

유니버설 템플릿 및 기능 환경을 최적화하는 방법에 대한 가이드입니다.
용어집.유니버설 템플릿}}은 분석을 원활하게 구축하기 위한 단일 환경입니다. 이 템플릿을 사용하면 데이터의 쿼리와 시각화를 분리하여 시각화 유형 간에 전환할 수 있습니다. 유니버설 템플릿은 모든 분석 유형과 Tulip 데이터 소스(완료, 테이블 데이터 및 기계 데이터)를 지원합니다.

쿼리 및 시각화 사용
쿼리는 앱, 머신 또는 Tulip 테이블의 '원시' 데이터로 수행하기를 원하는 작업을 시스템에 자세히 설명하는 명령과 같습니다. 쿼리 결과는 쿼리를 구성한 방식에 따라 Tulip 분석에서 생성된 데이터의 표 형식 표현입니다. 애널리틱스 에디터의 왼쪽 패널에서 쿼리를 구성합니다.
해당 쿼리의 데이터를 다양한 시각화로 시각화하여 전체 또는 선택한 일부만 표시할 수 있습니다. 시각화는 애널리틱스 에디터 상단에서 선택되며, 애널리틱스 에디터의 오른쪽 패널에서 추가로 구성할 수 있습니다.
'테이블' 시각화를 선택하지 않은 경우 쿼리 결과 표시를 클릭하면 항상 시각화 아래에서 쿼리 결과를 볼 수 있습니다.
쿼리 작성
데이터 소스
데이터 소스는 분석의 기반이 되는 데이터입니다. 앱의 완료 데이터, 테이블 데이터 또는 머신 데이터 중에서 선택할 수 있습니다.
앱 완료 데이터에 대한 분석을 작성하는 경우 여러 앱을 선택할 수 있습니다. 이렇게 하면 분석에서 선택한 모든 앱의 완료 기록을 고려하게 됩니다.
여러 앱을 선택하면 데이터가 조인되지 않고 각 완료가 별도의 행으로 처리된다는 점에 유의하세요. 즉, 완료의 '필드'(예: 사용자, 시작 시간 및 역)를 공동으로 분석할 수 있습니다. 앱 변수와 같은 다른 데이터는 각 앱마다 개별적으로 처리되며 다른 모든 앱의 완료 레코드에 대해 "null"을 값으로 사용합니다.
머신에 대한 분석을 구축하는 경우 하나 또는 여러 개의 머신 유형을 선택할 수 있습니다. 특정 머신에 대한 분석을 작성하려면 추가 필터를 추가하세요.
그룹화 및 작업
그룹화 및 작업은 쿼리 작성의 핵심 영역입니다. 여기에서 어떤 데이터 옵션을 어떤 형태로 표시할지 정의할 수 있습니다.
그룹화
그룹화는 그룹을 가능한 한 많이 결합하기 위한 지침을 제공합니다. 일반적인 QL 및 BI 도구의 GROUP BY 함수에 익숙하다면 그룹화 프로세스는 거의 동일하게 작동합니다. 그룹화는 유사한 값을 찾기 위해 데이터의 필드와 유형을 결정합니다. 이를 통해 보고자 하는 데이터를 더욱 세밀하게 볼 수 있습니다.
그룹화를 사용하면 결합할 행을 정의하는 데 더 많은 제어 기능을 제공합니다. 그룹은 모든 유형의 Field가 될 수 있습니다. 구성한 작업에 따라 하나 또는 여러 개의 그룹화를 추가하면 다른 결과를 얻을 수 있습니다.
