

Um guia para o Universal Template e como otimizar sua experiência com os recursos.
O Universal Template é uma experiência única para criar análises de forma integrada. Ele permite que você alterne entre os tipos de visualização, desacoplando a consulta e a visualização dos dados. O Universal Template é compatível com todos os tipos de análise e fontes de dados da Tulip (conclusões, dados de tabela e dados de máquina).

Uso de consultas e visualizações
A consulta é como uma instrução que você dá ao sistema, detalhando o que deseja que ele faça com os dados "brutos" de um aplicativo, de uma máquina ou de uma tabela Tulip. O resultado da consulta é uma representação tabular dos dados criados pelo Tulip Analytics com base em como você configurou a consulta. Você configura a consulta no painel do lado esquerdo do Analytics Editor.
Você pode visualizar os dados dessa consulta com diferentes visualizações, mostrando todos os dados ou apenas partes selecionadas deles. A visualização é selecionada na parte superior do Analytics Editor e configurada posteriormente no painel do lado direito do Analytics Editor.
Você sempre poderá ver o resultado da consulta abaixo da visualização se clicar em Show Query Result (Mostrar resultado da consulta ), a menos que tenha selecionado a visualização "Table" (Tabela).
Criação de consultas
Fonte de dados
Uma fonte de dados é o que serve de base para a análise. Você pode escolher entre dados de conclusão de um aplicativo, dados de tabela ou dados de máquina.
Se estiver criando uma análise para dados de conclusão do aplicativo, você poderá selecionar vários aplicativos. Isso fará com que a análise considere os registros de conclusão de todos os aplicativos selecionados.
Observe que, se vários aplicativos forem selecionados, os dados não serão unidos, mas cada conclusão será tratada como uma linha separada. Isso significa que você poderá analisar conjuntamente os "Campos" das conclusões (por exemplo, Usuário, Hora de início e Estação). Outros dados, como App Variables, serão tratados separadamente para cada aplicativo e terão "null" como valor para os registros de conclusão de todos os outros aplicativos.
Se estiver criando uma análise para máquinas, você poderá selecionar um ou vários tipos de máquinas. Se você quiser criar uma análise para uma máquina específica, adicione um filtro adicional.
Agrupamentos e operações
Os agrupamentos e as operações são as áreas centrais da criação de sua consulta. É aqui que você define quais opções de dados deseja mostrar e de que forma.
Agrupamentos
Os agrupamentos fornecem uma instrução para combinar os grupos o máximo possível. Se você estiver familiarizado com a função GROUP BY em ferramentas comuns de QL e BI, o processo de agrupamento se comporta de forma quase idêntica. Os agrupamentos determinam os campos e tipos de dados para encontrar valores semelhantes. Eles permitem que você obtenha uma visão cada vez mais granular dos dados que deseja ver.
Os agrupamentos oferecem mais controle para definir quais linhas devem ser combinadas. Um agrupamento pode ser qualquer campo de qualquer tipo. Dependendo das operações que você configurou, adicionar um ou vários agrupamentos levará a resultados diferentes.
Vamos examinar algumas combinações de agrupamento.
| Um agrupamento | Vários agrupamentos | | --- | --- | --- | Uma linha para cada linha nos dados de origem mostrando os valores para o campo de agrupamento e os valores distintos para essa linha | Uma linha para cada linha nos dados de origem mostrando os valores para os campos de agrupamento e os valores distintos para essa linha | | Only Distinct Values | Uma linha para cada entrada distinta no campo de agrupamento com esse valor para o agrupamento e os valores agregados de todas as linhas dos dados de origem com esse valor de agrupamento Uma linha para cada combinação das entradas distintas dos campos de agrupamento com os respectivos valores para os agrupamentos e os valores agregados de todas as linhas dos dados de origem com os respectivos valores de agrupamento | | Valores distintos e agregações | Uma linha para cada linha nos dados de origem mostrando os valores dos agrupamentos e os valores distintos e os valores agregados de todas as linhas dos dados de origem com esse valor de agrupamento (ou seja, os valores agregados são os valores de agrupamento).Ou seja, os valores agregados são os mesmos em todas as linhas com o mesmo valor de agrupamento) | Uma linha para cada linha nos dados de origem mostrando os valores dos agrupamentos e os valores agregados de todas as linhas dos dados de origem com os respectivos valores de agrupamento (ou seja, os valores agregados são os mesmos em todas as linhas com os mesmos valores de agrupamento)
É importante observar que os dados só serão mostrados se houver uma linha com qualquer informação relevante. Se não houver dados nos dados de origem para um dia específico, a análise aparecerá em branco.
