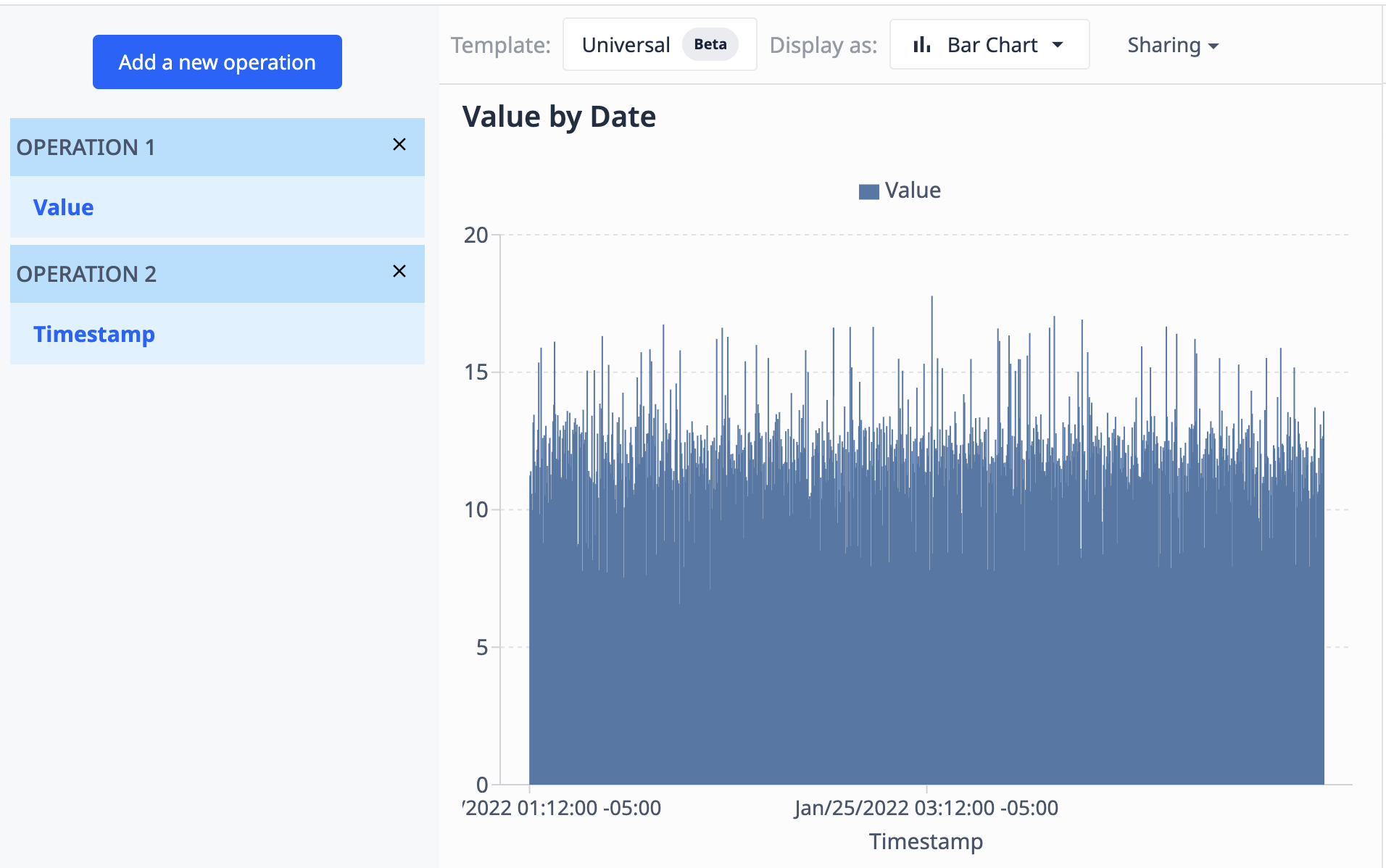
- Agregacje
Agregacje to funkcje, które pobierają dane z wielu wierszy i łączą je w oparciu o ustaloną logikę. Istnieje zestaw funkcji agregacji dostępnych jako wstępnie skonfigurowane wybory lub można również użyć funkcji agregacji w edytorze wyrażeń, aby utworzyć własne zaawansowane agregacje. Różne funkcje agregacji działają dla różnych typów danych. Poniżej przedstawiono dostępne funkcje i obsługiwane przez nie typy danych.