몇 가지 그룹화 조합을 살펴보겠습니다.
| 하나의 그룹화 | 여러 그룹화 | |
|---|---|---|
| 고유한 값만 | 소스 데이터의 각 행에 대해 그룹화 필드의 값과 해당 행의 고유 값을 표시하는 행 1개 | 소스 데이터의 각 행에 대해 그룹화 필드의 값과 해당 행의 고유 값을 표시하는 행 한 개 |
| 집계만 | 그룹화 필드의 각 고유 항목에 대해 해당 그룹화 값과 해당 그룹화 값이 있는 원본 데이터의 모든 행의 집계된 값을 표시하는 행 1개 | 그룹화 필드 고유 항목의 각 조합에 대해 해당 그룹화 값과 해당 그룹화 값이 있는 소스 데이터의 모든 행의 집계 값이 있는 행 하나씩 |
| 고유 값 및 집계 | 소스 데이터의 각 행에 대해 그룹화 및 고유 값의 값과 해당 그룹화 값을 가진 소스 데이터의 모든 행의 집계된 값을 보여주는 행 하나(즉, 집계된 값은 동일한 그룹화 값을 가진 모든 행에서 동일함). | 원본 데이터의 각 행에 대해 그룹화 값과 해당 그룹화 값을 가진 원본 데이터의 모든 행의 집계된 값을 표시하는 행 하나(즉, 집계된 값이 동일한 그룹화 값을 가진 모든 행에서 동일함). |
데이터는 관련 정보가 있는 행이 존재하는 경우에만 표시된다는 점에 유의해야 합니다. 특정 날짜에 대한 소스 데이터에 데이터가 없는 경우 분석이 공백으로 표시됩니다.
그룹화가 어떻게 작동하는지 예를 들어 보겠습니다.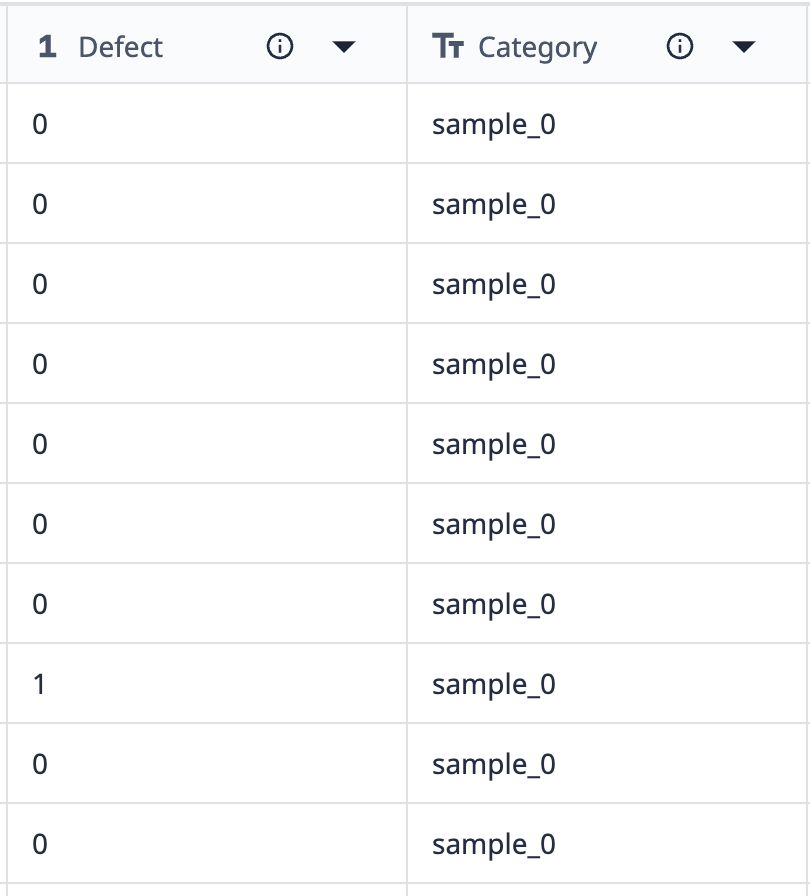
이 테이블의 데이터에는 "sample_0"이라는 레이블이 붙은 10개의 레코드가 있습니다. 샘플_0 데이터 요소 중 하나를 제외한 모든 데이터 요소에는 결함이 없습니다. 이 데이터를 결함 수가 다른 다른 샘플_0 요소만 표시하는 시각화로 그룹화하려는 경우 그룹화를 사용하여 데이터 집합처럼 결합할 수 있습니다.