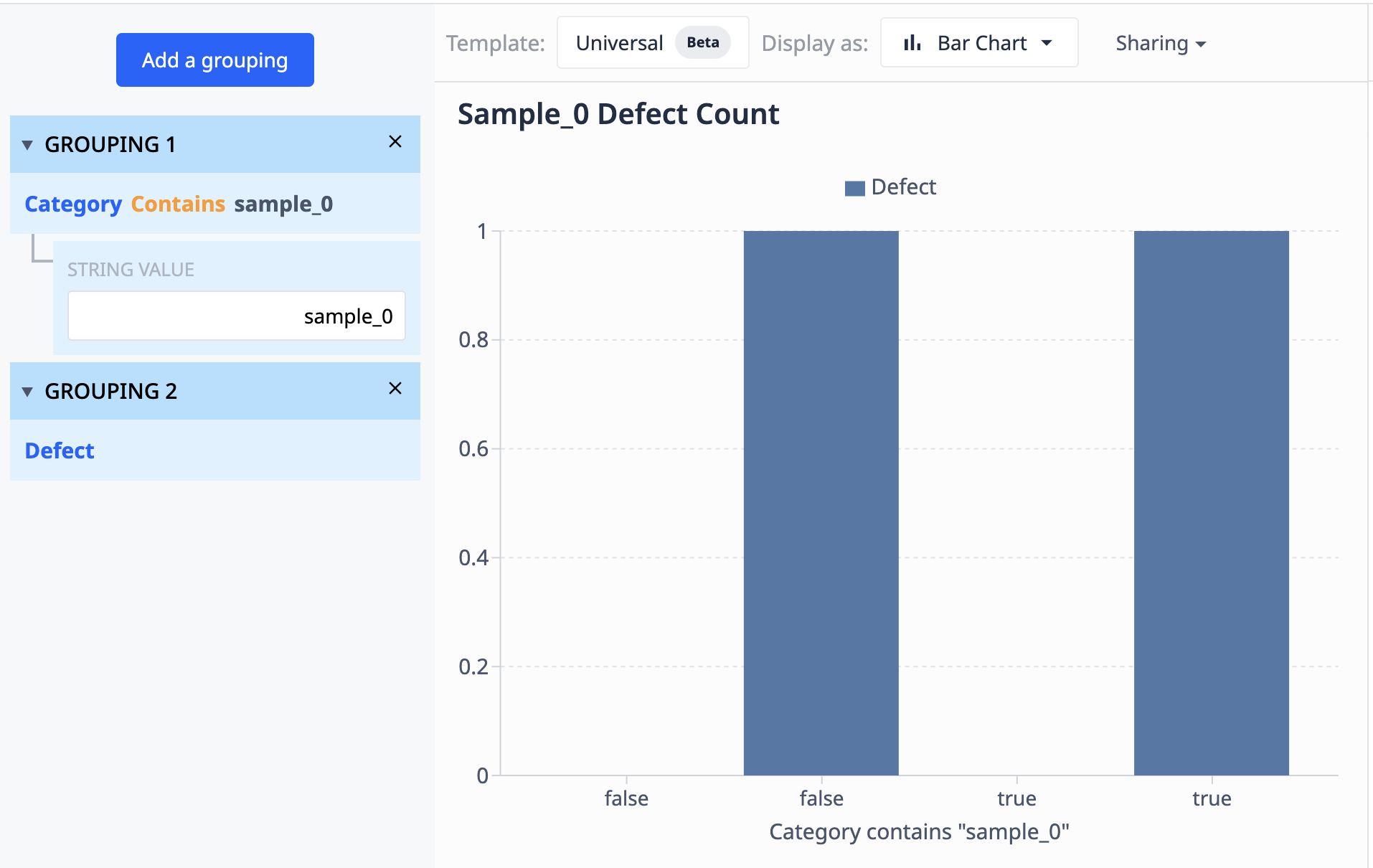
Vamos dar uma olhada em um exemplo de como os agrupamentos funcionam: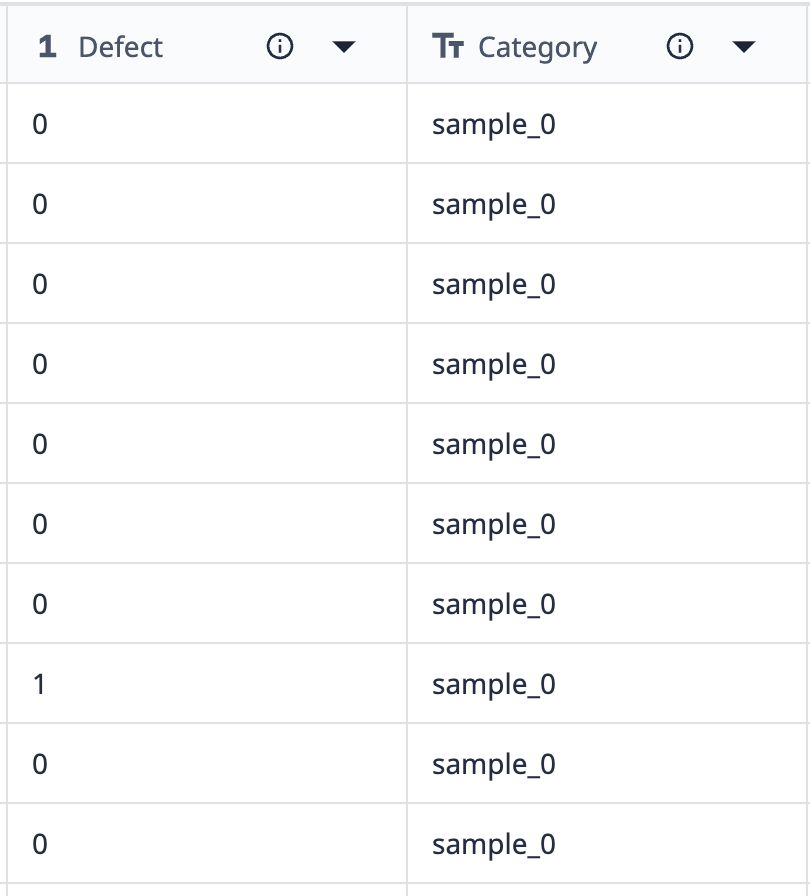
Os dados dessa tabela mostram que há 10 registros rotulados como "sample_0". Se quisermos agrupar esses dados em uma visualização que mostre apenas pontos sample_0 diferentes em que a contagem de defeitos seja diferente, poderemos usar agrupamentos para combinar conjuntos de dados semelhantes.
Operações
As operações podem ser uma agregação que combina vários registros ou um campo, o que não é o caso.
As operações são divididas em duas categorias gerais: 1. Valores distintos Os valores distintos representam pontos de dados individuais de seus dados de origem. No caso mais simples, trata-se de um valor de uma variável de um registro de conclusão, um campo de uma tabela ou um atributo de máquina.
Mas também pode ser um ponto de dados mais avançado, como a soma de dois campos do mesmo registro, uma combinação de várias cadeias de caracteres ou uma expressão que não inclua uma função de agregação.