Bezpośrednio dostępne funkcjeagregacji Umożliwiają one łączenie wierszy:
- Średnia
- Mediana
- Suma
- Minimum
- Maksimum
- Tryb
- Odchylenie standardowe
-
- percentyl
-
- percentyl
- Współczynnik
- Uzupełnienie współczynnika
Funkcje agregacji dostępne w edytorze wyrażeń
Funkcje agregacji w edytorze wyrażeń mogą zapewnić bardziej szczegółowe dane w oparciu o określone wymagania. Aby uzyskać pełny przewodnik po wszystkich dostępnych wyrażeniach, których można używać w analizach, zobacz Pełna lista wyrażeń w edytorze analitycznym.
Limit i sortowanie
Możesz zdefiniować maksymalną liczbę wierszy, które zawiera wynik zapytania, dodając limit. Dzięki limitom można skupić się na określonych danych lub ograniczyć ilość danych wyświetlanych na wykresie. Na przykład można dodać limit, aby wyświetlić trzy linie produkcyjne, które miały najwięcej defektów w ciągu ostatniego miesiąca.
Dane sortowania określają, które wiersze są uwzględniane podczas oceny limitu. Możesz dodać sortowanie rosnące lub malejące dla dowolnego pola, które jest częścią wyniku zapytania. Jeśli dodasz wiele pól do sortowania, dane zostaną posortowane według pierwszego z nich. Grupy wynikowe dla każdej wartości pierwszego pola zostaną następnie posortowane według drugiego itd.
Zwróć uwagę, że jeśli nie zdefiniujesz jawnie sortowania, sortowanie wyników zapytania może się różnić w zależności od dostępnych danych. W przypadku korzystania z ograniczania lub wykresów z osiami porządkowymi może to prowadzić do różnych wizualizacji. W takich przypadkach zalecamy dodanie odpowiedniego sortowania.
Poniższy przykład wykorzystuje wykres, który widzieliśmy przy użyciu Operations. Tutaj ograniczamy wyniki do 100 punktów danych i sortujemy je w porządku malejącym na podstawie daty i godziny.
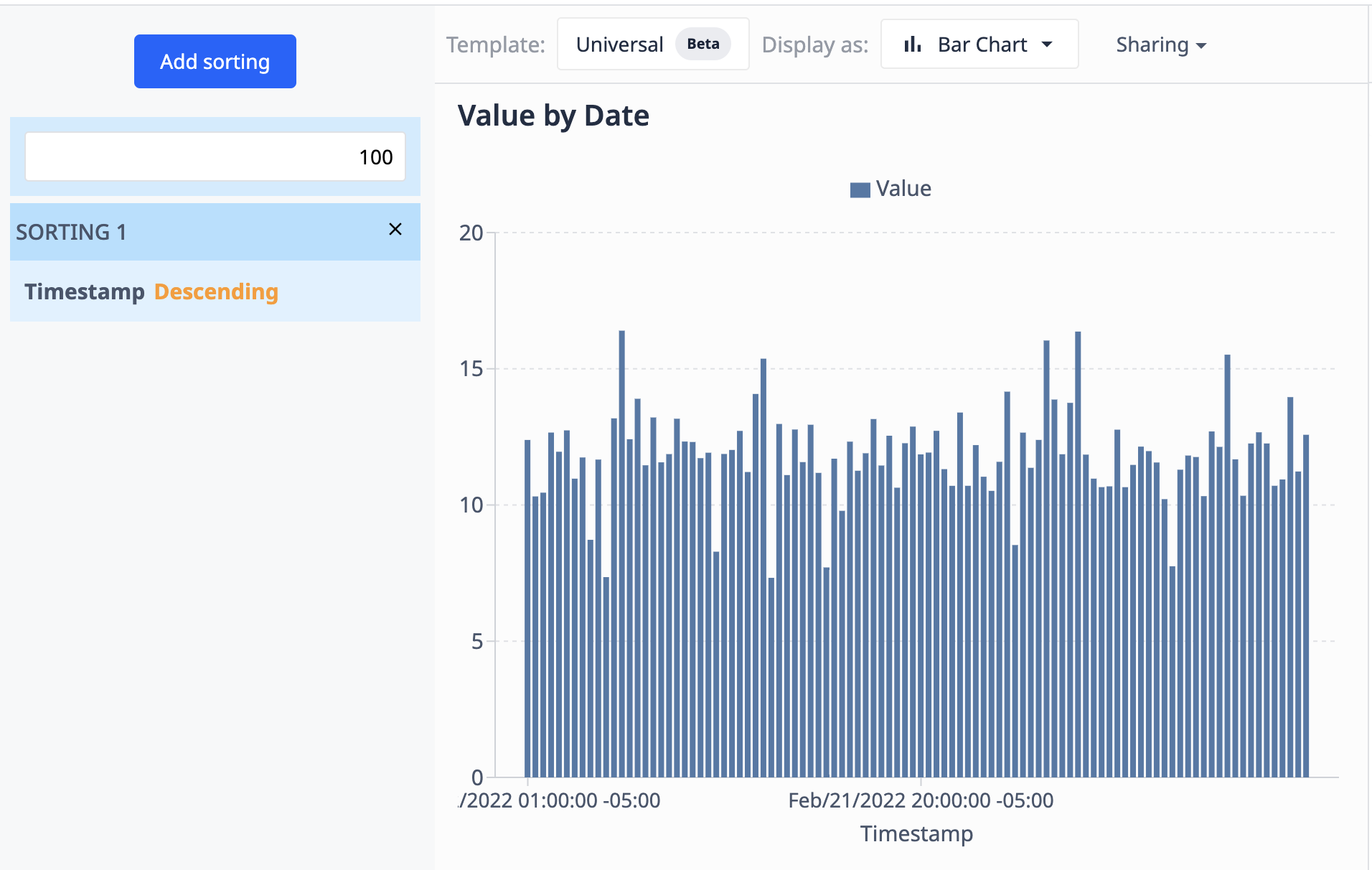
Ponieważ źródło danych (tabela) aktualizuje się o nowe rekordy, wizualizacja pokaże tylko 100 najnowszych.
Zakres dat
Zakres dat określa, jakie dane są uwzględniane w ocenie analizy. Można to porównać do filtra dla wartości datetime w zestawie danych. Zakres dat ogranicza analizę do danych, które są istotne dla określonego okresu czasu. Ze względu na wydajność zalecamy użycie najkrótszego możliwego zakresu dat dla danego przypadku użycia zamiast późniejszego dodawania dodatkowych filtrów w celu zawężenia czasu.