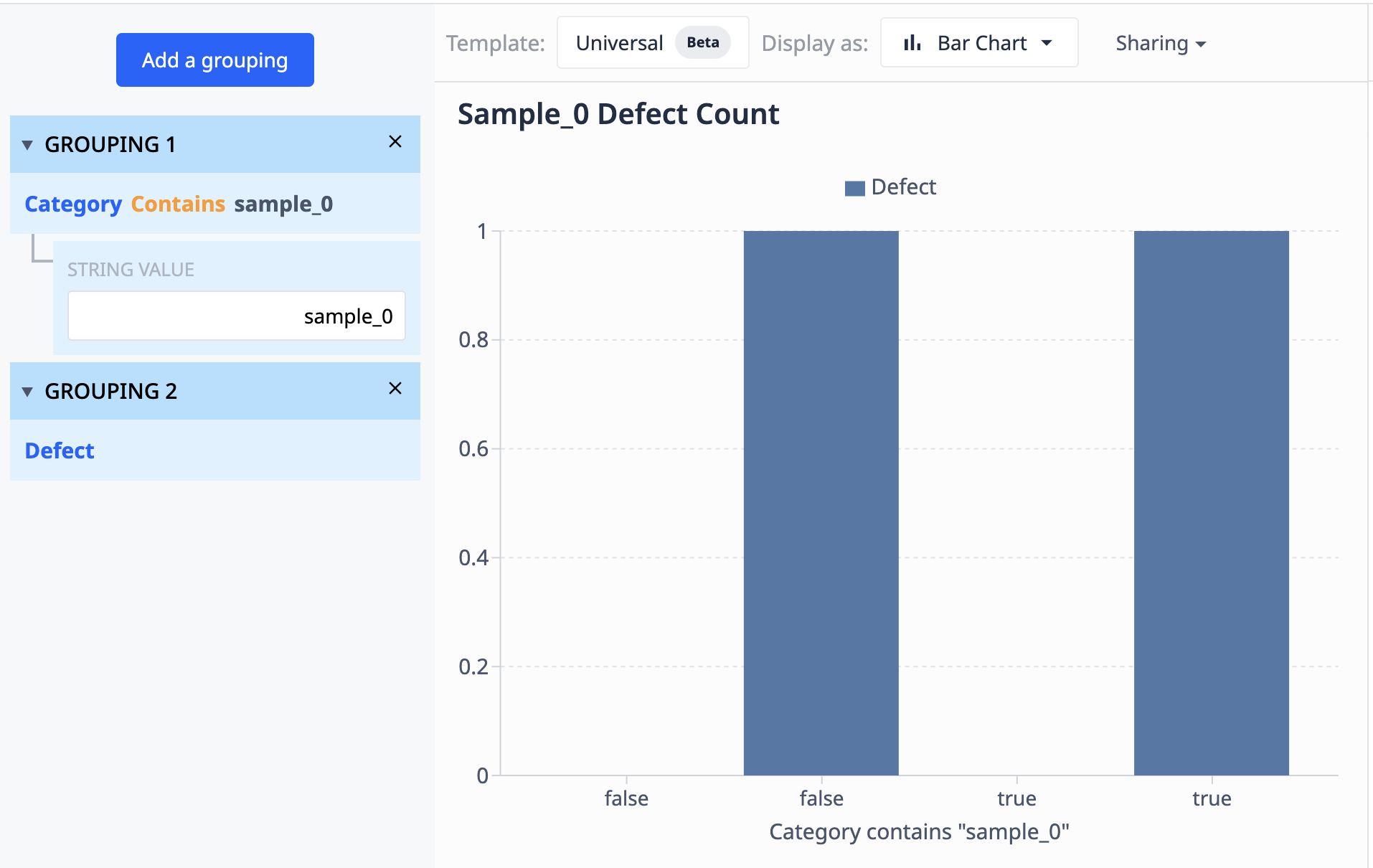
연산
연산은 단일 필드이거나 여러 레코드를 결합하는 Aggregation일 수 있습니다.