Usando uma tabela que contém um campo de valores (numérico) e um campo de registros de data e hora (datetime), podemos visualizar os valores por registro de data e hora para que apareçam como tal:
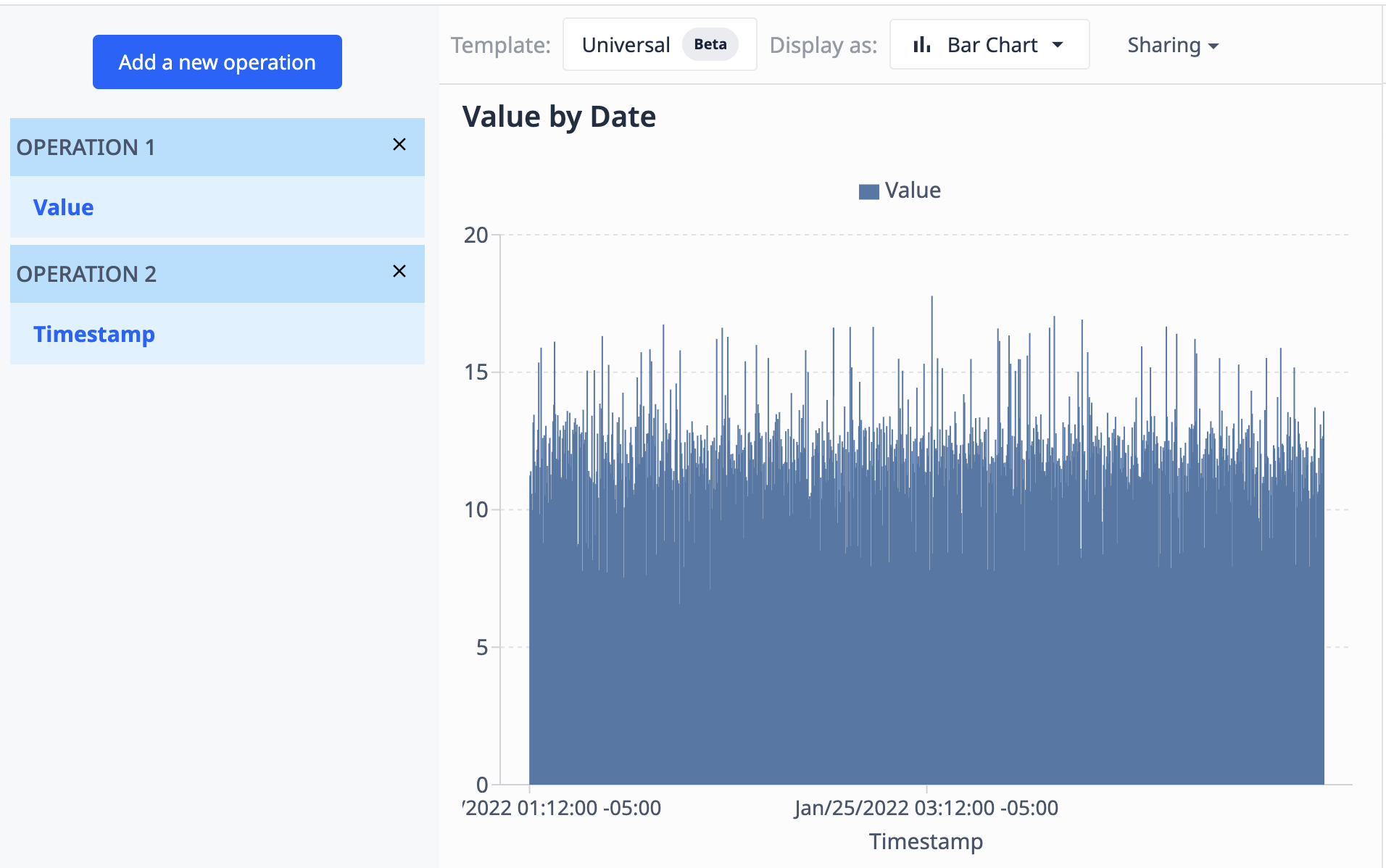
- Agregações
Agregações são funções que obtêm dados de várias linhas e os combinam com base em uma lógica de conjunto. Há um conjunto de funções de agregação disponíveis como seleções pré-configuradas, ou você também pode usar funções de agregação no editor de expressões para criar suas próprias agregações avançadas. Diferentes funções de agregação funcionam para diferentes tipos de dados. Veja abaixo quais funções estão disponíveis e quais tipos de dados são compatíveis.