Następujące wartości czasu są używane dla zakresu dat dla różnych źródeł danych: * Dane ukończenia aplikacji * "Czas rozpoczęcia" ukończenia aplikacji * Data tabeli, wybierana przez użytkownika * Data utworzenia * Data aktualizacji * Dane maszyny * Czas rozpoczęcia wpisu aktywności maszyny
Filtry
Filtry definiują, które dane mają zostać uwzględnione w wyniku zapytania. Typowe przypadki użycia obejmują: * Wyświetlanie danych tylko dla określonej linii produkcyjnej * Wykluczenie określonej maszyny z analizy * Wyświetlanie tylko punktów danych o wartości wyższej niż określony próg
Filtry są konfigurowane jak warunek. Wszystkie dane spełniające warunek są uwzględniane w analizie. Przyjrzyjmy się kilku przykładom:
- Linia produkcyjna równa A
- Uwzględni wszystkie rekordy, które mają "A" w polu "Linia produkcyjna".
- Identyfikator maszyny nie jest równy "Maszyna 1"
- Uwzględni wszystkie maszyny, które nie są równe "Machine 1".
- Czas trwania testu > 55
- Uwzględni wszystkie rekordy, w których test trwał dłużej niż 55 sekund.
Filtry można definiować na dwa różne sposoby: 1. Używając wstępnie skonfigurowanych funkcji filtrowania w połączeniu z polem z danych źródłowych 2. Konfigurując wyrażenie, którego wynikiem jest wartość logiczna.
Wizualizacje
Podczas tworzenia nowej analizy przy użyciu szablonu uniwersalnego domyślnie wybierana jest wizualizacja tabeli. W dowolnym momencie można przełączyć się na inny typ wizualizacji za pomocą ustawienia Display As w górnej części ekranu. Oprócz opcji "Tabela" dostępne są następujące opcje:
- Słupek
- Linia
- Rozproszenie
- Histogram
- Pączek
- Wskaźnik
- Ramka
- Pojedyncza wartość
- Pokaz slajdów
- Pareto
Konfigurowanie wizualizacji
W przypadku większości typów wizualizacji możesz dowolnie wybrać, które pola wyniku zapytania chcesz wizualizować w jaki sposób. Odbywa się to w panelu Dane po prawej stronie edytora Analytics. Przy pierwszym przełączeniu na inną wizualizację konfiguracja jest pusta. Wizualizację można skonfigurować ręcznie w panelu Dane lub rozpocząć od sugestii, klikając przycisk Rozpocznij od sugestii na środku ekranu.