연산은 두 가지 일반적인 범주로 나뉩니다. 고유 값 고유 값은 소스 데이터의 개별 데이터 요소를 나타냅니다. 가장 간단한 경우에는 완료 레코드의 변수 값, 테이블의 필드 또는 기계 속성 중 하나입니다.
그러나 동일한 레코드의 두 필드 합계, 여러 문자열의 조합 또는 집계 함수가 포함되지 않은 표현식과 같이 보다 고급 데이터 요소일 수도 있습니다.
값 필드(숫자)와 타임스탬프 필드(날짜/시간)가 포함된 테이블을 사용하면 타임스탬프별로 값을 시각화하여 다음과 같이 표시할 수 있습니다:
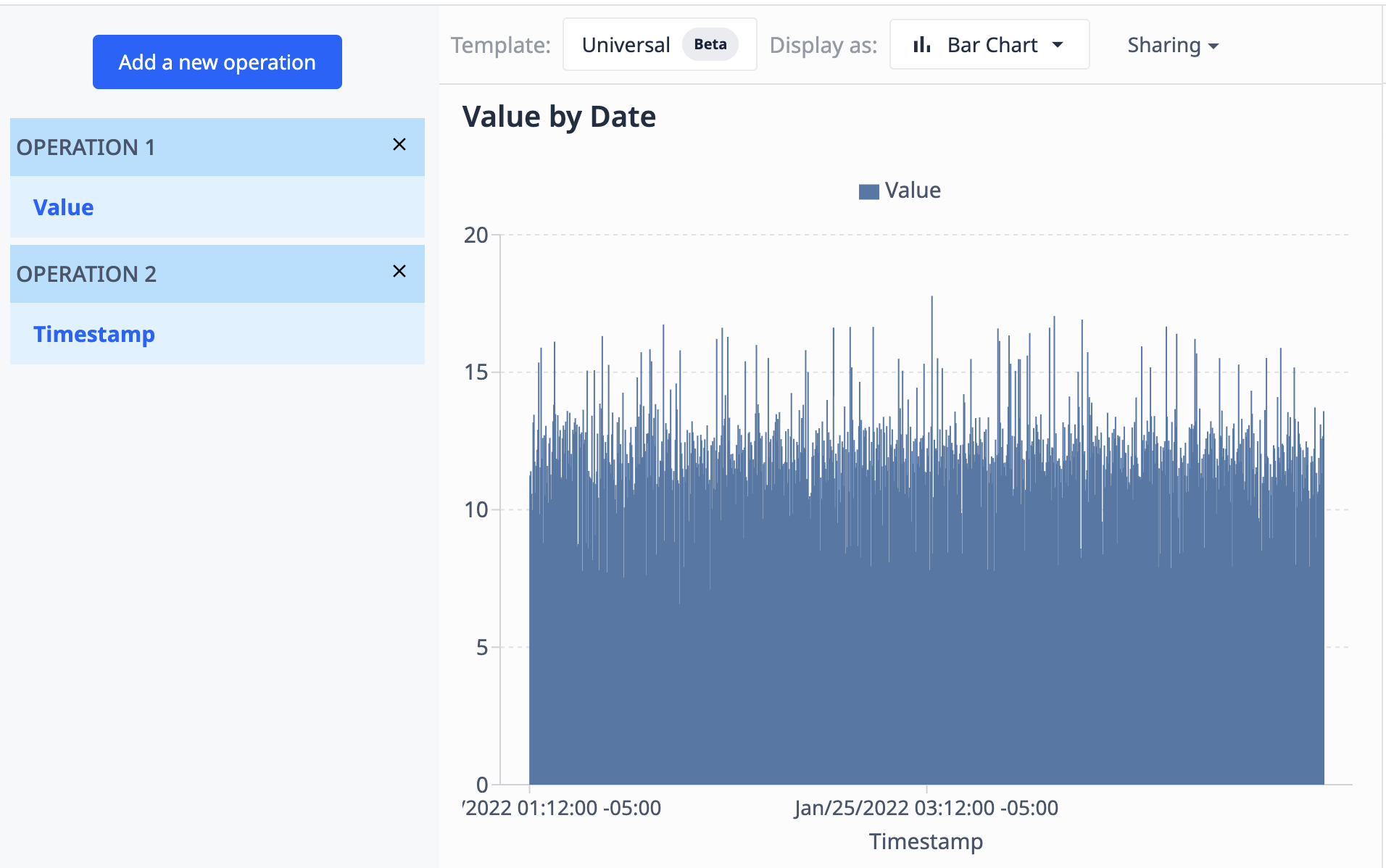
- 집계
집계는 여러 행에서 데이터를 가져와서 집합 논리에 따라 결합하는 함수입니다. 미리 구성된 선택 항목으로 사용할 수 있는 집계 함수 집합이 있거나 표현식 편집기에서 집계 함수를 사용하여 고유한 고급 집계를 작성할 수도 있습니다. 데이터 유형에 따라 서로 다른 집계 함수가 작동합니다. 아래에서 사용 가능한 함수와 지원되는 데이터 유형을 확인하세요.
직접 액세스 가능한 집계 함수이함수를 사용하면 행을 결합할 수 있습니다:
- 평균
- Median
- Sum
- 최소
- 최대
- 모드
- 표준 편차
- 95번째 백분위수
- 5번째 백분위수
- 비율
- 비율 보간
표현식 편집기에서 사용할 수 있는 집계 함수