Funções de agregação diretamente acessíveisPermitem a combinação de linhas:
- Média
- Mediana
- Soma
- Mínimo
- Máximo
- Modo
- Desvio padrão
- Percentil 95
- Percentil 5
- Proporção
- Complemento da proporção
Funções de agregação disponíveis no Editor de expressões
As funções de agregação no editor de expressões podem fornecer dados mais granulares com base em seus requisitos específicos. Para obter um guia completo de todas as expressões disponíveis que podem ser usadas em suas análises, consulte Lista completa de expressões no Analytics Editor.
Limite e classificação
Você pode definir o número máximo de linhas que o resultado da consulta contém adicionando um limite. Com os limites, você pode se concentrar em dados específicos ou limitar a quantidade de dados mostrados em um gráfico. Por exemplo, você pode adicionar um limite para mostrar as três linhas de produção que apresentaram o maior número de defeitos no último mês.
Os dados de classificação definem quais linhas são incluídas ao avaliar o limite. Você pode adicionar uma classificação ascendente ou descendente para qualquer campo que faça parte do resultado da consulta. Se você adicionar vários campos para classificação, os dados serão classificados primeiro pelo primeiro. Os grupos resultantes para cada valor do primeiro campo serão classificados pelo segundo etc.
Observe que, se você não definir a classificação explicitamente, a classificação do resultado da consulta poderá variar de acordo com os dados disponíveis. Ao usar limitadores ou gráficos com eixos ordinais, isso pode levar a visualizações diferentes. Recomendamos adicionar uma classificação apropriada nesses casos.
O exemplo a seguir usa o gráfico que vimos usando Operations. Aqui, limitamos os resultados a 100 pontos de dados e os classificamos em ordem decrescente com base em sua data e hora.
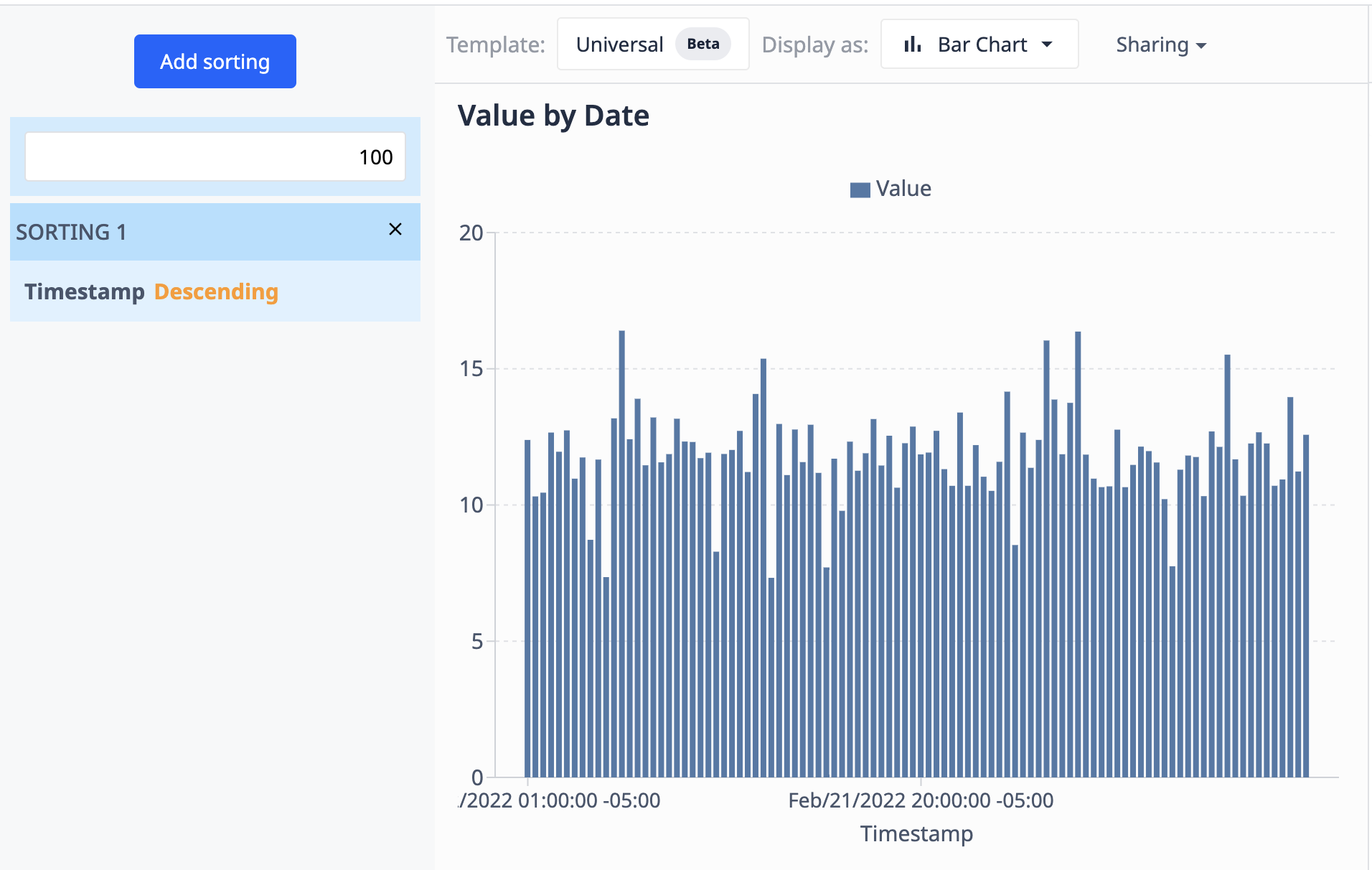
Como a fonte de dados (a tabela) é atualizada com novos registros, a visualização mostrará apenas os 100 mais recentes.
Intervalo de datas
O intervalo de datas define quais dados são incluídos na avaliação da análise. Pense nisso como um filtro para um valor de data e hora no conjunto de dados. Por motivos de desempenho, recomendamos usar o menor intervalo de datas possível para o seu caso de uso, em vez de acrescentar filtros adicionais posteriormente para restringir o tempo.