Aby móc skonfigurować wizualizację, należy spełnić następujące warunki wstępne:
- W wynikach zapytania znajdują się dane
- Dostępne są odpowiednie pola dla wizualizacji. Na przykład wykres słupkowy wymaga co najmniej jednego pola numerycznego
Jeśli oba te wymagania nie są spełnione, Edytor analityczny wyświetli komunikat ostrzegawczy.
Opcje panelu danych
Poniższa lista zawiera przegląd opcji konfiguracji dla różnych typów wizualizacji:
Bar, Line, Scatter
- Oś X
- Pole, którego wartości powinny być wyświetlane na osi X.
- Oś Y
- Jedno lub wiele pól numerycznych, których wartości powinny być wyświetlane na osi Y.
- Porównaj według
- Pole używane do wyświetlania wartości jako tej samej serii na wykresie
Jeśli chcesz wyświetlić wiele serii, możesz to zrobić, wybierając wiele pól dla osi Y lub jedno pole dla osi Y i pole Porównaj według. Łączenie wielu pól dla osi Y i porównywania według nie jest możliwe.
Tryb "Porównaj wartości pól" jest dostępny dla tych typów wizualizacji w menu "..." ustawień osi X. Umożliwia to wizualizację wartości liczbowych wielu pól obok siebie. Gdy opcja jest włączona, dostępne są następujące opcje:
- Oś X
- Pola liczbowe do porównania
- Porównaj według
- Pole używane do wyświetlania wartości jako tej samej serii na wykresie.
- Domyślnie indeks wiersza danych
Histogram
- Wartości
- Pole numeryczne zawierające wartości, dla których wyświetlany jest histogram
- To pole powinno zawierać wszystkie wartości w sposób niezagregowany. Wizualizacja zajmuje się obliczaniem wartości histogramu.
- Porównaj według
- Pole używane do dzielenia "Values" na wiele serii, z których każda jest wyświetlana jako osobny histogram w wizualizacji.
Pączek
- Wartości
- Pola numeryczne zawierające wartości do wizualizacji
- Etykiety
- Pole używane do etykietowania różnych segmentów pączków. Będą one wyświetlane w etykiecie narzędzia i legendzie.
- Domyślnie indeks wiersza wizualizowanych danych
Pojedyncza wartość, miernik
- Wartość
- Pola numeryczne zawierające wartość do wizualizacji
Uwaga: Wizualizowana będzie wartość pierwszego wiersza w wyniku zapytania. Jeśli zapytanie zwróci wiele wierszy, możesz dodać sortowanie, aby zmienić, która wartość to jest. Zalecamy użycie przycisku "Pokaż wynik zapytania" na dole, aby sprawdzić dane, jeśli nie widzisz oczekiwanej wartości w wizualizacji.
Pole
- Oś X
- Pole, którego wartości powinny być wyświetlane na osi X
- Dla każdej wartości w tym polu zostanie zwizualizowana osobna ramka.
- Oś Y
- Wyświetlane jest pole numeryczne zawierające wartości, które mają być wizualizowane na wykresie pudełkowym
- Pole to powinno zawierać wszystkie wartości w sposób niezagregowany. Wizualizacja zajmuje się obliczaniem wartości pudełka.
Pareto
- Oś X
- Pole, którego wartości powinny być wyświetlane na osi X.
- Oś Y
- Pole liczbowe, którego wartości powinny być wyświetlane na osi Y.
Skumulowana linia procentowa jest automatycznie obliczana w wizualizacji.
Przełączanie między typami wizualizacji
Podczas przełączania między dowolnymi typami wizualizacji skonfigurowanymi w panelu danych przenoszona jest dowolna zgodna konfiguracja. Minimalizuje to wysiłek związany z przełączaniem i umożliwia łatwe wypróbowanie różnych opcji wizualizacji danych.
Tabela i pokaz slajdów
Wizualizacje Table i Slideshow nie mają panelu danych i są konfigurowane automatycznie.
Tabela pokazuje wszystkie grupowania i operacje skonfigurowane w zapytaniu. Są one uporządkowane w kolejności, w jakiej pojawiają się w kreatorze zapytań po lewej stronie.
Pokaz slajdów pokazuje wszystkie obrazy, które znajdują się w dowolnym polu obrazu w wyniku zapytania jako pojedyncze slajdy. Wszelkie dodatkowe pola skonfigurowane w zapytaniu są wyświetlane w tabeli pod obrazem.
Czy znalazłeś to, czego szukałeś?
Możesz również udać się na stronę community.tulip.co, aby opublikować swoje pytanie lub sprawdzić, czy inni mieli do czynienia z podobnym pytaniem!