표현식 편집기의 집계 함수는 특정 요구 사항에 따라 더 세분화된 데이터를 제공할 수 있습니다. 분석에 사용할 수 있는 모든 표현식에 대한 전체 가이드는 분석 편집기의 전체 표현식 목록을 참조하세요.
제한 및 정렬
제한을 추가하여 쿼리 결과에 포함되는 최대 행 수를 정의할 수 있습니다. 제한을 사용하면 특정 데이터에 집중하거나 차트에 표시되는 데이터의 양을 제한할 수 있습니다. 예를 들어, 지난 달에 가장 많은 결함이 발생한 생산 라인 3개를 표시하도록 제한을 추가할 수 있습니다.
정렬 데이터는 한도를 평가할 때 어떤 행을 포함할지 정의합니다. 쿼리 결과의 일부인 모든 필드에 오름차순 또는 내림차순 정렬을 추가할 수 있습니다. 정렬을 위해 여러 필드를 추가하는 경우 데이터는 첫 번째 필드를 기준으로 먼저 정렬됩니다. 그런 다음 첫 번째 필드의 각 값에 대한 결과 그룹은 두 번째 필드 등을 기준으로 정렬됩니다.
정렬을 명시적으로 정의하지 않으면 사용 가능한 데이터에 따라 쿼리 결과의 정렬이 달라질 수 있다는 점에 유의하세요. 서수 축이 있는 제한 또는 차트를 사용하는 경우 다양한 시각화가 발생할 수 있습니다. 이러한 경우 적절한 정렬을 추가하는 것이 좋습니다.
다음 예제에서는 오퍼레이션을 사용하여 본 그래프를 사용합니다. 여기에서는 결과를 100개의 데이터 요소로 제한하고 날짜 시간을 기준으로 내림차순으로 정렬합니다.