Os seguintes valores de data e hora são usados para o intervalo de datas das várias fontes de dados: * Dados de conclusão do aplicativo * "Hora de início" da conclusão do aplicativo * Data da tabela, selecionável pelo usuário * Data de criação * Data de atualização * Dados da máquina * Hora de início da entrada de atividade da máquina
Filtros
Os filtros definem quais dados devem ser incluídos no resultado da consulta. Os casos de uso típicos incluem: * Mostrar dados apenas para uma linha de produção específica * Excluir uma máquina específica de uma análise * Mostrar apenas pontos de dados com um valor maior que um limite específico
Os filtros são configurados como uma condição. Todos os dados que atendem à condição são incluídos na análise. Vamos dar uma olhada em alguns exemplos:
- Linha de produção igual a A
- Incluirá todos os registros que tenham "A" no campo "Production Line".
- ID da máquina não é igual a "Máquina 1"
- Incluirá todas as máquinas que não sejam iguais a "Machine 1"
- Duração do teste > 55
- Incluirá todos os registros em que o teste durou mais de 55 segundos
Os filtros podem ser definidos de duas maneiras diferentes: 1. Usando as funções de filtro pré-configuradas em combinação com um campo de seus dados de origem. 2. Configurando uma expressão que seja avaliada como booleana.
Visualizações
Quando uma nova análise é criada usando o Modelo Universal, a visualização de Tabela é selecionada por padrão. Você pode, a qualquer momento, mudar para um tipo de visualização diferente usando a configuração Exibir como na parte superior da tela. As opções além de "Tabela" são:
- Barra
- Linha
- Dispersão
- Histograma
- Donut
- Medidor
- Caixa
- Valor único
- Apresentação de slides
- Pareto
Configuração de uma visualização
Para a maioria dos tipos de visualização, você pode selecionar livremente quais campos do resultado da consulta deseja visualizar de que maneira. Isso é feito no painel Data (Dados ) no lado direito do Analytics Editor. Ao mudar para uma visualização diferente pela primeira vez, a configuração fica vazia. Você pode configurar sua visualização manualmente no painel Dados ou começar com uma sugestão clicando no botão Iniciar com sugestão no centro da tela.