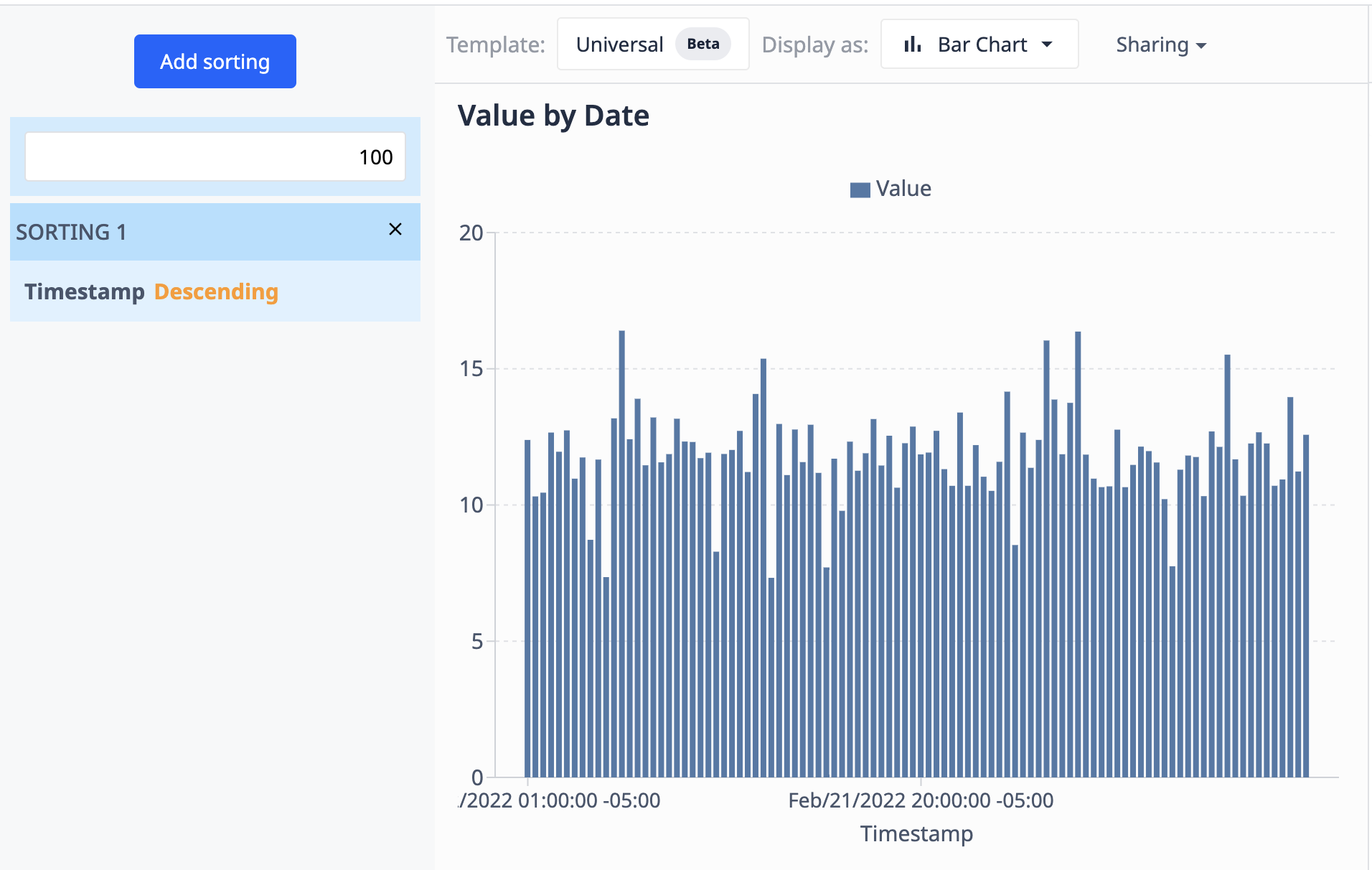
데이터 원본(테이블)이 새 레코드로 업데이트되면 비주얼리제이션에는 가장 최근의 100개 레코드만 표시됩니다.
날짜 범위
날짜 범위는 분석 평가에 포함되는 데이터를 정의합니다. 데이터 집합의 날짜/시간 값에 대한 필터라고 생각하면 됩니다. 날짜 범위는 분석을 지정된 기간과 관련된 데이터로 제한하며, 성능상의 이유로 나중에 필터를 추가하여 시간을 좁히는 대신 사용 사례에 가능한 가장 짧은 날짜 범위를 사용하는 것이 좋습니다.
다양한 데이터 소스의 날짜 범위에는 다음과 같은 날짜 시간 값이 사용됩니다. * 앱 완료 데이터 * 앱 완료의 "시작 시간" * 테이블 날짜, 사용자 선택 가능 * 생성 날짜 * 업데이트 날짜 * 머신 데이터 * 머신 활동 입력의 시작 시간
필터
필터는 쿼리 결과에 포함할 데이터를 정의하며, 일반적인 사용 사례로는* 특정 생산 라인에 대한 데이터만 표시* 분석에서 특정 기계 제외* 특정 임계값보다 높은 값을 가진 데이터 포인트만 표시 등이 있습니다.
필터는 조건처럼 구성됩니다. 조건을 충족하는 모든 데이터가 분석에 포함됩니다. 몇 가지 예를 살펴보겠습니다:
- 생산 라인이 A와 같음
- '생산 라인' 필드에 'A'가 있는 모든 레코드가 포함됩니다.
- 기계 ID가 "기계 1"과 같지 않음
- "Machine 1"과 같지 않은 모든 기계가 포함됩니다.
- 테스트 기간 > 55
- 테스트에 55초 이상 걸린 모든 레코드가 포함됩니다.
필터는 두 가지 방법으로 정의할 수 있습니다.1. 미리 구성된 필터 함수를 소스 데이터의 필드와 조합하여 사용2. 부울로 평가되는 표현식을 구성합니다.
시각화
범용 템플릿을 사용하여 새 분석을 만들면 기본적으로 테이블 시각화가 선택됩니다. 언제든지 화면 상단의 다른 이름으로 표시 설정을 사용하여 다른 시각화 유형으로 전환할 수 있습니다. "표" 외에 사용할 수 있는 옵션은 다음과 같습니다:
- 막대
- 선
- 분산형
- 히스토그램
- 도넛
- 게이지
- 박스
- 단일 값
- 슬라이드 쇼
- 파레토
시각화 구성하기
대부분의 시각화 유형에서 쿼리 결과의 어떤 필드를 어떤 방식으로 시각화할지 자유롭게 선택할 수 있습니다. 이 작업은 분석 에디터의 오른쪽에 있는 데이터 패널에서 수행합니다. 다른 시각화로 처음 전환하는 경우 구성이 비어 있습니다. 데이터 패널에서 수동으로 시각화를 설정하거나 화면 중앙의 제안으로 시작 버튼을 클릭하여 제안으로 시작할 수 있습니다.
시각화를 구성하기 위한 전제 조건은 다음과 같습니다:
- 쿼리 결과에 데이터가 있음
- 시각화에 사용할 수 있는 올바른 필드가 있습니다. 예를 들어 막대형 차트에는 숫자 필드가 하나 이상 필요합니다.
이 두 가지 요구 사항이 모두 충족되지 않으면 분석 편집기에 경고 메시지가 표시됩니다.
데이터 패널 옵션
다음 목록은 다양한 시각화 유형에 대한 구성 옵션에 대한 개요를 제공합니다:
막대, 선, 분산형
- X 축
- X축에 값이 표시되어야 하는 필드입니다.
- Y 축
- Y축에 값을 표시해야 하는 하나 이상의 숫자 필드입니다.
- 비교 기준
- 차트에서 값을 동일한 계열로 표시하는 데 사용되는 필드입니다.