Os pré-requisitos para poder configurar uma visualização são:
- Há dados no resultado da consulta
- Você tem os campos certos disponíveis para a visualização. Por exemplo, um gráfico de barras requer pelo menos um campo numérico
Se esses dois requisitos não forem atendidos, o Analytics Editor mostrará uma mensagem de aviso.
Opções do painel de dados
A lista a seguir apresenta uma visão geral das opções de configuração para os diferentes tipos de visualização:
Barra, Linha, Dispersão
- Eixo X
- O campo cujos valores devem ser mostrados no eixo X
- Eixo Y
- Um ou vários campos numéricos cujos valores devem ser mostrados no eixo Y.
- Comparar por
- O campo usado para mostrar valores como a mesma série no gráfico
Se quiser mostrar várias séries, você pode fazer isso selecionando vários campos para o eixo Y ou um campo para o eixo Y e um campo para Compare By. Não é possível combinar vários campos para o eixo Y e comparar por.
Um modo "Comparar valores de campo" está disponível para esses tipos de visualização no menu "..." da configuração do eixo X. Isso permite visualizar valores numéricos de vários campos lado a lado. Quando a opção está ativada, as seguintes opções estão disponíveis:
- Eixo X
- Os campos numéricos a serem comparados
- Comparar por
- O campo usado para mostrar valores como a mesma série no gráfico
- O padrão é o índice de linha dos dados
Histograma
- Valores
- O campo numérico que contém os valores para os quais o histograma é mostrado
- Esse campo deve conter todos os valores de forma não agregada. A visualização se encarrega de calcular os valores do histograma.
- Comparar por
- O campo usado para dividir os "Valores" em várias séries, cada uma mostrada como um histograma separado na visualização
Donut
- Valores
- Os campos numéricos que contêm os valores a serem visualizados
- Rótulos
- O campo usado para os rótulos dos diferentes segmentos de rosca. Eles serão exibidos na dica de ferramenta e na legenda
- O padrão é o índice de linha dos dados visualizados
Valor único, medidor
- Valor
- Os campos numéricos que contêm o valor a ser visualizado
Observação: O valor da primeira linha no resultado da consulta será visualizado. Se a sua consulta retornar várias linhas, você poderá adicionar classificação para alterar qual valor é esse. Recomendamos usar o botão "Show query result" (Mostrar resultado da consulta) na parte inferior para verificar os dados se você não vir o valor esperado na visualização.
Caixa
- Eixo X
- O campo cujos valores devem ser mostrados no eixo X
- Uma "caixa" separada será visualizada para cada valor nesse campo
- Eixo Y
- É mostrado o campo numérico que contém os valores a serem visualizados no gráfico de caixa
- Esse campo deve conter todos os valores de forma não agregada. A visualização se encarrega de calcular os valores da caixa.
Pareto
- Eixo X
- O campo cujos valores devem ser mostrados no eixo X
- Eixo Y
- O campo numérico cujos valores devem ser mostrados no eixo Y.
A linha de porcentagem cumulativa é calculada automaticamente na visualização.
Alternância entre tipos de visualização
Ao alternar entre qualquer um dos tipos de visualização configurados no painel de dados, qualquer configuração compatível é transferida. Isso minimiza o esforço de alternância e permite que você experimente facilmente diferentes opções de visualização para seus dados.
Tabela e apresentação de slides
As visualizações de tabela e apresentação de slides não têm um painel de dados e são configuradas automaticamente.
Essa tabela mostra todos os agrupamentos e operações configurados na consulta. Eles são ordenados na sequência em que aparecem no construtor de consultas à esquerda.
A Apresentação de slides mostra todas as imagens que estão em qualquer campo de imagem no resultado da consulta como slides individuais. Todos os campos adicionais configurados na consulta são mostrados em uma tabela abaixo da imagem.
Encontrou o que estava procurando?
Você também pode acessar community.tulip.co para postar sua pergunta ou ver se outras pessoas tiveram uma pergunta semelhante!