여러 계열을 표시하려면 Y 축에 대해 여러 필드를 선택하거나 Y 축에 대해 하나의 필드와 비교 기준에 대해 하나의 필드를 선택하면 됩니다. Y 축 및 비교 기준에 대해 여러 필드를 결합할 수 없습니다.
X축 설정의 '...' 메뉴에서 이러한 시각화 유형에 대해 '필드 값 비교' 모드를 사용할 수 있습니다. 이 모드를 사용하면 여러 필드의 숫자 값을 나란히 시각화할 수 있습니다. 이 옵션이 켜져 있으면 다음 옵션을 사용할 수 있습니다:
- X 축
- 비교할 숫자 필드
- 비교 기준
- 차트에서 값을 동일한 계열로 표시하는 데 사용되는 필드입니다.
- 기본값은 데이터의 행 인덱스입니다.
히스토그램
- 값
- 히스토그램이 표시되는 값을 포함하는 숫자 필드입니다.
- 이 필드에는 집계되지 않은 방식으로 모든 값이 포함되어야 합니다. 시각화에서 히스토그램 값 계산을 처리합니다.
- 비교 기준
- '값'을 여러 계열로 분할하는 데 사용되는 필드로, 시각화에서 각각 별도의 히스토그램으로 표시됩니다.
도넛
- Values
- 시각화할 값이 포함된 숫자 필드입니다.
- 레이블
- 다양한 도넛 세그먼트의 레이블에 사용되는 필드입니다. 도구 설명과 범례에 표시됩니다.
- 기본값은 시각화된 데이터의 행 인덱스입니다.
단일 값, 게이지
- 값
- 시각화할 값이 포함된 숫자 필드입니다.
참고: 쿼리 결과에서 첫 번째 행의 값이 시각화됩니다. 쿼리가 여러 행을 반환하는 경우 정렬을 추가하여 어떤 값인지 변경할 수 있습니다. 시각화에서 예상한 값이 표시되지 않는 경우 하단의 '쿼리 결과 표시' 버튼을 사용하여 데이터를 확인하는 것이 좋습니다.
상자
- X 축
- X축에 값이 표시되어야 하는 필드입니다.
- 이 필드의 각 값에 대해 별도의 '상자'가 시각화됩니다.
- Y 축
- 박스형 차트에 시각화할 값을 포함하는 숫자 필드가 표시됩니다.
- 이 필드에는 집계되지 않은 방식으로 모든 값이 포함되어야 합니다. 시각화에서 박스 값 계산을 처리합니다.
파레토
- X 축
- 값이 X축에 표시되어야 하는 필드입니다.
- Y 축
- Y축에 값이 표시되어야 하는 숫자 필드입니다.
누적 백분율 선은 시각화에서 자동으로 계산됩니다.
시각화 유형 간 전환
데이터 패널에 구성된 시각화 유형 간에 전환할 때 호환되는 모든 구성이 이어집니다. 따라서 전환에 대한 수고를 최소화하고 데이터에 대한 다양한 시각화 옵션을 쉽게 시도해 볼 수 있습니다.
표 및 슬라이드쇼
표 및 슬라이드쇼 시각화에는 데이터 패널이 없으며 자동으로 구성됩니다.
이 테이블에는 쿼리에 구성된 모든 그룹화 및 작업이 표시됩니다. 왼쪽의 쿼리 작성기에 표시되는 순서대로 정렬됩니다.
슬라이드 쇼는 쿼리 결과의 이미지 필드에 있는 모든 이미지를 개별 슬라이드로 표시합니다. 쿼리에 구성된 모든 추가 필드는 이미지 아래의 표에 표시됩니다.
원하는 것을 찾았나요?
community.tulip.co로 이동하여 질문을 게시하거나 다른 사람들이 비슷한 질문을 한 적이 있는지 확인할 수도 있습니다!
.gif)